允中 發自 凹非寺
量子位 編輯 | 公衆號 QbitAI
你走進澡堂,霧氣彌漫。眼睛看到的人影模模糊糊。既看不清楚細節,也不知道是誰,只能看到大概輪廓。
你覺得手足無措,一分鍾都不想待在那裏。
你看到的情景,就是聽障人士在真實世界裏聽到的情況。霧氣相當于他們聽到的嘈雜的聲音。所有聲音的細節統統丟失,聽到的人聲和音樂聲,都淹沒在一片非常濃厚嘈雜的噪音裏。
對我們健全人來說,一直在霧氣彌漫的場景裏看東西,可以想象多麽痛苦。對于聽障人士而言,他們一輩子,7×24小時,都被困在了這樣的環境裏。
“如果能幫助他們,讓他們聽得見、聽得清、聽得真,聽到我們健全人能聽見的聲音,那真是一件非常有意義的事情。”騰訊多媒體實驗室高級總監商世東表示。
剛過去的9月27日,國際聾人日當天,騰訊多媒體實驗室聯合騰訊公益慈善基金會、深圳市信息無障礙研究會等機構召開發布會,宣布發起“天籁行動”——面向公益開發者、設備廠商、相關機構開放騰訊天籁AI音頻技術,應用于聽障人群無障礙建設等相關社會責任領域。
天籁行動,是騰訊“科技向善”的一次最新實踐。從2019年11月11日開始,騰訊將“科技向善”寫進公司最新的使命與願景之中。
科技與人類的關系,在近年越發受到關注和討論。事實上,不只騰訊,諸多科技公司都開始重視和強調用好科技,以科技爲善:騰訊強調“科技向善”,華爲強調“科技至善”。
如何讓“科技向善”不是一句簡單的口號,更要真正成爲一個持續落地的使命。其背後的驅動機制,來自科技公司的技術外溢與産品力,帶來持續不斷的技術進步、産品落地和公益體系化建設。
騰訊天籁行動,正是這一科技向善機制的典型體現。騰訊分三步,實現了用AI幫助聽障人士的科技實踐:釋放20余年音頻技術積累,以産品力將技術落地于聽障人群,爲不同定制化場景研發針對性降噪解決方案。最終實現將人工耳蝸語音清晰度和識別度提升40%,極大改善聽障人士的聽覺體驗,讓他們“聽得見”,更“聽得清”。
1、從技術,到場景
優秀的技術研究團隊,都有一個共同的特質:喜歡迎接未知的挑戰,不斷突破;越是遇到棘手的挑戰,就會越興奮。商世東和他所在的騰訊多媒體實驗室,就是這樣一支團隊。
騰訊多媒體實驗室,是騰訊公司前沿技術實驗室之一,專注音視頻通信技術的前瞻性研究,最擅長語音增強和降噪技術。針對語音在嘈雜環境中的情況,他們把經典信號處理和機器學習技術融合在一起,加上聲學場景分析技術,打造了一套降噪解決方案。他們把降噪技術應用在包括騰訊會議等多個産品裏,經過各種場景,各種設備,各樣用戶的體驗和打磨,成功實現了國際領先的核心語音增強和降噪技術指標。
作爲一個專注聲音的研究團隊,商世東和同事們在公司的一些無障礙項目交流當中,不止一次接觸到聽障人群。他們對聲音的渴望,以及很多家庭爲了孩子獲得聽的權利,付出了很多常人無法想象的努力,他們的堅持和努力,讓人觸動。
“一開始,這個技術是用在健全人的通信當中。但其實聽障人員更需要語音增強和降噪技術,是用來解決他們聽得見、聽得懂的問題。”商世東說,”降噪技術對健全人是錦上添花,對聽障人士是雪中送炭。”
世界衛生組織(WHO)數據顯示,全球有約11億年輕人(12-35歲之間)面臨聽力損失的風險,約4.66億人患有殘疾性聽力損失。據第二次全國殘疾人抽樣調查結果顯示,我國有聽力殘疾患者2780萬人。而這2780萬聽障人士,通過科技填補自身缺陷的,不到5%。
商世東和騰訊多媒體實驗室的同事們決定,將降噪技術貢獻出來,提供給人工耳蝸廠商,讓他們可以把采集到的聲音信號進行降噪,幫助聽障人士擺脫噪音煩惱,聽到的幹淨得多、安靜得多的聲音世界。
但當他們試圖把技術運用到人工耳蝸場景時,商世東和團隊發現,他們遇到了前所未有的挑戰:技術不是拿過來就可以用的,他們需要真正了解,對人工耳蝸用戶來說,他們感到最痛的問題是什麽。
“技術應用必須要場景驅動。我們需要了解,什麽樣的場景,人工耳蝸用戶他們有最迫切的需要。” 商世東說。
“我們應該爲他們做點什麽?我們能爲他們做點什麽?”這是商世東和團隊討論最多的問題。
AI降噪技術需要在降噪和聽覺感受之間取得平衡——人們可以聽到一些場景聲音,但不能太吵;不是一點噪聲都沒有,但要能把噪聲能量控制在可接受的範圍之內。
商世東和團隊針對人工耳蝸的用戶痛點,展開了深入調研。他們發現,對于人工耳蝸用戶來說,有四類典型場景:第一類是音樂場景,他們想聽音樂或看電視。第二類是幹淨的純淨語音場景,例如在家裏只有跟家人的對話,沒有太多嘈雜的聲音。第三類是純噪聲的場景,比如戴著人工耳蝸的孩子想出去走一走,馬路上有噪聲,如果除了噪音什麽都聽不見就比較危險。第四類是帶噪的語音場景,比如他們走在嘈雜的街道上,還能聽得清,知道誰在跟他們講話。
第三和第四類場景,是人工耳蝸用戶們最痛的地方。沒有AI降噪技術之前,技術很多時候顧此失彼,把所有的聲音都放大了。他們在家裏跟家人對話能聽到,但是出去之後,有一些不想聽到的聲音就沒辦法屏蔽,特別吵。這時候又不能關掉人工耳蝸,否則什麽都聽不見了。
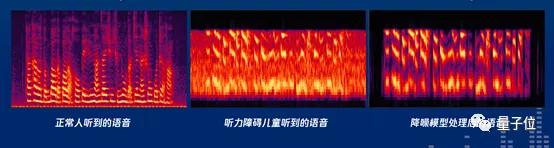
△ 聽障人士和健全人聽到的聲音波形對比
這個過程中最難的地方在于,如何判斷哪些是噪音,哪些是有用的背景音?你去聽一場交響樂,主旋律之外的鼓點、人們鼓掌的聲音,都是突發的聲音,機器很難判斷是噪音,還是音樂。技術很容易把噪聲識別成音樂。這給他們的研發進程帶來了很大困擾。
“機器對連續的音樂很容易判斷出來,但打擊樂混在裏面,機器很難講它是噪聲還是什麽。就像打個噴嚏,我們語音特征也會顯示是突發的噪聲。噪聲需要消除,但音樂不能消除,需要把音樂盡可能地保留住。” 商世東說。
爲了解決這個困難,騰訊多媒體實驗室針對性開發了針對人工耳蝸用戶的多場景識別技術。通過人工智能深度學習做場景分類,用戶常見的幾種場景都能准確識別。比如聽障兒童打電話的場景,聲音裏從電話裏出來,跟聲音從日常自然界出來又是不一樣的,這個技術能把電話場景進一步識別出來。
針對人工耳蝸用戶常見的4類聲學場景,騰訊多媒體實驗室在業界首次采用了基于深度學習的殘差網絡結構,在多尺度和多級別的網絡架構環境之下,對收集到的再造語音進一步的處理。多尺度的架構可以有效的區分上面顯示的4位的聲學場景,而多級別的網絡架構可以進一步區分易于混淆的代造和代造語言的場景。
經過這樣的處理,降噪技術總體上取得了96.2%的場景識別准確率。這個結果超過的人工標注的結果,爲下一步做進一步增強和語音處理奠定了紮實的基礎。
2、是技術,更是藝術
人工耳蝸雖然小,但是面臨的挑戰巨大。將降噪技術與聽障場景相結合,比起純技術研究的直線突破,更像一場“在針尖上起舞”的藝術。
商世東和團隊必須要解決一個兩難的應用問題:如何在極其有限的算力條件約束下,處理高複雜度的現實噪聲?
