編輯:好困
【新智元導讀】想當年,玩兒轉Dota 2的OpenAI Five訓練起來竟然需要超過5萬核CPU。就在昨天,顔水成團隊公開了最新的強化學習訓練環境引擎,256核CPU的運行速度直接達到1秒1百萬幀!就連筆記本上的i7-8750H也能有5萬幀每秒。
近年來,深度強化學習(Deep RL)取得了飛速的進展,有很多影響深遠的工作:從發表在Nature 2015的DQN,到後來打敗李世石、柯潔等世界冠軍的AlphaGo系列,再到複雜遊戲:代表星際的AlphaStar和Dota 2的OpenAI Five。
除了算法上的進步之外,最重要的是近年來對于深度強化學習智能體的訓練速度及吞吐量的巨大改進,當年的DQN跑簡單的Atari遊戲都要花費一周多的時間,而現在RL系統已經能承載非常高的吞吐量,能在複雜的遊戲和場景中訓練起來。
世界上目前最大型的強化學習訓練系統都是采取分布式訓練方法,比如OpenAI Five,使用了超過5萬核CPU,以及上千個GPU來進行訓練。
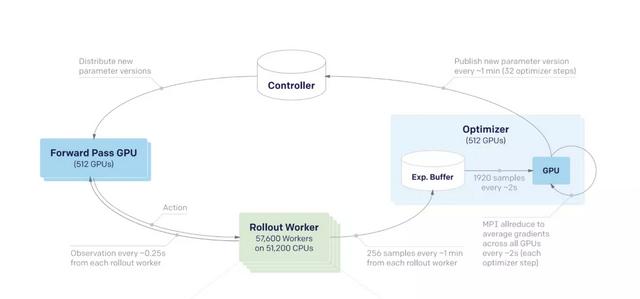
OpenAI Five
類似的,AlphaStar裏每個訓練智能體都連接著同時跑的1萬多場星際遊戲引擎。爲了下遊從遊戲交互數據中叠代學習的訓練速度,在這些訓練系統中都不得不使用大量的CPU資源來跑RL環境遊戲引擎。
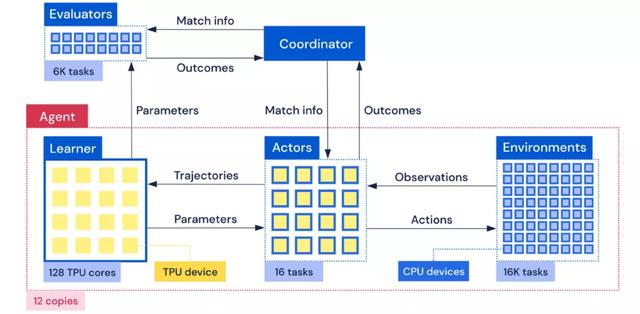
AlphaStar
如此大的資源消耗令大型強化學習訓練系統門檻非常高,學術界有限的資源難以在大型遊戲或者複雜的RL環境進行研究,不僅學術界,一個實現萬核CPU級別的用量在工業界研究院也是不小的負擔。
Sea AI Lab的研究人員注意到RL環境,包括遊戲引擎,是整個RL訓練系統裏面最慢的部分,而且處于數據供應端的位置,決定了整個系統吞吐量的上限。
然而這一部件並沒有得到研究人員的足夠重視,目前最常用的並行執行RL環境的辦法是gym.vector_env,即使用Python多進程來進行簡單的訓練環境並行,使用起來接口能保持不變,可是由于Python的局限性,最後爲了達到很高的吞吐量,只能使用更多的CPU資源來進行環境的模擬。

爲了提高RL環境的模擬性能及CPU利用效率,Sea AI Lab提供了一個高度並行的RL環境引擎解決方案EnvPool。
這個RL環境引擎底層使用C++線程池,通過異步的方式執行多個RL環境實例,來大大加速並行的效率。EnvPool在經典的RL環境模擬器Atari遊戲上,利用起NVIDIA DGX A100單機上的256個CPU核,達到了驚人的一百萬幀每秒的執行速度。

EnvPool系統概述
如此之高的吞吐量是研究人員最常用的執行引擎gym.vector_env的近14倍。這意味著我們能用同樣的硬件資源達到一個數量級差別的資源利用效率,或者反過來,使用了EnvPool可以少用一個數量級的資源數量且能達到極高的吞吐量。
對于研究人員來說,EnvPool提供了方便易用的Python接口,如下圖所示,最簡單的同步執行模式的接口與Gym API完全一致,相比單環境的gym/dm_env, EnvPool僅僅將原本與單個環境交互的API拓展到批量交互。
批量獲取的state方便算法端直接將數據送往GPU上進行inference,這樣下來算法端的實現難度也大大降低,從環境端出來的數據直接已經是批量的適合GPU和TPU處理的格式,能更好的利用GPU/TPU的並行效率。

