作者 | Tirthajyoti Sarkar
譯者 | 清兒爸
編輯 | 夕顔
來源 | AI科技大本營(ID: rgznai100)
【導讀】Pandas 是 Python 生態系統中的一個了不起的庫,用于數據分析和機器學習。它在 Excel/CSV 文件和 SQL 表所在的數據世界與 Scikit-learn 或 TensorFlow 施展魔力的建模世界之間架起了完美的橋梁。
數據科學流通常是一系列的步驟:數據集必須經過清理、縮放和驗證,之後才能被強大的機器學習算法使用。
當然,這些任務可以通過 Pandas 等包提供的許多單步函數或方法來完成,但更爲優雅的方式是使用管道。在幾乎所有的情況下,通過自動執行重複性任務,管道可以減少出錯的機會,並能夠節省時間。
在數據科學領域中,具有管道特性的軟件包有 R 語言的 dplyr 和 Python 生態系統中的 Scikit-learn。
要了解它們在機器學習工作流中的應用,你可以讀這篇很棒的文章:
https://www.kdnuggets.com/2017/12/managing-machine-learning-workflows-scikit-learn-pipelines-part-1.html
Pandas 還提供了 `.pipe` 方法,可用于類似的用戶定義函數。但是,在本文中,我們將討論的是非常棒的小庫,叫 pdpipe,它專門解決了 Pandas DataFrame 的管道問題。
使用 Pandas 的流水線
Jupyter Notebook 的示例可以在我的 Github 倉庫中找到:
https://github.com/tirthajyoti/Machine-Learning-with-Python/blob/master/Pandas%20and%20Numpy/pdpipe-example.ipynb。
讓我們看看如果使用這個庫來構建有用的管道。
數據集
爲了演示,我將使用美國房價的數據集,可從 Kaggle 下載:
我們可以在 Pandas 中加載數據集,並顯示其彙總的統計信息,如下所示:
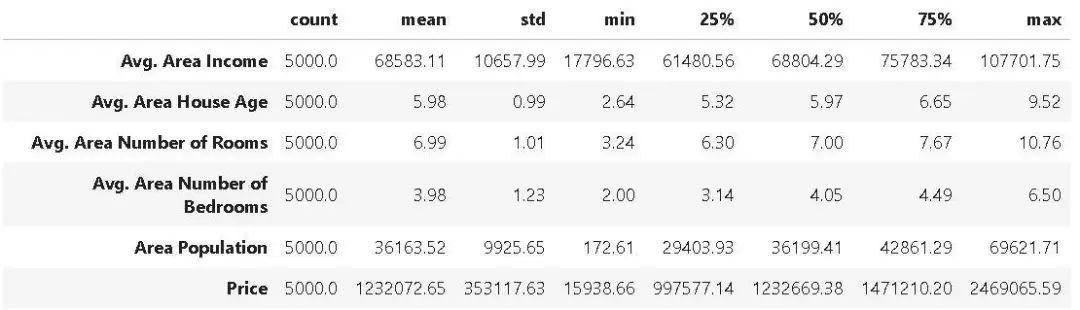
經過此步驟之後,數據集如下所示:
只需添加管道鏈級
只有當我們能夠進行多個階段時,管道才是有用和實用的。在 pdpipe 中有多種方法可以實現這一點。但是,最簡單、最直觀的方法是使用 + 運算符。這就像手工連接管道一樣!
