ClickHouse 是由號稱“俄羅斯 Google”的 Yandex 公司開源的面向 OLAP 的分布式列式數據庫,能夠使用 SQL 查詢生成實時數據報告。
本文整理自字節跳動高級研發工程師陳星在 QCon 全球軟件開發大會(北京站)2019 上的演講,他介紹了 ClickHouse 的關鍵技術點、在字節跳動的應用場景以及主要的技術改進。
ClickHouse 簡介
ClickHouse 是由號稱“俄羅斯 Google”的 Yandex 開發而來,在 2016 年開源,在計算引擎裏算是一個後起之秀,在內存數據庫領域號稱是最快的。大家從網上也能夠看到,它有幾倍于 GreenPlum 等引擎的性能優勢。
如果大家研究過它的源碼,會發現其實它采用的技術並不新。ClickHouse 是一個列導向數據庫,是原生的向量化執行引擎。它在大數據領域沒有走 Hadoop 生態,而是采用 Local attached storage 作爲存儲,這樣整個 IO 可能就沒有 Hadoop 那一套的局限。它的系統在生産環境中可以應用到比較大的規模,因爲它的線性擴展能力和可靠性保障能夠原生支持 shard + replication 這種解決方案。它還提供了一些 SQL 直接接口,有比較豐富的原生 client。另外就是它比較快。
大家選擇 ClickHouse 的首要原因是它比較快,但其實它的技術沒有什麽新的地方,爲什麽會快?我認爲主要有三個方面的因素:
- 它的數據剪枝能力比較強,分區剪枝在執行層,而存儲格式用局部數據表示,就可以更細粒度地做一些數據的剪枝。它的引擎在實際使用中應用了一種現在比較流行的 LSM 方式。
- 它對整個資源的垂直整合能力做得比較好,並發 MPP+ SMP 這種執行方式可以很充分地利用機器的集成資源。它的實現又做了很多性能相關的優化,它的一個簡單的彙聚操作有很多不同的版本,會根據不同 Key 的組合方式有不同的實現。對于高級的計算指令,數據解壓時,它也有少量使用。
- 我當時選擇它的一個原因,ClickHouse 是一套完全由 C++ 模板 Code 寫出來的實現,代碼還是比較優雅的。
字節跳動如何使用 ClickHouse
頭條做技術選型的時候爲什麽會選用 ClickHouse?這可能跟我們的應用場景有關,下面簡單介紹一下 ClickHouse 在頭條的使用場景。
頭條內部第一個使用 ClickHouse 的是用戶行爲分析系統。該系統在使用 ClickHouse 之前,engine 層已經有兩個叠代。他們嘗試過 Spark 全內存方案還有一些其他的方案,都存在很多問題。主要因爲産品需要比較強的交互能力,頁面拖拽的方式能夠給分析師展示不同的指標,查詢模式比較多變,並且有一些查詢的 DSL 描述,也不好用現成的 SQL 去表示,這就需要 engine 有比較好的定制能力。
行爲分析系統的表可以打成一個大的寬表形式,join 的形式相對少一點。系統的數據量比較大,因爲産品要支持頭條所有 APP 的用戶行爲分析,包含頭條全量和抖音全量數據,用戶的上報日志分析,面臨不少技術挑戰。大家做了一些調研之後,在用 ClickHouse 做一些簡單的 POC 工作,我就拿著 ClickHouse 按需求開始定制了。
綜合來看,從 ClickHouse 的性能、功能和産品質量來說,效果還不錯,因爲開發 ClickHouse 的公司使用的場景實際上跟頭條用戶分析是比較類似的,因此有一定的借鑒意義。