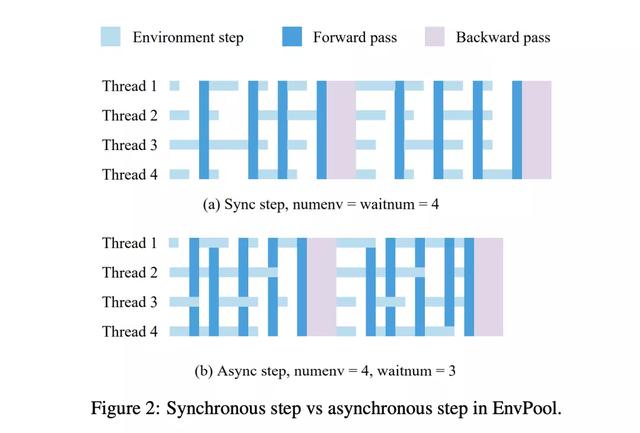
在異步模式下,EnvPool將原有的step函數拆分成send和recv函數,在調用send函數將action送往環境之後,線程無需等待當前交互的環境返回新的state,而是交由EnvPool在線程池中執行。
完成執行的環境會將新的state放入隊列,通過recv函數來批量獲取。相比同步模式,異步模式需要提供環境總數,以及每次交互的批大小。

異步的方式下,算法和環境可以有效的在時間上重合,無需相互等待。
Sea AI Lab的研究員在兩種不同的機器型號上評測對比了EnvPool及別的RL環境執行引擎的吞吐量,分別是TPU v3-8虛擬機, 以及NVIDIA DGX-A100機型。TPU虛擬機上有96 CPU cores,兩個NUMA節點,一台NVIDIA DGX-A100機子有256 CPU核, 8 NUMA nodes.
與EnvPool對比的RL環境模擬系統包括簡易的Python for-loop的多環境執行,業界最常用的gym.vector_env,以及去年剛發布的據研究人員所知的之前最快的環境模擬系統Sample Factory。

DGX-100

TPU-VM
由結果可見,在不同的機型上,使用不同數量的worker,EnvPool都具有非常大的優勢,特別是在NVIDIA DGX A100上,使用同樣的256個CPU核,EnvPool的性能達到了市面上最常用的gym.vector_env的13.3倍,並且達到了驚人的一百萬幀每秒的運行速度。這個吞吐量下,産生10^9幀(10億)數據僅需要17分鍾。
在相對少資源的設置下,EnvPool表現也十分的優異,在12核的情況下使用gym.vector_env運行Atari僅能達到1.8萬幀每秒的速度,而EnvPool可以更有效地利用CPU起來,達到5萬幀每秒,是這個廣爲使用的基准的約3倍。
項目簡介
研發團隊Sea AI Lab (SAIL)隸屬于新加坡冬海(SEA)集團,成立于2020年末,由顔水成挂帥,專注于前沿突破性基礎研究。
目前,EnvPool已經在GitHub上開源。
https://github.com/sail-sg/envpool
這已經是內部叠代的第二版,對比第一版的內部實現,開源的第二版著眼于簡化開發者API,也就是更加方便社區開發者接入不同的遊戲或者RL訓練環境。
接入C++引擎時,開發者只需要定義好單個環境的執行邏輯,EnvPool則負責分布式執行並且提供批交互的API,這使得接入新的RL環境及遊戲引擎並得到立刻的並行加速變得非常的簡單。
目前EnvPool在進行高度開發,接下來的核心更新包括接入更多的RL環境(包括連續動作空間的近期宣布免費使用的Mujoco),及會提供樣例讓用戶能很方便地利用EnvPool加速現有的開源RL訓練庫,包括接入DeepMind的Acme,以及接入EnvPool同一第一作者的大受歡迎的RL訓練庫天授Tianshou。
此外,EnvPool的成果也被邀請到NVIDIA GTC 2021大會上演講。
參考資料:
https://github.com/sail-sg/envpool
GTC 2021演講:
https://events.rainfocus.com/widget/nvidia/nvidiagtc/sessioncatalog/session/1630239583490001Z5dE