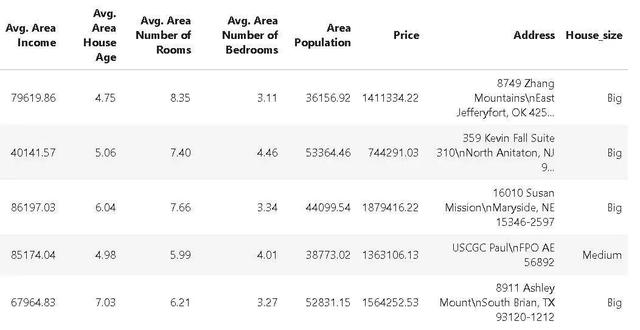
比方說,除了刪除 `age` 列之外,我們還希望對 `House size` 的列進行獨熱編碼,以便可以輕松地在數據集上運行分類或回歸算法。
pipeline = pdp.ColDrop(‘Avg. Area House Age’)pipeline+= pdp.OneHotEncode(‘House_size’)df3 = pipeline(df)
因此,我們首先使用 `ColDrop` 方法創建了一個管道對象來刪除 `Avg. Area House Age` 列。此後,我們只需使用常用的 Python 的 `+=` 語法將 `OneHotEncode` 方法添加到這個管道對象中即可。
生成的 DataFrame 如下所示。請注意,附加的指示列 `House_size_Medium` 和 `House_size_Small` 是由獨熱編碼創建的。
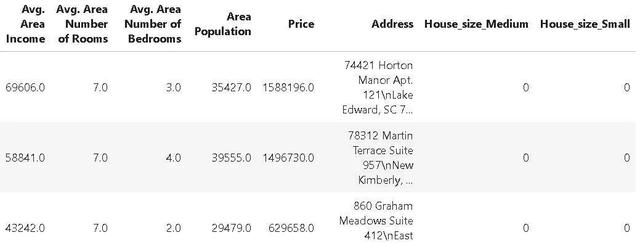
第二種方法是,在 `Price_tag` 中查找字符串 `drop`,並刪除那些匹配的行。最後,第三個方法就是刪除 `Price_tag` 標簽列,清理 DataFrame。畢竟,這個 `Price_tag`列只是臨時需要的,用于標記特定的行,在達到目的後就應該將其刪除。
所有這些都是通過簡單地鏈接同一管道上的各個階段來完成的!
現在,我們可以回顧一下,看看我們的管道從一開始對 DataFrame 都做了什麽工作:
- 刪除特定的列。
- 獨熱編碼,用于建模的分類數據列。
- 根據用戶定義函數對數據進行標記。
- 根據標記刪除行。
- 刪除臨時標記列。
所有這些,使用的是以下五行代碼:
pipeline = pdp.ColDrop(‘Avg. Area House Age’) pipeline+= pdp.OneHotEncode(‘House_size’) pipeline+=pdp.ApplyByCols(‘Price’,price_tag,’Price_tag’,drop=False) pipeline+=pdp.ValDrop([‘drop’],’Price_tag’) pipeline+= pdp.ColDrop(‘Price_tag’)
df5 = pipeline(df)
最近版本更新:直接刪除行!
我與包作者 Shay Palachy 進行了精彩的討論,他告訴我,該包的最新版本可以用 lambda 函數,僅用一行代碼即可完成行的刪除(滿足給定的條件),如下所示:
pdp.RowDrop({‘Price’: lambda x: x <= 250000})
Scikit-learn 與 NLTK
還有許多更有用、更直觀的 DataFrame 操作方法可用于 DataFrame 操作。但是,我們只是想說明,即使是 Scikit-learn 和 NLTK 包中的一些操作,也包含在 pdpipe 中,用于創建非常出色的管道。
Scikit-learn 的縮放估算器
建立機器學習模型最常見的任務之一是數據的縮放。Scikit-learn 提供了集中不同類型的縮放,例如,最小最大縮放,或者基于標准化的縮放(其中,數據集的平均值被減去,然後除以標准差)。
我們可以在管道中直接鏈接這些縮放操作。下面的代碼段演示了這種用法:
pipeline_scale = pdp.Scale(‘StandardScaler’,exclude_columns=[‘House_size_Medium’,’House_size_Small’]) df6 = pipeline_scale(df5)
本文中,我們應用了 Scikit-learn 包中的 `StandardScaler` 估算器來轉換數據以進行聚類或神經網絡擬合。我們可以選擇性地排除那些無需縮放的列,就像我們在本文中對指示列 `House_size_Medium` 和 `House_size_Small` 所做的那樣。
瞧!我們得到了縮放後的 DataFrame:

總結
如果我們對本文這個演示中顯示的所有操作進行總結,則如下所示: