變異測試也可以歸爲模糊測試,因爲模糊測試的數據産生有兩種類型:
- 基于變異的模糊器對有效的輸入進行變異而生成一個輸入集合;
- 基于生成的模糊器分析所提供的有效輸入結構,並生成全新的數據。
第一種類型其實可以歸爲變異測試,即變異測試是模糊測試的一種類型。
模糊測試的概念,去年年底在 2021年軟件測試工具總結——模糊測試工具 已經有交代,包括什麽是模糊測試,以及目前主要的三種模糊測試技術(黑盒隨機模糊、基于語法的模糊和白盒模糊處理),模糊測試屬于動態測試,是一種自動發現軟件安全漏洞的經濟有效的測試技術,常常會在軟件安全開發生命周期中發現非常嚴重的安全故障或缺陷,例如:崩潰、內存泄漏,未處理的異常等,而且模糊測試有助于發現傳統測試方法或手動審計無法檢測到的缺陷。
今天我們側重討論智能的模糊測試技術,然後利用這種技術對機器學習應用進行測試。
1. 智能模糊測試
智能模糊控制器將允許開發人員或研究人員探索更多的應用程序,並有可能找到以前未發現的錯誤。這種 “智能 “來自于在模糊控制器中內置的一些通用智能,例如:
- 輸入格式是怎樣的?
- 上一次的輸入是否比上一次的輸入引起了進一步的代碼覆蓋?
- 可以對輸入進行哪些修改以探索進一步的代碼覆蓋?
如果模糊器能夠確認這三個因素,那麽爲應用程序生成的輸入類型將更多地針對特定的應用程序進行有效性的設計,比傳統的模糊測試能更快找到bug。
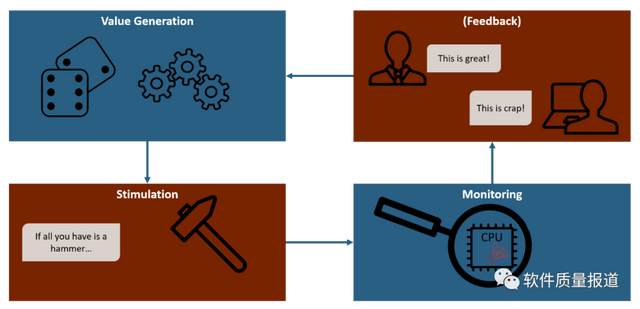
一般來說,智能模糊器會使用不同類型的算法來生成這些任意的輸入,而不是簡單地使用絕對隨機輸入的方法。智能模糊器常采用的方法有:
- 模板/語法模糊法:基于手動生成的模板的模糊測試,通常由模糊測試工具的開發商提供, 適用于有協議或特定結構輸入的應用程序。如Peach Fuzzer可以建立狀態模型和數據模型,設置監控器,根據狀態來調整數據生成策略。
- 指導性模糊測試:模糊應用程序觀察目標應用程序狀態的變化,然後利用這些知識來生成下一個輸入。可以引入符號執行的方法,指導下一個輸入的生成。
- 基于變異的模糊測試:輸入通過變異技術進行修改,如比特翻轉、交換字節、刪除字節,或對先前的輸入或種子進行其他奇怪的修改。
- 基于進化的模糊處理:這是引導式模糊方法和基于變異的模糊方法的結合。可以引入遺傳算法等,最初的輸入是通過種子創建的,然後隨著時間的推移,通過變異算子進行叠代,測試能力越來越強大。

每種技術都有其優點和缺點,而且可能不適合每一種用例。這方面的應用越來越多,如:
- Microsoft的研究團隊在2008年就將模糊分析和符號執行結合起來,研究出具有智能模糊測試策略的工具SAGE,這是標志性的工作,將模糊測試帶入智能的時代。SAGE記錄執行情況並以符號方式評估跟蹤,以收集新的約束條件,使用約束求解器産生新的輸入,以執行新的控制路徑,然後度量代碼覆蓋率,對達到最大測試深度的新輸入進行排序(詳見:SAGE: Whitebox Fuzzing for Security Testing)。
- 新加坡管理大學研究團隊的SmartFuzz將組合測試生成與輕量級程序分析相結合,其目的在于以高效、自動化的方式提高組合測試覆蓋率(SmartFuzz: An Automated Smart Fuzzing Approach for Testing SmartThings Apps,2020 27th APSEC)。
- Google有一個在Cloud中運行的智能模糊測試工具oss-fuzz(詳見:https://google.github.io/oss-fuzz/)
- 蘋果公司在iOS10中使用了LLVM技術(可以使用libFuzzer,詳見using LLVM’s libFuzzer with Swift),可以分析App Store中應用程序的字節碼或者位碼,通過LLVM輕松的分析這些應用程序,從而找到最基礎的安全漏洞,如API濫用和隱私泄漏等。
2. 智能模糊測試的基本原理
爲了進行有效的模糊測試,智能模糊控制器能夠執行下列任務:
- 産生新的種子
- 啓動目標程序(通過Harness或單獨的程序)。
- 爲目標程序提供一個測試用例
- 確定一個給定的用例是否提供了新的代碼覆蓋率
- 變異/進化能帶來正回報的輸入
- 檢測程序是否崩潰或停頓
在這個過程中,種子數據可以由用戶提供,但智能測試工具能夠比較、分析哪些種子提供了更高的代碼覆蓋率。對于每個提供新代碼覆蓋率的測試用例,使用選定的變異方法/策略對其進行修改。當執行基于語法/模板的模糊處理時,確保它符合模板的要求。然後,將這些新的測試用例添加到測試用例隊列中,以便模糊測試工具執行應用程序。導致崩潰的輸入會被重新定位到一個與其他種子分開的文件夾中,因此用戶知道是哪個輸入導致了這個意外的行爲。
模糊化框架(Harness)的開發是爲了彌補模糊器期望的輸入方式和應用中實際的輸入方式之間的差異。借助模糊化框架,可以將來自模糊器的輸入正確地轉化、傳遞給模糊目標,從而使目標能夠像任何正常的交互一樣處理輸入。
示例:AFLSmart工具的輸入模型mp3.xml
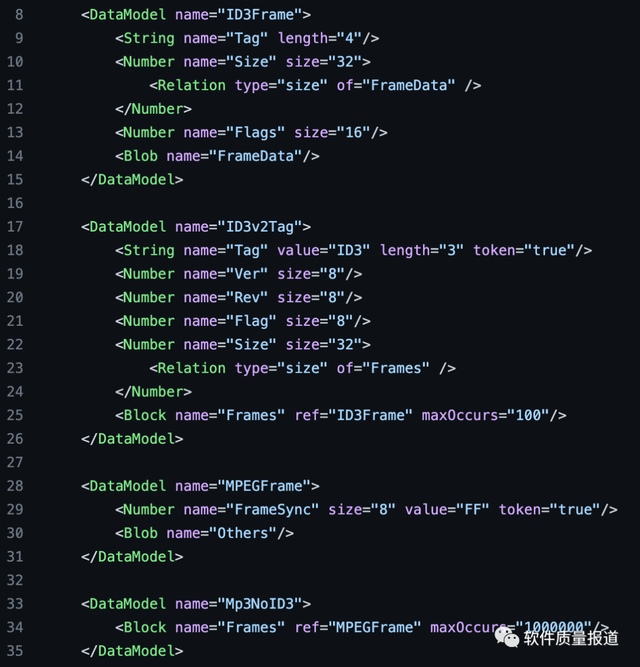
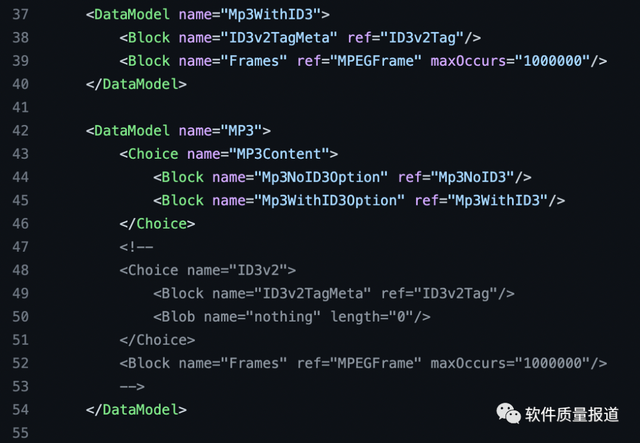

3. 針對機器學習算法進行模糊測試
如果模糊測試的核心部分是找到有問題的輸入,那麽關鍵問題就變成:我們如何去實際找到這些導致系統行爲失常的新輸入?
第一個想法,自然是使用完全隨機的搜索,例如通過隨機修改像素值來産生輸入,直到機器學習(ML)系統輸出錯誤結果。但這種想法有幾個缺點。首先,其效率很低,因爲找到相關的故障案例可能很困難,而且計算成本很高。其次,怎麽知道“ML系統輸出錯誤結果”,因爲ML系統出錯和安全性測試不一樣,系統不會崩潰,但其實結果已經出錯了。例如,ML系統把圖像中的狗判定爲一只貓,而不會引起任何警報。最後,在應用程序的上下文中,輸入可能很快變得沒有語義,從而超出了系統預期的良好表現。對這樣的輸入進行測試可能會很有趣,例如,接觸不良可能會導致隨機的圖像,這時我們仍然希望系統能優雅地失敗。

(添加合成霧會導致對現場ML系統是否需要維護檢查的判斷産生重大影響)
在我們繼續之前,讓我們看一下如何評估系統是否真的在失效。這些是對輸入圖像的變化,以一種可預測的方式改變已知的標簽。例如,分類問題的輸出往往不應取決于圖像的旋轉方式:旋轉後的狗仍然是一只狗。
這個概念奠定了針對ML系統進行模糊測試的基礎。只要通過某種操作修改輸入,引起ML算法的誤解,預測結果與標簽不一樣,我們就可以確定一個新的輸入 “破壞 “了系統。
爲了成功應用模糊測試,我們需要比完全隨機搜索更有效率的方法。大多數方法都是基于根據一組指定的規則和操作來變異初始輸入的想法。例如,DLFuzz(“DLFuzz: Differential Fuzzing Testing of Deep Learning Systems”,Guo et al.,arXiv.org, 2018.)著重于這樣的想法:由于訓練過的系統中神經元覆蓋率低,有問題的輸入往往會出現。在訓練過程中沒有被激活的大量神經元子集,可能被新圖像激活而導致意外的預測結果。DLFuzz修改輸入圖像以激活這些很少被訪問的神經元,從而觸發這類故障。
另一種方法,DeepHunter(“DeepHunter: A Coverage-Guided Fuzz Testing Framework for Deep Neural Networks”, Xie et al., ISSTA, 2019)在保留了圖像標簽的集合中選擇一組隨機變換,這樣一來,新生成的模糊輸入是否會降低ML的性能,可以用原來的圖像標簽進行評估。事實上,如果我們通過隨機旋轉來修改一幅圖像,並期望標簽保持不變,我們可以將系統對新旋轉圖像的輸出與原始圖像標簽進行比較,以判斷ML的預測是否正確。
4. 如何利用模糊測試來測試ML系統?