目前頭條 ClickHouse 集群的規模大概有幾千個節點,最大的集群規模可能有 1200 個節點,這是一個單集群的最大集群節點數。數據總量大概是幾十個 PB,日增數據 100TB,落地到 ClickHouse,日增數據總量大概是它的 3 倍,原始數據也就 300T 左右,大多數查詢的響應時間是在幾秒鍾。從交互式的用戶體驗來說,一般希望把所有的響應控制在 30 秒之內返回,ClickHouse 基本上能夠滿足大部分要求。覆蓋的用戶場景包括産品分析師做精細化運營,開發人員定位問題,也有少量的廣告類客戶。
圖 1 是一個 API 的框架圖,相當于一個統一的指標出口,也提供服務。圍繞著 ClickHouse 集群,它可以支撐不同的數據源,包括離線的數據、實時的消息中間件數據,也有些業務的數據,還有少量高級用戶會直接從 Flink 上消費一些 Databus 數據,然後批量寫入,之後在它外圍提供一個數據 ETL 的 Service,定期把數據遷移到 ClickHouse local storage 上,之後他們在這之上架了一個用戶使用分析系統,也有自研的 BI 系統做一些多維分析和數據可視化的工作,也提供 SQL 的網關,做一些統一指標出口之類的工作,上面的用戶可能是多樣的。
綜合來說,我們希望在頭條內部把 ClickHouse 打造成爲支持數據中台的查詢引擎,滿足交互式行爲的需求分析,能夠支持多種數據源,整個數據鏈路對業務做到透明。在工作過程中,我們也碰到了很多的問題。
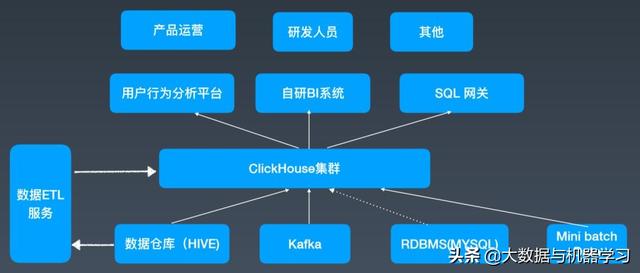
圖 2 ClickHouse 服務化與自動化中的問題
Map 數據類型:動態 Schema
我們在做整個框架的過程中發現,有時候産品存在動態 Schema 的需求。我們當時增加了 Map 的數據類型,主要解決的問題是産品支持的 APP 很多,上報的 Model 也是多變的,它跟用戶的日志定義有關,有很多用戶自定義參數,就相當于動態的 Schema。從數據産品設計的角度來看又需要相對固定的 Schema,二者之間就會存在一定的鴻溝。最終我們是通過 Map 類型來解決的。
實現 Map 的方式比較多,最簡單的就是像 LOB 的方式,或者像 Two-implicit column 的方式。當時産品要求訪問 Map 單鍵的速度與普通的 column 速度保持一致,那麽比較通用的解決方案不一定能夠滿足我們的要求。當時做的時候,從數據的特征來看,我們發現雖然叫 Map,但是它的 keys 總量是有限的,因爲依賴于用戶自定義的參數不會特別多,在一定的時間範圍內,Keys 數量會是比較固定的。而 ClickHouse 有一個好處:它的數據在局部是自描述的,Part 之間的數據差異自動能夠 Cover 住。
最後我們采用了一個比較簡單的展平模型,在我們數據寫入過程中,它會做一個局部打平。以圖 3 爲例,表格中兩行總共只有三個 key,我們就會在存儲層展開這三列。這三列的描述是在局部描述的,有值的用值填充,沒有值就直接用 N 填充。現在 Map 類型在頭條 ClickHouse 集群的各種服務上都在使用,基本能滿足大多數的需求。

圖 4 Map 數據類型 – 動態 Schema 相關語法
大數據量和高可用
不知道大家在使用 ClickHouse 的過程中有沒有一個體會,它的高可用方案在大的數據量下可能會有點問題。主要是 zookeeper 的使用方式可能不是很合理,也就是說它原生的 Replication 方案有太多的信息存在 ZK 上,而爲了保證服務,一般會有一個或者幾個副本,在頭條內部主要是兩個副本的方案。
我們當時有一個 400 個節點的集群,還只有半年的數據。突然有一天我們發現服務特別不穩定,ZK 的響應經常超時,table 可能變成只讀模式,發現它 znode 的太多。而且 ZK 並不是 Scalable 的框架,按照當時的數據預估,整個服務很快就會不可用了。
