在深入學習字符串類之前, 我們先搞懂JVM是怎樣處理新生字符串的. 當你知道字符串的初始化細節後, 再去寫String s = “hello”或String s = new String(“hello”)等代碼時, 就能做到心中有數。
首先得搞懂字符串常量池的概念。
常量池是Java的一項技術, 八種基礎數據類型除了float和double都實現了常量池技術. 這項技術從字面上是很好理解的: 把經常用到的數據存放在某塊內存中, 避免頻繁的數據創建與銷毀, 實現數據共享, 提高系統性能。
字符串常量池是Java常量池技術的一種實現, 在近代的JDK版本中(1.7後), 字符串常量池被實現在Java堆內存中。
下面通過三行代碼讓大家對字符串常量池建立初步認識:
public static void main(String[] args) { String s1 = “hello”; String s2 = new String(“hello”); System.out.println(s1 == s2); //false }
我們先來看看第一行代碼String s1 = “hello”;幹了什麽.
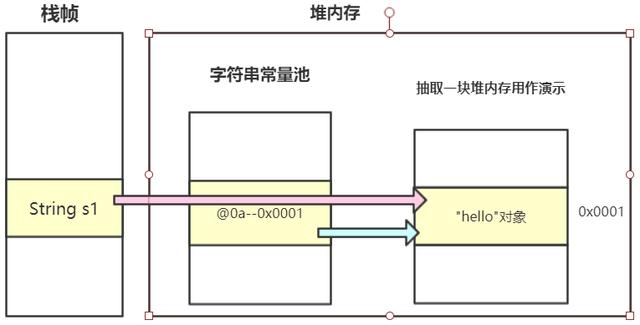
當我們使用new關鍵字創建字符串對象的時候, JVM將不會查詢字符串常量池, 它將會直接在堆內存中創建一個字符串對象, 並返回給所屬變量。
所以s1和s2指向的是兩個完全不同的對象, 判斷s1 == s2的時候會返回false。
如果上面的知識理解起來沒有問題的話, 下面看些難點的.
public static void main(String[] args) { String s1 = new String(“hello “) + new String(“world”); s1.intern(); String s2 = “hello world”; System.out.println(s1 == s2); //true }
第一行代碼String s1 = new String(“hello “) + new String(“world”);的執行過程是這樣子的:
1.依次在堆內存中創建”hello “和”world”兩個字符串對象
2.然後把它們拼接起來 (底層使用StringBuilder實現, 後面會帶大家讀反編譯代碼)
3.在拼接完成後會産生新的”hello world”對象, 這時變量s1指向新對象”hello world”
執行完第一行代碼後, 內存是這樣子的:
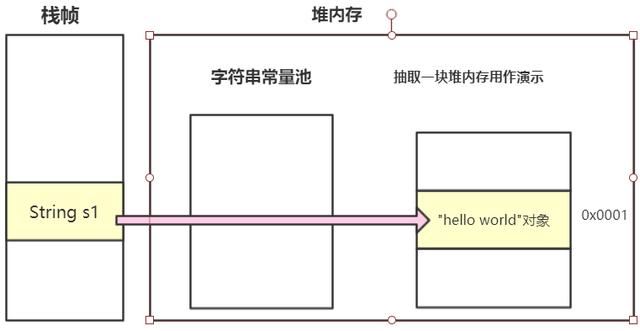
第三行代碼String s2 = “hello world”;
這種直接通過雙引號”“聲明字符串背後的運行機制我們在第一個案例提到過, 這裏正好複習一下。
首先虛擬機會去檢查字符串常量池, 發現有指向”hello world”的引用. 然後把該引用所指向的字符串直接返回給所屬變量。
執行完第三行代碼後, 內存示意圖如下: