2017 年,最讓大家印象深刻的就是何恺明一舉拿下 ICCV 2017 兩項大獎。10 月 27 日-11 月 2 日,今年的計算機視覺領域頂級會議 International Conference on Computer Vision(ICCV)在首爾召開。昨天大會正式公布了最佳論文獎由論文《SinGAN:從單張圖像學習生成模型》獲得,最佳學生論文獎則由《PLMP——完整的多視圖可見性中的點線最小問題》獲得。

整理 | AI科技大本營編輯部
出品 | AI科技大本營(ID:rgznai100)

ICCV 2019 最佳論文

論文標題:SinGAN:從單張圖像學習生成模型
《SinGAN: Learning a Generative Model from a Single Natural Image》
作者:Tamar Rott Shaham(以色列理工學院),Tali Dekel(谷歌),Tomer Michaeli(以色列理工學院)
論文簡介:該論文介紹了一種無條件生成模型——SinGAN,它可以從單個自然圖像中學習。該模型經過訓練,可以捕獲圖像內斑塊的內部分布,之後生成高質量、多樣化的樣本,視覺內容與原圖像相同。SinGAN 包含一個完全卷積的金字塔結構 GAN ,每個 GAN 負責按不同比例學習圖像的斑狀分布。這樣就可以生成具有任意大小和縱橫比的新樣本,這些樣本具有明顯的可變性,同時又可以保持訓練圖像的整體結構和精細紋理。與以前的單圖像 GAN 方案相比,我們的方法不僅限于紋理圖像,而且是無條件的(即它從噪聲中生成樣本)。用戶研究證實,生成的樣本通常可以假亂真,SinGAN 在各種圖像處理任務中具有廣泛的實用性。
論文地址:
https://arxiv.org/abs/1905.01164

ICCV 2019 最佳學生論文

論文標題:PLMP——完整的多視圖可見性中的點線最小問題
PLMP — Point-Line Minimal Problems in Complete Multi-View Visibility
作者:Timothy Duff(喬治亞理工大學),Kathlen Kohn(瑞典皇家理工學院),Anton Leykin(喬治亞理工大學),Tomas Pajdla(捷克理工大學)
論文簡介:我們提出了完全通過校准透視相機,觀察完整點和線的一般排列最小問題分類的方法。我們證明總計僅有 30 個最小問題,對 6 個以上的攝像機,5 個以上的點以及 6 條以上的線不存在任何問題。我們進行了一系列檢測最小值的測試,這些測試從自由度計數開始,到對代表示例進行完整的符號和數字驗證結束。對于發現的所有最小問題,我們將介紹它們的代數次數,即解決方案的數量,以衡量其固有難度。結果顯示,問題的難度隨著視圖數量的增長而增長。重要的是,幾個新的次數較小的最小問題在圖像匹配和 3D 重建中可能具有實用性。
論文鏈接:
https://arxiv.org/abs/1903.10008

ICCV 2019 回顧
1、投稿情況
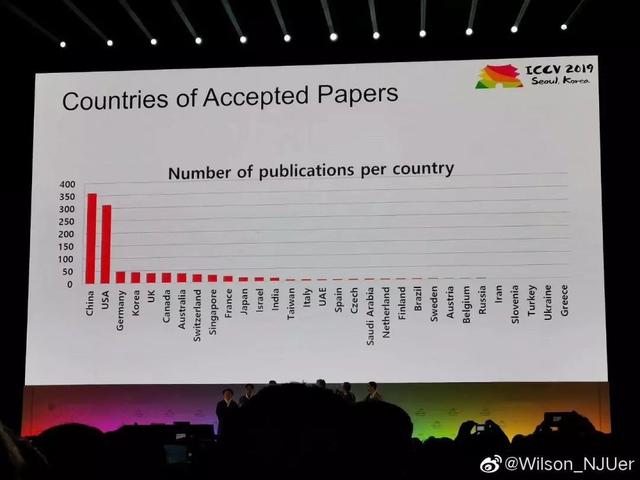
3 月 22 日,ICCV 2019 的截稿日,ICCV 官方公布了本屆會議的論文投稿數據,共收到了 4328 篇論文(注:大會期間公布的數據是 4303 篇),這個數量是上一屆 ICCV 2017 的兩倍。
不僅投稿數量破紀錄,國內高校和企業的投稿數量分外吸睛。ICCV 2019 共收到 23 來自中國機構和企業的投稿,其中,科院、清華大學、華爲、百度,分別以 237、175、91、47 篇的投稿數量位列第 1 、第 2、第 6 和第 15 位。
2、接收情況
7 月 23 日,ICCV 2019 公布,本屆會議共接收 1075 篇論文,接收率爲 25% 左右,雖然和 CVPR 2019 的接收率 25.2% 相差不大,不過相比上屆 ICCV 2017 投稿數量翻番的情況,今年的競爭可謂非一般的激烈。
ICCV 2017 共接收 621 篇論文,接受率達 28.9%;其中 Poster、Spotlight、Oral 的比例分別爲 24.61%、2.61% 以及 2.09%。
ICCV 2019 論文接收列表:
http://openaccess.thecvf.com/ICCV2019.py
ICCV 2019 大會官網:
http://iccv2019.thecvf.com
3、熱詞與個人發表論文數量統計
ICCV 2019 中的論文關鍵詞都有哪些?據 Twitter 網友 Shao-Hua Sun 統計分析,本屆會議中:學習、網絡、圖像、目標檢測、深度、3D、視頻、語義分割等都是論文中提及最多的詞彙。
而“ICCV 2019 Paper Top Authors”的統計更是可以看到這一屆大神們的論文提交數量。其中,作者 Ling Shao 以 15 篇入選位居榜首,緊隨其後的 Yi Yang 和 Qi Tian 分別有 10 篇論文,而有 9 篇和 8 篇論文的作者也分別有 6 位,7 篇論文的作者多達 12 位,6 篇論文作者更是達 17 位。
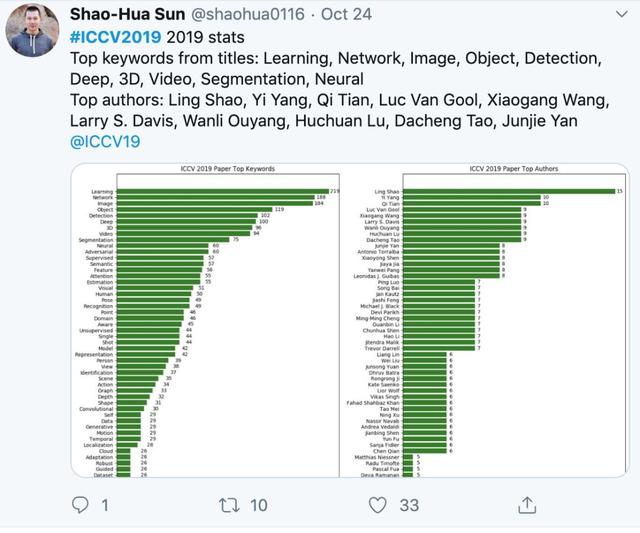
注:入選論文最多的邵嶺(Ling Shao)是阿聯酋國家級“起源人工智能研究院”(IIAI)CEO兼首席科學家,他曾是英國東安格利亞大學計算機學院的教授,英國計算機學會 Fellow、IET Fellow、IEEE 高級會員以及 ACM 終身會員。他署名投稿的論文,共有15篇被接收。而本屆ICCV,IIAI成績斐然,共有28篇論文入選。
入選論文排名第二的分別都有10篇論文入選:一位是悉尼科技大學教授楊易(Yi Yang),去年加入了百度研究院;另一位是 IEEE Fellow、華爲諾亞方舟實驗室計算視覺首席科學家田奇(Qi Tian),他曾是美國德克薩斯大學聖安東尼奧分校計算機系教授。
此外,大會還公布了論文接收數量排名,前三位的國家或地區分別是中國、美國、德國。

商湯科技 57 篇論文入選
ICCV 2019 大會的其中一位主席是來自香港中文大學的信息工程系系主任湯曉鷗,同時他還是中國科學院深圳先進技術研究院的副院長兼商湯科技創始人。

其他三名大會主席則分別是首爾大學的 Kyoung Mu Lee 教授、伊利諾伊大學厄巴納 – 香槟分校的 David Forsyth 教授以及蘇黎世聯邦理工學院的 Marc Pollefeys 教授。
本屆會議,商湯科技及聯合實驗室有 57 篇論文入選 ICCV 2019(包含 11 篇 Oral 論文),錄取的論文在多個領域實現突破,包括:面向目標檢測的深度網絡基礎算子、基于插值卷積的點雲處理主幹網絡、面向AR/VR場景的人體感知與生成、面向全場景理解的多模態分析等。這些突破性的計算機視覺算法有著豐富的應用場景。
下面,從 4 大方向選出 6 篇商湯及商湯聯合實驗室入選 ICCV 2019 的代表性論文,闡釋計算機視覺和深度學習技術最新突破。
(一)面向目標檢測的深度網絡基礎算子
-
代表性論文:《CARAFE: 基于內容感知的特征重組》
特征上采樣是深度神經網絡結構中的一種基本的操作,例如:特征金字塔。它的設計對于需要進行密集預測的任務,例如物體檢測、語義分割、實例分割,有著關鍵的影響。本工作中,我們提出了基于內容感知的特征重組(CARAFE),它是一種通用的,輕量的,效果顯著的特征上采樣操作。
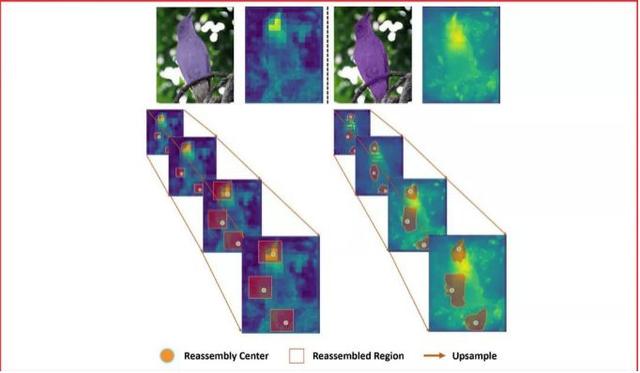
CARAFE有這樣一些引人注目的特性:1.大視野。不同于之前的上采樣方法(如:雙線性插值),僅使用亞像素的臨近位置。CARAFE可以聚合來自大感受野的環境特征信息。2.基于特征感知的處理。不同于之前方法對于所有樣本使用固定的核(如:反卷積),CARAFE可以對不同的位置進行內容感知,用生成的動態的核進行處理。3.輕量和快速計算。CARAFE僅帶來很小的額外開銷,可以容易地集成到現有網絡結構中。我們對CARAFE在目標檢測,實例分割,語義分割和圖像修複的主流方法上進行廣泛的測試,CARAFE在全部4種任務上都取得了一致的明顯提升。CARAFE具有成爲未來深度學習研究中一個有效的基礎模塊的潛力。
(二)面向三維視覺的點雲處理基礎網絡
-
代表性論文:《基于插值卷積的點雲處理主幹網絡》
點雲是一種重要的三維數據類型,被廣泛地運用于自動駕駛等場景中。傳統方法依賴光柵化或者多視角投影,將點雲轉化成圖像、體素其他數據類型進行處理。近年來池化和圖神經元網絡在點雲處理中展現出良好的性能,但仍然受限于計算效率,並且算法易受物體尺度、點雲密度等因素影響。
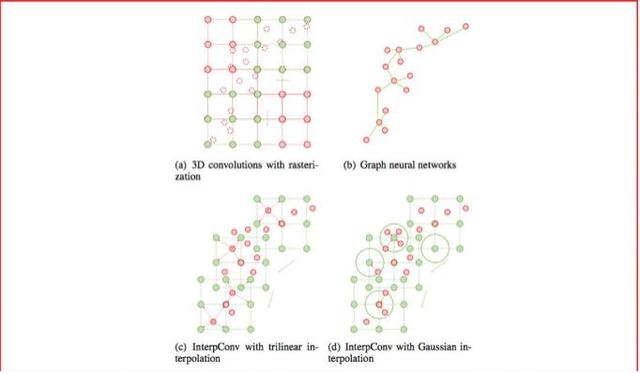
本文提出了一種全新的卷積方式,即插值卷積,能夠從點雲中高效地學習特征。插值卷積從標准圖像卷積和圖像插值中獲取靈感,卷積核被劃分成一組空間中離散的向量,每個向量擁有各自的三維坐標,當點雲中的某點落在卷積向量的鄰域時,參考圖像插值的過程,我們將該點對應的特征向量插值到卷積向量對應的位置上,然後進行標准的卷積運算,最後通過正則化消除點雲局部分布不均的影響。
面向不同的任務,我們提出了基于插值卷積的點雲分類和分割網絡。分類網絡采用多路徑設計,每一條路徑的插值卷積核具有不同的大小,從而網絡能夠同時捕獲全局和細節特征。分割網絡參考圖像語義分割的網絡設計,利用插值卷積做降采樣。在三維物體識別,分割以及室內場景分割的數據集上,我們均取得了領先于其他方法的性能。
(三)面向AR/VR場景的人體感知與生成
-
代表性論文:《深入研究用于無限制圖片3D人體重建中的混合標注》
雖然計算機視覺研究者在單目3D人體重建方面已經取得長足進步,但對無限制圖片進行3D人體重建依然是一個挑戰。主要原因是在無限制圖片上很難取得高質量的3D標注。爲解決這個問題,之前的方法往往采用一種混合訓練的策略來利用多種不同的標注,其中既包括3D標注,也包括2D標注。雖然這些方法取得了不錯的效果,但是他們並沒有研究不同標注對于這個任務的有效程度。
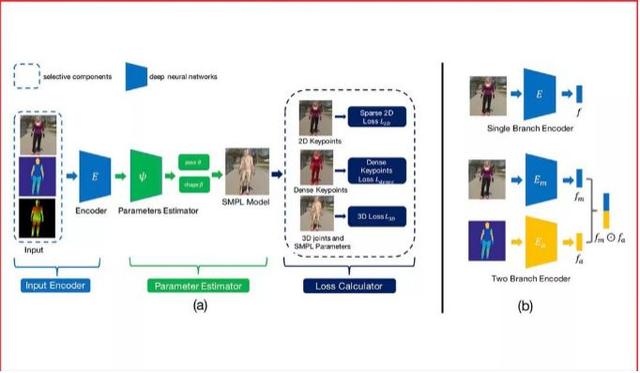
本篇論文的目標就是詳細地研究不同種類標注的投入産出比。特別的,我們把目標定爲重建給定無限制圖片的3D人體。通過大量的實驗,我們得到以下結論:1.3D標注非常有效,同時傳統的2D標注,包括人體關鍵點和人體分割並不是非常有效。2.密集響應是非常有效的。當沒有成對的3D標注時,利用了密集響應的模型可以達到使用3D標注訓練的模型92%的效果。
-
代表性論文:《基于卷積網絡的人體骨骼序列生成》
現有的計算機視覺技術以及圖形學技術已經可以生成或者渲染出栩栩如生的影像片段。在這些方法中,人體骨骼序列的驅動是不可缺少的。高質量的骨骼序列要麽使用動作捕捉設備從人身上獲取,要麽由動作設計師手工制作。而讓計算機代爲完成這些動作,高效地生成豐富、生動、穩定、長時間的骨骼序列,就是這一工作的目標。
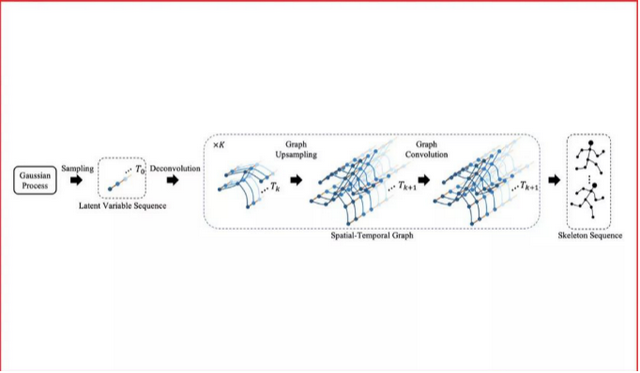
本文使用高斯過程産生隨機序列,使用對抗網絡和時空圖卷積網絡來學習隨機序列和動作序列之間的映射關系。該方法既可以産生動作序列,也可將動作序列映射到隨機序列所在的空間,並利用高斯過程進行編輯、合成、補全。
本方法在由真人動作捕捉得到的NTU-RGB+D數據集上,以及我們收集的虛擬歌手“初音未來”的大量舞蹈設計動作上,完成了詳細的對比實驗。實驗表明,相對于傳統的自回歸模型(Autoregressive Model),本文使用的圖卷積網絡可以大大提高生成的質量和多樣性。
(四)面向全場景理解的多模態分析
-
代表性論文:《基于圖匹配的電影視頻跨模態檢索框架》
