那麽大數據到底需要哪些雲計算技術呢?
這裏暫且列舉一些,比如虛擬化技術,分布式處理技術,海量數據的存儲和管理技術,NoSQL、實時流數據處理、智能分析技術(類似模式識別以及自然語言理解)等。
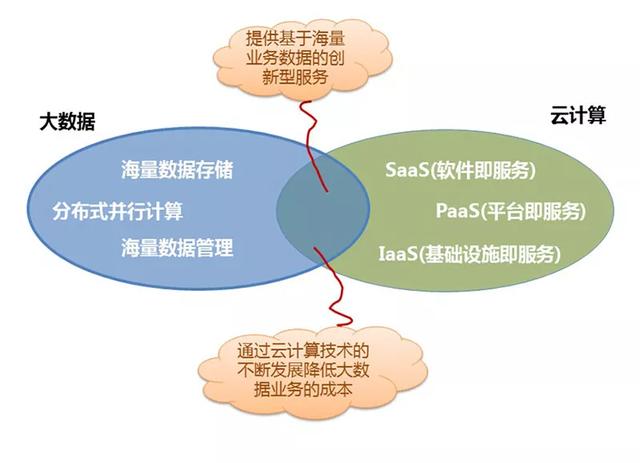
雲計算和大數據之間的關系可以用下面的一張圖來說明,兩者之間結合後會産生如下效應:可以提供更多基于海量業務數據的創新型服務;通過雲計算技術的不斷發展降低大數據業務的創新成本。
如上圖所示,淘寶的海量數據産品技術架構分爲五個層次,從上至下來看它們分別是:數據源,計算層,存儲層,查詢層和産品層。
數據來源層。存放著淘寶各店的交易數據。在數據源層産生的數據,通過DataX,DbSync和Timetunel准實時的傳輸到下面第2點所述的“雲梯”。
計算層。在這個計算層內,淘寶采用的是Hadoop集群,這個集群,我們暫且稱之爲雲梯,是計算層的主要組成部分。在雲梯上,系統每天會對數據産品進行不同的MapReduce計算。
存儲層。在這一層,淘寶采用了兩個東西,一個使MyFox,一個是Prom。MyFox是基于MySQL的分布式關系型數據庫的集群,Prom是基于Hadoop Hbase技術的一個NoSQL的存儲集群。
查詢層。在這一層中,Glider是以HTTP協議對外提供restful方式的接口。數據産品通過一個唯一的URL來獲取到它想要的數據。同時,數據查詢即是通過MyFox來查詢的。
最後一層是産品層,這個就不用解釋了。
存儲技術
大數據可以抽象的分爲大數據存儲和大數據分析,這兩者的關系是:大數據存儲的目的是支撐大數據分析。到目前爲止,還是兩種截然不同的計算機技術領域:大數據存儲致力于研發可以擴展至PB甚至EB級別的數據存儲平台;大數據分析關注在最短時間內處理大量不同類型的數據集。
提到存儲,有一個著名的摩爾定律相信大家都聽過:18個月集成電路的複雜性就增加一倍。所以,存儲器的成本大約每18-24個月就下降一半。成本的不斷下降也造就了大數據的可存儲性。
比如,Google大約管理著超過50萬台服務器和100萬塊硬盤,而且Google還在不斷的擴大計算能力和存儲能力,其中很多的擴展都是基于在廉價服務器和普通存儲硬盤的基礎上進行的,這大大降低了其服務成本,因此可以將更多的資金投入到技術的研發當中。
以Amazon舉例,Amazon S3 是一種面向 Internet 的存儲服務。該服務旨在讓開發人員能更輕松的進行網絡規模計算。Amazon S3 提供一個簡明的 Web 服務界面,用戶可通過它隨時在 Web 上的任何位置存儲和檢索的任意大小的數據。此服務讓所有開發人員都能訪問同一個具備高擴展性、可靠性、安全性和快速價廉的基礎設施,Amazon 用它來運行其全球的網站網絡。再看看S3的設計指標:在特定年度內爲數據元提供 99.999999999% 的耐久性和 99.99% 的可用性,並能夠承受兩個設施中的數據同時丟失。
S3很成功也確實卓有成效,S3雲的存儲對象已達到萬億級別,而且性能表現相當良好。S3雲已經擁萬億跨地域存儲對象,同時AWS的對象執行請求也達到百萬的峰值數量。目前全球範圍內已經有數以十萬計的企業在通過AWS運行自己的全部或者部分日常業務。這些企業用戶遍布190多個國家,幾乎世界上的每個角落都有Amazon用戶的身影。
感知技術