使用人工耳蝸的聽障用戶,聽到的聲音跟健全人聽到的聲音有很大區別。一個關鍵原因是,他們本身聽覺細胞比健全人要少得多。
15歲的曉婷,是廣東佛山的高一學生,也是這次天籁行動中的聽障用戶之一。曉婷在兩年前,裝上人工耳蝸,第一次聽到了這個世界的聲音。可她卻無法認出媽媽的聲音。在曉婷聽來,男人的聲音是低沉的,女人的聲音是尖細的,但她無法分辨每個人的聲音有什麽不同。
健全人有15000個聽覺細胞,能夠讓你聽到非常精細的,帶有非常豐富音頻細節的聲音。而聽障人群的聽覺細胞顯著低于健全人,可能只有幾千個、幾百個,甚至于最差的只有幾十個,對聲音的解析力不夠。所以他們聽到的聲音非常模糊,聽不清、聽不見。
助聽器和人工耳蝸,最主要的功能是把音量放大。但是在把音量放大的同時,把很多很多的環境噪聲也放大了。
人耳對噪聲非常敏感,不同頻段的敏感程度也不一樣。當把音量放大以後,健全人覺得並不是太吵的環境噪聲,比方說空調聲、風扇聲,或者是馬路上的聲音,聽障人士聽起來會覺得嘈雜得不得了。
經典的聲音處理,很難提升人工耳蝸對聽障人士帶來的聽覺體驗。經典聲音信號處理時,如果要達到很好的降噪效果,需要很強的計算能力。人工耳蝸是戴在耳朵上的,既要輕,又沒有電源(現在都是電池供電),所以運算能力非常有限。
當我們的電腦和手機達到主頻是GHz多核架構的時候,人工耳蝸由于尺寸限制,往往只能有幾十MHz的處理能力。在這樣的處理能力條件下,需要高複雜度的噪聲處理成爲了業界的難點,爲了克服這個難點,很多公司在進行這方面的研究,但一直沒有突破。

△ 人工耳蝸原理圖
今年年初,商世東和團隊找到了國內最大人工耳蝸廠商之一諾爾康公司。他們一起反複探討,在現有的軟硬件資源局限條件之下,如何幫助人工耳蝸的佩戴者有更好的體驗。
經過反複討論和技術驗證,他們最終確定了手機伴侶APP加人工耳蝸的聯合優化方案。在手機上,通過手機強大的語音處理和采集能力,對采集到的語音進行場景識別和場景有針對性的降噪和增量處理。針對處理過的語音,通過有線或者無線的方式發送到人工耳蝸,人工耳蝸可以進一步刺激相應的聽覺神經,有效的改善聽覺體驗的效果。
針對噪聲消除,騰訊多媒體實驗室有效融合了經典數字信號處理和深度學習技術。經典數字信號處理在解決平穩噪聲上有獨特的優勢,計算複雜較低,但處理日常生活中的非頻率噪聲往往力不從心。而深度學習技術有非常優秀的特征建模能力,可以針對日常生活中的各種噪聲進行准確的建模,從而有效預除生活中突發的噪聲,但深度學習的缺點在于運算量複雜。爲了進一步降低運算複雜度,他們采用了多種輔助訓練方法,並把訓練後的模型進一步量化處理,把運算複雜度有效的降低到1兆尺寸以下,解決了低功耗的手機終端上運行降噪處理的難題。
考慮到手機上多麥克風的情況,騰訊多媒體實驗室進一步采用了以前在雷達以及智能天線領域使用的波束形成技術,進一步輔助降噪和語音的正常的處理,有效對特定方向的語音進行針對性加強,同時濾除非特定方向的幹擾人聲以及環境噪聲。
通過使用多尺度、多級別的人工智能機器學習模型,商世東和團隊爲不同定制化場景研發了更有針對性的、更優的降噪解決方案,針對場景的識別率從60%提升到平均96%。經過多種技術的整合和處理,有效提升了聽障人士在各種溝通場景之下的效率,幫助消除他們不想聽到的聲音。
試戴新一代人工耳蝸第一天,曉婷和媽媽一起去公園,突然聽見了從來沒有聽過的聲音。媽媽告訴她,這是鳥叫。她說:“媽媽,是兩只鳥的聲音。”媽媽驚訝了。她從來沒有想到,曉婷不僅能夠聽清鳥叫,還能辨認出是兩只鳥的叫聲。

△ 騰訊多媒體實驗室發布天籁行動,用AI技術幫助聽障人士
3、騰訊的“技術外溢”與産品力
值得注意的是,天籁行動並非騰訊偶然一次心血來潮的公益實踐。它是騰訊基于“科技向善”的價值觀,進行體系化、持續性建設的公益産品落地之一。其背後的驅動機制,正是騰訊技術積累的“技術外溢”,以及將技術快速場景化落地的強大産品力。
“天籁行動”之所以能達到顯著的語音增強和降噪效果,既源自于騰訊多媒體實驗室多年的技術積累,尤其是在多媒體方向上的投入,也得益于騰訊內部衆多産品的豐富場景應用、快速叠代創新。
騰訊多媒體實驗室過往20年開發的音頻技術,用在了騰訊QQ,騰訊課堂、騰訊語音等多個産品上,服務于全球最大的體量客戶。
最近的一個例子是騰訊會議的實踐。作爲一款上市不到一年的産品,騰訊會議的用戶數已經突破了1億。其快速增長背後,是新一代實時音頻技術加持——爲騰訊用戶在使用過程中提供高清、流暢、沉浸的音頻通訊體驗,解決在音視頻場景裏所碰到的挑戰。這個技術就是應用于人工耳蝸的騰訊天籁。
不同技術互相取長補短,才能有更好的體驗。爲此,騰訊多媒體實驗室組建了一支多元化的技術團隊。商世東20多年一直在研究音頻技術方向,團隊裏成員的背景也相當豐富:技術領域有偏重于聲學的,有偏重于算法的,有偏重于機器學習的,有偏重經典信號處理的。專業背景既有中國頂尖高校,如中科大、北大等畢業的博士生加入,也招募了很多國際知名的人才加盟,包括來自新加坡國立大學、澳大利亞西澳大學,還有在德國工作多年的經典數字信號處理方面的專業人才……團隊成員相互合作,技術融合創新,一塊打磨音頻體驗。
同時,騰訊發揮自身的産品力優勢,將前沿技術應用到“無障礙”、AI尋人等多項公益産品中,爲信息無障礙貢獻力量,持續爲社會創造價值。
從2009年開始,騰訊的QQ、微信等産品,先後針對視障等用戶進行了體驗優化,開發了“無障礙”版本,讓他們通過“聽”也能使用,這些應用也成爲他們離不開的生活伴侶。
2018年,QQ空間啓動了“無障礙AI技術”開放項目,將OCR文字識別、語音合成、圖片轉語音等無障礙AI技術,通過小程序開放,企業、開發者可以免費接入。
2019年,優圖實驗室利用深度學習技術,突破“跨年齡人臉識別”技術,助力警方尋回多名被拐十年的兒童,幫助更多的家庭得以團聚。

△ 騰訊優圖實驗室利用人工智能(AI)深度學習技術,突破“跨年齡人臉識別”
今年,騰訊多媒體實驗室將“新一代實時音頻技術”——騰訊天籁,應用在人工耳蝸上。天籁行動不算驚天動地,但解決的問題存在很大技術挑戰,過去不少嘗試都沒有成功。騰訊爲什麽能做到?因爲騰訊具備了三點關鍵——騰訊20余年在音視頻技術領域的積累,擅于將技術場景化落地的産品力,“科技向善”的情懷。
而這三點,也正保證了騰訊未來能持續實踐“科技向善”價值觀:堅持從用戶價值出發,通過科技應用、場景創新,不斷解決社會難題。
“我們要做到‘AI向善’,就要努力讓人工智能實現‘可知、可控、可用、可靠’。這是全世界共同面對的課題。”騰訊公司董事會主席兼CEO馬化騰表示,“騰訊把‘科技向善’納入公司的使命和願景,我們每天都在研究和應用新科技,歸根到底要爲每一位用戶負責。”
— 完 —
量子位 QbitAI · 頭條號簽約
關注我們,第一時間獲知前沿科技動態