我們分析後得出結論,實際上 ClickHouse 把 ZK 當成了三種服務的結合,而不僅把它當作一個 Coordinate service,可能這也是大家使用 ZK 的常用用法。ClickHouse 還會把它當作 Log Service,很多行爲日志等數字的信息也會存在 ZK 上;還會作爲表的 catalog service,像表的一些 schema 信息也會在 ZK 上做校驗,這就會導致 ZK 上接入的數量與數據總量會成線性關系。按照這樣的數據增長預估,ClickHouse 可能就根本無法支撐頭條抖音的全量需求。
社區肯定也意識到了這個問題,他們提出了一個 mini checksum 方案,但是這並沒有徹底解決 znode 與數據量成線性關系的問題。所以我們就基于 MergeTree 存儲引擎開發了一套自己的高可用方案。我們的想法很簡單,就是把更多 ZK 上的信息卸載下來,ZK 只作爲 coordinate Service。只讓它做三件簡單的事情:行爲日志的 Sequence Number 分配、Block ID 的分配和數據的元信息,這樣就能保證數據和行爲在全局內是唯一的。
關于節點,它維護自身的數據信息和行爲日志信息,Log 和數據的信息在一個 shard 內部的副本之間,通過 Gossip 協議進行交互。我們保留了原生的 multi-master 寫入特性,這樣多個副本都是可以寫的,好處就是能夠簡化數據導入。圖 6 是一個簡單的框架圖。
以這個圖爲例,如果往 Replica 1 上寫,它會從 ZK 上獲得一個 ID,就是 Log ID,然後把這些行爲和 Log Push 到集群內部 shard 內部活著的副本上去,然後當其他副本收到這些信息之後,它會主動去 Pull 數據,實現數據的最終一致性。我們現在所有集群加起來 znode 數不超過三百萬,服務的高可用基本上得到了保障,壓力也不會隨著數據增加而增加。
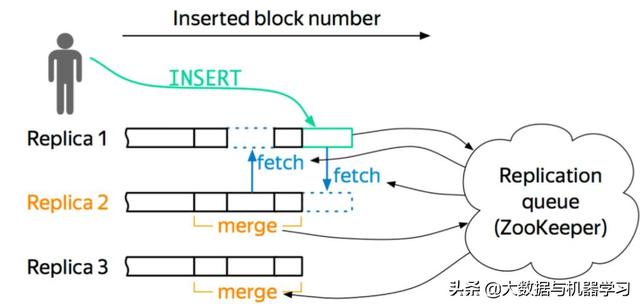
圖 6 HaMergeTree 簡單框架
解決了以上幾個問題之後,我們還在對 ClickHouse 做持續改進。我們最近也碰到了一些 Log 調度之類的問題,當時我們對 Log 調度並沒有做特別的優化,實際上還是用 ClickHouse 的原生調度,在有些集群上可能會碰到一些問題,比如有些表的 Log 調度延遲會比較高一點,我們現在也正在嘗試解決。
String 類型處理效率:Global Dictionary
另外,爲了滿足交互式的需求,在相當長的一段時間我們都在思考怎麽提高數據執行的性能。大家在做數倉或者做大數據場景的時候會發現,用戶特別喜歡字符串類型,但是你如果做執行引擎執行層,就特別不喜歡處理這類 String 類型的數據,因爲它是變長的,存在執行上有較高代價。String 類型的處理效率,跟數字類型的處理效率有 10 倍的差距,所以我們做了一個全局字典壓縮的解決方案,目的並不是爲了節省存儲空間,而是爲了提高執行的效率,這是相當重要一個出發點。我們希望把一些常見的算子盡量在壓縮域上執行,不需要做數據的解壓。
目前我們只做了一個 pure dictionary compression,支持的算子也比較少,比如 predication 支持等值比較或者 in 等類似的比較能夠在壓縮域上直接執行,這已經能夠覆蓋我們很多的場景,像 group by 操作也能夠在壓縮域上做。
說到 Global Dictionary,其實也並不是完全的 Global ,每個節點有自己的 Dictionary,但是在一個集群內部,各個節點之前的字典可能是不一樣的。爲什麽沒有做全局在集群內部做一個字典?