大數據的采集和感知技術的發展是緊密聯系的。以傳感器技術,指紋識別技術,RFID技術,坐標定位技術等爲基礎的感知能力提升同樣是物聯網發展的基石。全世界的工業設備、汽車、電表上有著無數的數碼傳感器,隨時測量和傳遞著有關位置、運動、震動、溫度、濕度乃至空氣中化學物質的變化,都會産生海量的數據信息。
而隨著智能手機的普及,感知技術可謂迎來了發展的高峰期,除了地理位置信息被廣泛的應用外,一些新的感知手段也開始登上舞台,比如,最新的”iPhone 5S”在home鍵內嵌指紋傳感器,新型手機可通過呼氣直接檢測燃燒脂肪量,用于手機的嗅覺傳感器面世可以監測從空氣汙染到危險的化學藥品,微軟正在研發可感知用戶當前心情智能手機技術,谷歌眼鏡InSight新技術可通過衣著進行人物識別。
除此之外,還有很多與感知相關的技術革新讓我們耳目一新:比如,牙齒傳感器實時監控口腔活動及飲食狀況,嬰兒穿戴設備可用大數據去養育寶寶,Intel正研發3D筆記本攝像頭可追蹤眼球讀懂情緒,日本公司開發新型可監控用戶心率的紡織材料,業界正在嘗試將生物測定技術引入支付領域等。
其實,這些感知被逐漸捕獲的過程就是就世界被數據化的過程,一旦世界被完全數據化了,那麽世界的本質也就是信息了。
就像一句名言所說,“人類以前延續的是文明,現在傳承的是信息。”
大數據的實踐
互聯網的大數據
互聯網上的數據每年增長50%,每兩年便將翻一番,而目前世界上90%以上的數據是最近幾年才産生的。據IDC預測,到2020年全球將總共擁有35ZB的數據量。互聯網是大數據發展的前哨陣地,隨著WEB2.0時代的發展,人們似乎都習慣了將自己的生活通過網絡進行數據化,方便分享以及記錄並回憶。
互聯網上的大數據很難清晰的界定分類界限,我們先看看BAT的大數據:
百度擁有兩種類型的大數據:用戶搜索表征的需求數據;爬蟲和阿拉丁獲取的公共web數據。搜索巨頭百度圍繞數據而生。它對網頁數據的爬取、網頁內容的組織和解析,通過語義分析對搜索需求的精准理解進而從海量數據中找准結果,以及精准的搜索引擎關鍵字廣告,實質上就是一個數據的獲取、組織、分析和挖掘的過程。搜索引擎在大數據時代面臨的挑戰有:更多的暗網數據;更多的WEB化但是沒有結構化的數據;更多的WEB化、結構化但是封閉的數據。
阿裏巴巴擁有交易數據和信用數據。這兩種數據更容易變現,挖掘出商業價值。除此之外阿裏巴巴還通過投資等方式掌握了部分社交數據、移動數據。如微博和高德。
騰訊擁有用戶關系數據和基于此産生的社交數據。這些數據可以分析人們的生活和行爲,從裏面挖掘出政治、社會、文化、商業、健康等領域的信息,甚至預測未來。
在信息技術更爲發達的美國,除了行業知名的類似Google,Facebook外,已經湧現了很多大數據類型的公司,它們專門經營數據産品,比如:
Metamarkets:這家公司對Twitter、支付、簽到和一些與互聯網相關的問題進行了分析,爲客戶提供了很好的數據分析支持。
Tableau:他們的精力主要集中于將海量數據以可視化的方式展現出來。Tableau爲數字媒體提供了一個新的展示數據的方式。他們提供了一個免費工具,任何人在沒有編程知識背景的情況下都能制造出數據專用圖表。這個軟件還能對數據進行分析,並提供有價值的建議。
ParAccel:他們向美國執法機構提供了數據分析,比如對15000個有犯罪前科的人進行跟蹤,從而向執法機構提供了參考性較高的犯罪預測。他們是犯罪的預言者。