電影視頻檢索在日常生活中擁有極大需求。例如,人們在浏覽某部電影的文字簡介時,時常會被其中的精彩部分吸引而想要看相應的片段。但是,通過文字描述檢索電影片段目前還存在許多挑戰。相比于日常生活中普通人拍攝的短視頻,電影有著極大的不同:1.電影是以小時爲單位的長視頻,時序結構很複雜。2.電影中角色的互動是構成故事情節的關鍵元素。因此,我們利用了電影的這兩種內在結構設計了新的算法來匹配文本段落與電影片段,進而達到根據文本檢索電影片段的目標。

首先,我們提出事件流模塊以建模電影的時序特性。該模塊基于二分圖匹配,將文本中的每一句話按照事件與電影片段的對應子片段匹配。其次,我們提出人物互動模塊,該模塊通過圖匹配算法計算文本中解析得到的人物互動圖和視頻中提取的人物互動圖的相似度。綜合兩個模塊的結果,我們能得到與傳統方法相比更精准的匹配結果,從而提高檢索的正確率。
-
代表性論文:《融合視覺信息的音頻修複》
多模態融合是交互智能發展的重要途徑。在多媒體信息中,一段音頻信號可能被噪聲汙染或在通信中丟失,從而需要進行修複。本文我們提出依據視頻信息對缺失音頻信息進行修複的一種融合視覺信息的音頻修複方案。
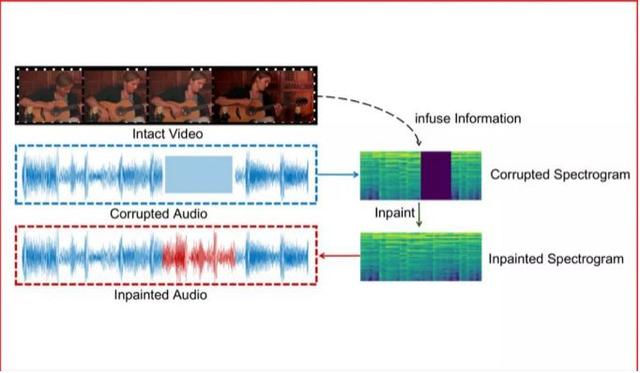
此方案核心思想在于:1.將音頻信號在頻譜上進行操作,並將頻譜作爲二維圖像信號進行處理,可以極大地利用計算機視覺領域的優勢,超越傳統的音頻解決方案。2.爲了融合視覺信息,基于音視頻同步學習得到的聯合子空間會發揮巨大的優勢。
針對此問題的研究,我們將已有的多模態樂器演奏數據集MUSIC擴大成爲一個新的更全面的數據集,MUSICES。實驗證明我們提出的視覺融合的音頻修複系統可以在沒有視頻信息注入的情況下取得可觀的效果,並在加入視頻信息後,生成與視頻和諧的音頻片段。

商湯科技獲 13 項競賽冠軍
除了論文工作取得的突破性成績,商湯在 Open Images、COCO、LVIS 等 13 項競賽中奪冠。
在 Google AI 主辦的 ICCV 2019 Open Images 比賽中,來自香港中文大學和商湯研究院的聯合團隊奪得了物體檢測和實例分割兩個主要賽道的冠軍。此次主辦方提供了千萬級別的實例框,涵蓋了 500 類結構性類別,其中包含大量漏標、類別混淆和長尾分布等問題。競賽中,得益于團隊提出的兩個全新技術:頭部空間解耦檢測器(Spatial Decoupling Head)和模型自動融合技術(Auto Ensemble)。前者可以令任意單模型在 COCO 和 Open Images 上提升 3~4 個點的 mAP,後者相對于樸素模型融合能提升 0.9mAP。
在 ICCV 2019 COCO 比賽中,來自香港中文大學-商湯科技聯合實驗室和南洋理工大學-商湯科技聯合實驗室的 MMDet 團隊獲得目標檢測(Object Detection)冠軍(不使用外部數據集),這也是商湯連續兩屆在COCO Detection項目中奪冠。同時,商湯科技新加坡研究團隊也獲得COCO全景分割(Panoptic)冠軍(不使用外部數據集)。