在實踐中,模糊測試是測試ML系統的重要技術之一。它允許我們對系統進行壓力測試,通過利用更大的合成數據集,可以包含那些實際中可能出現但不在原始數據集中的圖像,這樣我們更清楚地了解ML系統的實際表現。
假設我們正在爲一個機器人建立一個系統,這個機器人被設計用來調查一個可再生能源的網站。在建立這樣的系統時,數據的可用性往往成爲一個核心挑戰。雖然我們可能有足夠的在雨天拍攝的一般圖像,以及在晴天拍攝的風力渦輪機的圖像,但雨天的渦輪機圖像可能很稀少。對于複雜的現實世界的系統,往往不可能對實踐中出現的所有情況都有足夠的覆蓋。因此,數據擴增技術是構建計算機視覺系統的關鍵和標准的可用技術。
模糊測試可以在系統的運行環境中對其進行壓力測試,以找到系統表現較弱的組合,以及應該進一步增強或收集新數據的地方。例如,在上面機器人測試的例子中,我們可以通過以下方式産生模糊輸入:
- 在強度爲x的圖像上添加隨機的合成霧氣。
- 在位置p處添加強度爲y的隨機強光。
可以通過這些變換進行模糊變異來産生大量的輸入圖像,以尋找故障案例。這個過程非常強大,因爲它可以提供大量在實踐中可能出現但在現有數據集中不存在的圖像。在DeepHunter中可以找到更多關于如何通過引導的方法來完成的靈感。通過在整個開發過程中反複運行這樣的測試,團隊可以確保ML系統按照預期工作,並且可以發現需要進一步增加數據和收集數據的問題案例。
模糊測試還可以幫助回答一個更廣泛的問題:當系統遇到 “意外 “的圖像(不在其運行環境考慮之內)時,是否表現良好?開發團隊應確保系統在這種情況下能優雅地失敗。
一個典型的神經網絡的複雜性使它容易受到各種故障的影響,包括在像素空間上與系統表現良好的圖像相近的圖像上出現故障。這一點在對抗性例子領域已經有了廣泛的研究。
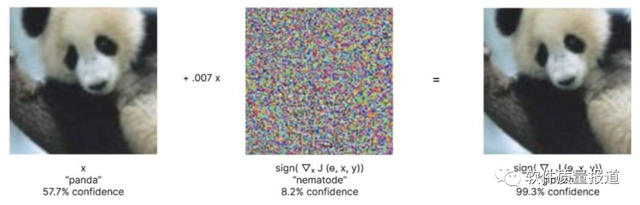
(從“Explaining and Harnessing Adversarial Examples‘”中,在加入小的噪聲後網絡性能發生了巨大的變化,可信度從 57.7%提高到99.3%。)
模糊測試也可以用于ML系統的冒煙測試,例如測試系統在部分變黑的圖像和其他此類變換中的表現。一些開源的庫(如“Albumentations: Fast and Flexible Image Augmentations”, Buslaev et al., Information, 2020)提供了廣泛的此類變換。因此,這種測試也應該被添加到關鍵的ML組件的測試集中。
模糊測試也可以針對區塊鏈的智能合約進行測試,一般采用基于語法的模糊測試方法,例如可以模擬變量覆蓋、影子變量、整數溢出、任意地址寫入、代碼注入、短地址攻擊、不一致性攻擊等方面的測試。這類工具有ImmuneBytes、Echidna、ContractFuzzer等。
最好的模糊測試工具與資源
- https://github.com/TideSec/Peach_Fuzzing
- https://github.com/aflsmart/aflsmart
- https://github.com/google/oss-fuzz
- https://www.microsoft.com/en-us/springfield/
- http://llvm.org/docs/LibFuzzer.html
- https://clang.llvm.org/docs/SanitizerCoverage.html
- https://github.com/crytic/echidna
- https://github.com/turned2670/DLFuzz
- https://github.com/Interfish/deep_hunter
- https://github.com/rohanpadhye/FuzzFactory
- https://consensys.net/diligence/tools/
- https://github.com/OpenRCE/sulley