機器之心發布
機器之心編輯部
2020 年 2 月 7 日-2 月 12 日,AAAI 2020 將于美國紐約舉辦。不久之前,大會官方公布了今年的論文收錄信息:收到 8800 篇提交論文,評審了 7737 篇,接收 1591 篇,接收率 20.6%。本文介紹了滴滴 AI Labs 與美國東北大學合作的一篇論文《AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates》
近年來,隨著深度神經網絡模型性能不斷刷新,模型的骨幹網絡參數量愈發龐大,存儲和計算代價不斷提高,從而導致難以部署在資源受限的嵌入式平台上。滴滴 AI Labs 與美國東北大學王言治教授研究組合作,聯合提出了一種基于 AutoML 思想的自動結構化剪枝的算法框架 AutoCompress,能自動化的去尋找深度模型剪枝中的超參數,去除模型中不同層的參數冗余,替代人工設計的過程並實現了超高的壓縮倍率。從而滿足嵌入式端上運行深度模型的實時性能需求。
相較之前方法的局限性,該方法提出三點創新性設計:
(1)提出混合型的結構化剪枝維度;(2)采用高效強大的神經網絡剪枝算法 ADMM(交替乘子優化算法)對訓練過程中的正則項進行動態更新;(3)利用了增強型引導啓發式搜索的方式進行行爲抽樣。在 CIFAR 和 ImageNet 數據集的大量測試表明 AutoCompress 的效果顯著超過各種神經網絡壓縮方法與框架。在相同准確率下,實際參數量的壓縮相對之前方法最大可以提高超 120 倍。

圖 1. 自動化超參數決策框架的通用流程,以及性能提升來源
爲了改進以上的不足,我們提出了神經網絡權重剪枝問題超參數設置自動化過程的通用流程(generic flow),如圖 1 所示。整個自動化通用流程主要可以分爲 4 步。步驟 1 爲行爲抽樣,步驟 2 爲快速評估,步驟 3 爲確定決策,步驟 4 爲剪枝操作。
由于超參數的巨大搜索空間,步驟 1 和步驟 2 應該快速進行,因此無法進行再訓練(re-training)後去評估其效果。因此根據量級最小的一部分權重直接進行剪枝評估。步驟 3 根據工作抽樣和評估的集合對超參數進行決策。步驟 4 利用剪枝核心算法對模型進行結構化剪枝並生成結果。
基于上述通用流程,並針對之前方法的局限性,進一步提出如下三點創新性設計,通過綜合現有的深度神經網絡與機器學習框架首次實現了目前最高效的深度神經網絡自動化結構化剪枝的通用框架 AutoCompress。該框架在滴滴已經得到了實際有效應用。
基于神經網絡自動化結構化剪枝框架
三點創新性設計爲:(1)提出混合型的結構化剪枝維度;(2)采用高效強大的神經網絡剪枝算法 ADMM(交替乘子優化算法)對訓練過程中的正則項進行動態更新;(3)利用了增強型引導啓發式搜索的方式進行行爲抽樣。

圖 3. AutoCompress 框架示意圖
基于上述三點創新性設計,我們搭建了 AutoCompress 框架,如圖 3 所示。通過基于啓發式搜索算法的自動化代理模塊的指導,AutoCompress 框架進行模型自動化剪枝主要分爲兩個步驟,步驟 1:通過基于 ADMM 算法的結構化剪枝,得到權重分布結構性稀疏化的模型;步驟 2:通過網絡結構淨化(Purification)操作,將 ADMM 過程中無法完全刪除的一小部分冗余權重找到並刪除。值得注意的是,這兩個步驟都是基于相同的啓發式搜索機制。
啓發式搜索機制
針對 AutoCompress 中最核心的搜索算法設計,我們利用了搜索算法中的模擬退火算法爲搜索算法的核心。舉例來講,給定一個原始模型,我們會設置兩種目標函數 — 根據權重數量設置或根據運算量(FLOPs)設置。搜索過程進行若幹輪,比如第一輪目標爲壓縮兩倍權重數量,第二輪爲壓縮四倍權重數量。在每一輪搜索過程中,首先初始化一個行爲(超參數),然後每次對行爲進行一個擾動(超參數的小幅變化)生成新的行爲,根據模擬退火算法原理,評估兩個行爲,如果新的行爲評估結果優于原結果則接受該行爲,如果新的行爲評估結果劣于原結果則以一定概率接受該行爲。每一輪算法中的溫度參數 T 會下降,直到 T 下降到某個阈值後即停止搜索,該結果即爲圖 1 中的步驟 3 輸出。最後,根據搜索得到的超參數,對神經網絡進行結構化剪枝操作。
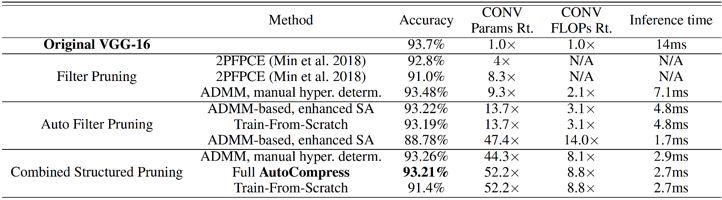
表 2. 在 ResNet-18 (NISP 和 AMC 結果爲 ResNet-50) 上基于 CIFAR-10 數據集的權重剪枝對比結果。

表 4. 在 ResNet-18/50 上基于 ImageNet 數據集的結構化權重剪枝對比結果。