COCO比賽中,MMDet團隊提出了兩種新的方法來提升算法性能。針對于當前目標框定位不夠精確的缺陷,MMDet團隊提出了一種解耦的邊緣感知的目標框定位算法(Decoupled Boundary-Aware Localization <DBAL>),該方法專注于物體邊緣的信息而非物體全局的信息,使用一種從粗略估計到精確定位的定位流程,在主流的物體檢測方法上取得了顯著的提升。
而商湯科技新加坡研究團隊深入探索了全景分割任務的獨特性質,並提出了多項創新算法。由于全景分割任務既涵蓋目標檢測又包含語義分割,往屆比賽隊伍大多分別提升目標檢測算法與語義分割算法。商湯新加坡研究團隊打破慣例,探索了這兩項任務的互補性,提出了一種簡單高效的聯合訓練模型Panoptic-HTC。該模型分別借助Panoptic-FPN共享權重的特點與Hybrid Task Cascade聯合訓練的優勢,在特征層面完成了兩項視覺任務的統一,從而同時在兩項任務上獲得顯著提升。
在 Facebook AI Research 主辦的第一屆 LVIS Challenge 2019 大規模實例分割比賽中,來自商湯科技研究院團隊獲得了冠軍,同時獲得該項目最佳論文獎。相比于以往的實例分割數據集,LVIS 最大的特點在于超過 1000 多類的類別和更加接近于自然存在的數據長尾分布。這些特點對現有的實例分割算法提出了非常大的挑戰。商湯研究團隊從原有模型訓練的監督方式進行分析,針對長尾問題提出了一種新的損失函數,能夠有效的緩解頻率高的類別對小樣本類別的影響,從而大大提升了處于長尾分布中小樣本的性能。另外還通過對額外的檢測數據進行有效的利用,減少了因爲 LVIS 數據集構建方式中帶來的標注不完全問題,從而進一步提升了性能。
此外,在 Facebook AI Research 主辦的 ICCV 2019 自監督學習比賽中,來自香港中文大學-商湯科技聯合實驗室和南洋理工大學-商湯科技聯合實驗室團隊一舉獲得了全部四個賽道冠軍;在 MIT 主辦的 ICCV 2019 Multi-Moments In Time Challenge 比賽中,來自香港中文大學和商湯研究院的聯合團隊奪得了多標簽視頻分類賽道的冠軍;在 Insight Face 主辦的 ICCV 2019 Lightweight Face Recognition Challenge 比賽中,來自香港中文大學和商湯研究院的聯合團隊奪得了大模型-視頻人臉識別的冠軍;在 ETH 舉辦的 ICCV AIM 2019 Video Temporal Super-Resolution Challenge 比賽中,商湯科技團隊獲得了冠軍;在視覺目標跟蹤領域國際權威比賽 VOT2019 Challenge 比賽中,來自商湯科技團隊獲得 VOT-RT 2019 實時目標跟蹤挑戰賽冠軍。
【END】