QlikTech:QlikTech旗下的Qlikview是一個商業智能領域的自主服務工具,能夠應用于科學研究和藝術等領域。爲了幫助開發者對這些數據進行分析,QlikTech提供了對原始數據進行可視化處理等功能的工具。
GoodData:GoodData希望幫助客戶從數據中挖掘財富。這家創業公司主要面向商業用戶和IT企業高管,提供數據存儲、性能報告、數據分析等工具。
TellApart:TellApart和電商公司進行合作,他們會根據用戶的浏覽行爲等數據進行分析,通過鎖定潛在買家方式提高電商企業的收入。
DataSift:DataSift主要收集並分析社交網絡媒體上的數據,並幫助品牌公司掌握突發新聞的輿論點,並制定有針對性的營銷方案。這家公司還和Twitter有合作協議,使得自己變成了行業中爲數不多可以分析早期tweet的創業公司。
Datahero:公司的目標是將複雜的數據變得更加簡單明了,方便普通人去理解和想象。
舉了很多例子,這裏簡要歸納一下,在互聯網大數據的典型代表性包括:
1-用戶行爲數據(精准廣告投放、內容推薦、行爲習慣和喜好分析、産品優化等)
2-用戶消費數據(精准營銷、信用記錄分析、活動促銷、理財等)
3-用戶地理位置數據(O2O推廣,商家推薦,交友推薦等)
4-互聯網金融數據(P2P,小額貸款,支付,信用,供應鏈金融等)
5-用戶社交等UGC數據(趨勢分析、流行元素分析、受歡迎程度分析、輿論監控分析、社會問題分析等)
政府的大數據
近期,奧巴馬政府宣布投資2億美元拉動大數據相關産業發展,將“大數據戰略”上升爲國家意志。奧巴馬政府將數據定義爲“未來的新石油”,並表示一個國家擁有數據的規模、活性及解釋運用的能力將成爲綜合國力的重要組成部分,未來,對數據的占有和控制甚至將成爲陸權、海權、空權之外的另一種國家核心資産。
在國內,政府各個部門都握有構成社會基礎的原始數據,比如,氣象數據,金融數據,信用數據,電力數據,煤氣數據,自來水數據,道路交通數據,客運數據,安全刑事案件數據,住房數據,海關數據,出入境數據,旅遊數據,醫療數據,教育數據,環保數據等等。這些數據在每個政府部門裏面看起來是單一的,靜態的。但是,如果政府可以將這些數據關聯起來,並對這些數據進行有效的關聯分析和統一管理,這些數據必定將獲得新生,其價值是無法估量的。
具體來說,現在城市都在走向智能和智慧,比如,智能電網、智慧交通、智慧醫療、智慧環保、智慧城市,這些都依托于大數據,可以說大數據是智慧的核心能源。從國內整體投資規模來看,到2012年底全國開建智慧城市的城市數超過180個,通信網絡和數據平台等基礎設施建設投資規模接近5000億元。“十二五”期間智慧城市建設拉動的設備投資規模將達1萬億元人民幣。大數據爲智慧城市的各個領域提供決策支持。在城市規劃方面,通過對城市地理、氣象等自然信息和經濟、社會、文化、人口等人文社會信息的挖掘,可以爲城市規劃提供決策,強化城市管理服務的科學性和前瞻性。在交通管理方面,通過對道路交通信息的實時挖掘,能有效緩解交通擁堵,並快速響應突發狀況,爲城市交通的良性運轉提供科學的決策依據。在輿情監控方面,通過網絡關鍵詞搜索及語義智能分析,能提高輿情分析的及時性、全面性,全面掌握社情民意,提高公共服務能力,應對網絡突發的公共事件,打擊違法犯罪。在安防與防災領域,通過大數據的挖掘,可以及時發現人爲或自然災害、恐怖事件,提高應急處理能力和安全防範能力。
