魚羊 發自 凹非寺
量子位 報道 | 公衆號 QbitAI
Transformer自誕生以來,就在NLP領域刷新一個又一個紀錄,稱作當下最流行的深度學習框架亦不爲過。
不過,拿下SOTA並不意味著十全十美。
比如,在長序列訓練上,Transformer就存在計算量巨大、訓練成本高的問題。
其對內存的要求從GB級別到TB級別不等。這意味著,模型只能處理簡短的文本,生成簡短的音樂。
此外,許多大型Transformer模型在經過模型並行訓練之後,無法在單個GPU上進行微調。
現在,谷歌和UC伯克利推出了一個更高效的Transformer模型——Reformer。
在長度爲L的序列上,將複雜度從 O(L2)降低到了O(L logL)。
並且,模型訓練後,可以僅使用16GB內存的單個GPU運行。

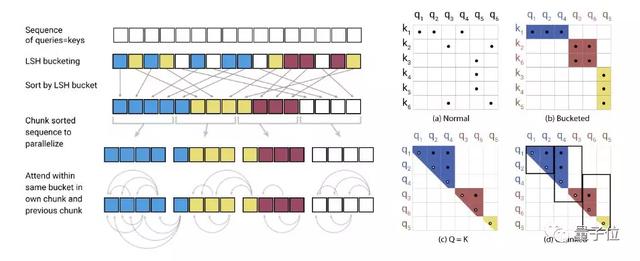
其中,Q矩陣由一組query的注意力函數組成,key打包爲矩陣K,value打包爲矩陣V,dk爲query和key的維度。
在softmax(QKT)中,softmax受最大元素控制,因此對于每個query(qi),只需要關注K中最接近qi的key。這樣效率會高得多。
那麽如何在key中尋找最近鄰居呢?
局部敏感哈希就可以解決在高維空間中快速找到最近鄰居的問題。
局部敏感哈希指的是,如果鄰近的向量很可能獲得相同的哈希值,而遠距離的向量沒可能,則給每個向量x分配哈希值h(x)。
在這項研究中,實際上僅需要求鄰近向量以高概率獲得相同的哈希,並且哈希桶的大小高概率相似。
于是,研究人員引入了可逆層和分段處理,來進一步降低成本。

可逆Transformer無需在每個層中存儲activations。
這樣一來,整個網絡中activations占用的內存就與層數無關了。
實驗結果
研究人員在enwik8和imagenet64數據集上對20層的Reformer模型進行了訓練。
實驗表明,Reformer能達到與Transformer相同的性能,並且內存效率更高,模型在長序列任務上訓練更快。