第一,全局字典會把 coordinate 協議搞得特別複雜,我以前做數據庫的時候有個項目,采用了集群級別 Global Dictionary,碰到了比較多的挑戰。字典壓縮只支持了 MergeTree 相關的存儲引擎。壓縮的行爲發生主要有三種操作,像數據的插入或者數據的後台合並,都會觸發 compression,還有很多數據的批量 roll in 或 roll out,也會做一些字典的異步構建。
剛才也提到,我們的主要出發點就是想在執行層去做非解壓的計算,主要是做 Select query,每一個 Select 來的時候,我們都會在分析階段做一些合法性的校驗,評估其在壓縮域上直接執行是否可行,如果滿足標准,就會改寫語法樹。如果壓縮的 column 會出現在輸出的列表中,會顯式地加一個 Decompress Stream 這樣可選的算子,然後後續執行就不太需要改動,而是可以直接支持。當 equality 的比較以及 group by 操作直接在壓縮上執行,最後整體的收益大概提高 20% 到 30%。
剛才提到,我們的字典不是一個集群水平的,那大家可能會有所疑問,比如對分布式表的 query 怎麽在壓縮域上做評估?我們稍微做了一些限制,很多時候使用壓縮場景的是用戶行爲分析系統,它是按用戶 ID 去做 shard,然後節點之間基本做到沒有交互。我們也引入了一個執行模式,稍微在它的現有計算上改了一下,我們叫做完美分布加智能合並的模式。在這個模式下,分布式表的 query 也是能夠在字典上做評估。收益也還可以,滿足當時設計時候的要求。
圖 8 特定場景內存 OOM – Step-ed Aggregation
Array 類型處理
下面介紹一下我們怎麽處理 Array 類型,並將它做得更高效。
Array 類型處理的需求主要來自于 AB 實驗的需求。當前我們的系統也會做一些實時 AB 指標的輸出,實驗 ID 在我們系統中以數組的形式存儲。頭條內部的 AB 實驗也比較多,對于一個單條記錄,它可能命中的實驗數會有幾百上千個。有時候我們需要查詢命中實驗的用戶行爲是什麽樣的,也就是要做一些 Array hasAny 語義的評估。
從 Array 執行來看,因爲它的數據比較長,所以說從數據的反序列化代價以及整個 Array 在執行層的 Block 表示來說不是特別高效,要花相當大的精力去做 Array column 的解壓。而且會在執行層消耗特別大的內存去表示,如果中間發生了 Filter 的話,要做 Block column 過濾,permutation 會帶上 Array,執行起來會比較慢。那我們就需要一個比較好的方式去優化從讀取到執行的流程。
做大數據,可能最有效的優化方式就是怎麽樣做到底層數據的剪枝,數據少是提高數據處理速度的終極法寶。我們提出了現在的剪枝方法,一個是 Part level,一個是 MRK range level。那有沒有一種針對于 Array column 的剪枝方式?我們做了下面兩個嘗試:
首先做了一個雙尺度的 Bloom Filter,記錄 Array 裏面 Key 的運動情況,實現了 Part level 和細粒度的 MRK range level,做完後在一些小的産品上效果還挺好的,但最後真正在大産品上,像抖音、頭條全量,我們發現 Fill factor 太高,實際上沒太大幫助。之後我們開發了一個 BitMap 索引,基本的想法是把 Array 的表示轉化成 Value 和 Bit 的結合。在執行層改寫,把 has 的評估直接轉換成 get BitMap。
做完之後,我們上線了一兩個産品,在一些推薦的場景上使用。這個方案主要問題就是 BitMap 數據膨脹問題稍微嚴重了一點,最近我們也做了一些優化,可能整體的數據占用是原始數據的 50% 左右,比如 Array 如果是 1G,可能 Bit map 也會有 500M。我們整個集群的副本策略是一個 1:N 的策略,副本存儲空間比較有壓力,我們現在也沒有大範圍的使用,但效果是很好的,對于評估基本上也會有一、二十倍的提升效果。
其他問題和改進
以上是我今天分享的主要內容,後面的內容相對比較彈性。字節跳動自身的數據源是比較多樣的,我們對其他數據源也做了一些特定的優化。比如我們有少量業務會消費 Kafka,而現在的 Kafka engine 沒有做主備容錯,我們也在上面做了一些高可用的 HaKafka engine 的實現,來做到主備容錯以及一些指定分區消費功能,以滿足一些特定領域的需求。
另外,我們發現它的 update/delete 功能比較弱,而我們有一部分業務場景想覆蓋業務數據庫上面的數據,像 MySQL 上也是會有一些增刪操作的。我們就基于它 Collapse 的功能做了一些設計,去支持輕量級的 update/delete,目前産品還屬于剛起步的階段,但是從測試結果來看,能夠支撐從 MySQL 到 ClickHouse 的遷移,基于 delta 表的方案也是可行的。
我們還做了一些像小文件讀取的問題,提供了一個多尺度分區的方案,但由于各種原因沒有在線上使用。
說到底,我們的需求還有很多,現在也還有很多工作正在做,比如控制面的開發,簡化整體運維,還有 Query cache 以及整個數據指標的正確性還不能達到百分之百的保障,特別是像實時數據流的數據,我們也想做更深層次的優化。我們還希望增強物化視圖,也准備提高分布式 Join 能力,因爲我們自研 BI 對此還有比較強的需求,未來我們會在這一塊做一些投入。
以上就是去年一年我們在 ClickHouse 這塊主要做的一些工作。總體來說 ClickHouse 是一個比較短小精幹的引擎,也比較容易上手和定制,大家都可以去嘗試一下。