另外,作爲國家的管理者,政府應該有勇氣將手中的數據逐步開放,供給更多有能力的機構組織或個人來分析並加以利用,以加速造福人類。比如,美國政府就籌建了一個data.gov網站,這是奧巴馬任期內的一個重要舉措:要求政府公開透明,而核心就是實現政府機構的數據公開。截止目前,已經開放了有91054 個datasets;349citizen-developed apps;137 mobile apps;175 agencies and subagencies;87 galleries;295 Government APIs。
企業的大數據
企業的CXO們最關注的還是報表曲線的背後能有怎樣的信息,他該做怎樣的決策,其實這一切都需要通過數據來傳遞和支撐。在理想的世界中,大數據是巨大的杠杆,可以改變公司的影響力,帶來競爭差異、節省金錢、增加利潤、愉悅買家、獎賞忠誠用戶、將潛在客戶轉化爲客戶、增加吸引力、打敗競爭對手、開拓用戶群並創造市場。
那麽,哪些傳統企業最需要大數據服務呢?抛磚引玉,先舉幾個例子:1) 對大量消費者提供産品或服務的企業(精准營銷);2) 做小而美模式的中長尾企業(服務轉型);3) 面臨互聯網壓力之下必須轉型的傳統企業(生死存亡)。
對于企業的大數據,還有一種預測:隨著數據逐漸成爲企業的一種資産,數據産業會向傳統企業的供應鏈模式發展,最終形成“數據供應鏈”。這裏尤其有兩個明顯的現象:1) 外部數據的重要性日益超過內部數據。在互聯互通的互聯網時代,單一企業的內部數據與整個互聯網數據比較起來只是滄海一粟;2) 能提供包括數據供應、數據整合與加工、數據應用等多環節服務的公司會有明顯的綜合競爭優勢。
對于提供大數據服務的企業來說,他們等待的是合作機會,就像微軟史密斯說的:“給我提供一些數據,我就能做一些改變。如果給我提供所有數據,我就能拯救世界。”
然而,一直做企業服務的巨頭將優勢不在,不得不眼看新興互聯網企業加入戰局,開啓殘酷競爭模式。爲何會出現這種局面?從 IT 産業的發展來看,第一代 IT 巨頭大多是 ToB 的,比如 IBM、Microsoft、Oracle、SAP、HP這類傳統 IT 企業;第二代 IT 巨頭大多是ToC 的,比如 Yahoo、Google、Amazon、Facebook 這類互聯網企業。大數據到來前,這兩類公司彼此之間基本是井水不犯河水;但在當前這個大數據時代,這兩類公司已經開始直接競爭。比如 Amazon 已經開始提供雲模式的數據倉庫服務,直接搶占 IBM、Oracle 的市場。這個現象出現的本質原因是:在互聯網巨頭的帶動下,傳統 IT 巨頭的客戶普遍開始從事電子商務業務,正是由于客戶進入了互聯網,所以傳統 IT 巨頭們不情願地被拖入了互聯網領域。如果他們不進入互聯網,他們業務必將萎縮。在進入互聯網後,他們又必須將雲技術,大數據等互聯網最具有優勢的技術通過封裝打造成自己的産品再提供給企業。
以IBM舉例,上一個十年,他們抛棄了PC,成功轉向了軟件和服務,而這次將遠離服務與咨詢,更多地專注于因大數據分析軟件而帶來的全新業務增長點。IBM執行總裁羅睿蘭認爲,“數據將成爲一切行業當中決定勝負的根本因素,最終數據將成爲人類至關重要的自然資源。”IBM積極的提出了“大數據平台”架構。該平台的四大核心能力包括Hadoop系統、流計算(StreamComputing)、數據倉庫(Data Warehouse)和信息整合與治理(Information Integration and Governance)