
是n維空間中的一個二元組,S是由向量組成的集合,F是S中元素滿足的某種關系。那麽嵌入方法就是需要我們找到一個映射:
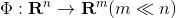
在
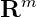
,記
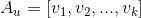
是最近操作過的),標的物
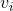
,那麽我們可以用如下方式來獲得用戶的嵌入表示
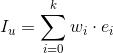
是標的物
,這時不同時間段的標的物權重是一樣的,也可以按照時間做等差或者等比的衰減,保證時間最近的標的物權重最大。
通過上面方法獲得了用戶對標的物的評分,計算出用戶與每個標的物的評分,按照評分降序排序取TopN作爲推薦列表(剔除用戶已經操作過的標的物)。
b. 通過用戶操作過的標的物的相似節目來爲用戶推薦
該方法可以將用戶最近操作過的標的物作爲種子標的物,將種子標的物最相似的N個標的物作爲推薦的候選集。具體如下:
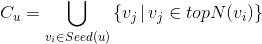
對(
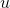
代表標的物)組成的集合爲
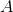
,通過矩陣分解將用戶
嵌入k維特征空間的嵌入向量分別爲:

那麽用戶
的預測評分爲
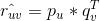
。如果預測得越准,那麽
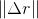
對,如果我們可以保證這些誤差之和盡量小,那麽有理由認爲我們的預測是精准的。
有了上面的分析,我們就可以將矩陣分解轉化爲一個機器學習問題。具體地說,我們可以將矩陣分解轉化爲如下等價的求最小值的最優化問題。
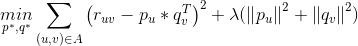
是超參數,可以通過交叉驗證等方式來確定,
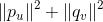
是有限詞彙表
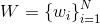
公式2:Word2Vec的目標函數
其中,c是詞
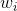
是下面的softmax函數:
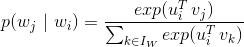
和
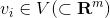
的目標(target)和上下文(context)嵌入表示,這裏
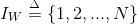
計算量太大,是詞庫大小N的線性函數,一般N是百萬級別以上。
我們可以通過負采樣(Negative Sampling)來減少計算量,具體來說,就是用如下的公式來代替上面的softmax函數。
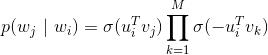
是logistic函數,M是采樣的負樣本(這裏負樣本是指抽樣的詞
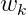
的上下文中)數量。
最終可以用隨機梯度下降算法來訓練公式2中的模型,估計出U 、V。讀者可以閱讀參考文獻1、2、3、4對Word2Vec進行深入學習和了解。
參考文獻12提出了一個CoFactor模型,將矩陣分解和Word2Vec(參考文獻27中證明Word2Vec嵌入等價于一類PMI矩陣的分解,本文作者也是采用的PMI分解的思路,而不是直接用Word2Vec)整合到一個模型中來學習嵌入並最終給用戶做推薦,也是一個非常不錯的思路。
參考文獻28借助Word2Vec的思路,提出了Prod2Vec模型,該算法利用發給用戶的電子郵件廣告數據,根據用戶的郵件點擊購買回執了解用戶的偏好行爲,通過將用戶的行爲序列等價爲詞序列,采用Word2Vec類似的方法進行嵌入學習獲得商品的嵌入向量,最終給用戶進行個性化推薦。該算法部署到線上,有9%點擊率的提升。參考文獻16基于Prod2Vec模型,提出了一種整合商品metadata等附加信息的Meta-Prod2Vec算法模型,提升了准確率,並且可以有效解決冷啓動問題,感興趣的讀者可以閱讀學習這兩篇文章。
有很多開源的軟件有Word2Vec的實現,比如Spark、gensim、TensorFlow、Pytorch等。我們公司采用的是gensim,使用下來效果不錯。
- 基于有向圖嵌入
給定一個圖
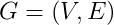
中的向量表示。利用數學的術語就是學習一個映射:
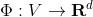
。
基于Word2Vec和參考文獻23的思路,我們可以先通過隨機遊走(random walk)生成圖頂點的序列,再利用Word2Vec的Skip-Gram算法學習每個頂點的向量表示。爲了保留圖的拓撲結構,我們需要求解如下的目標函數:
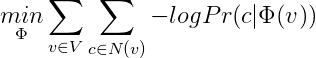
是給定一個頂點v,通過隨機遊走獲得v的一個鄰域頂點的概率。
有了上面的定義和說明,剩下的處理流程和思路跟Word2Vec是一樣的了,這裏不再贅述。
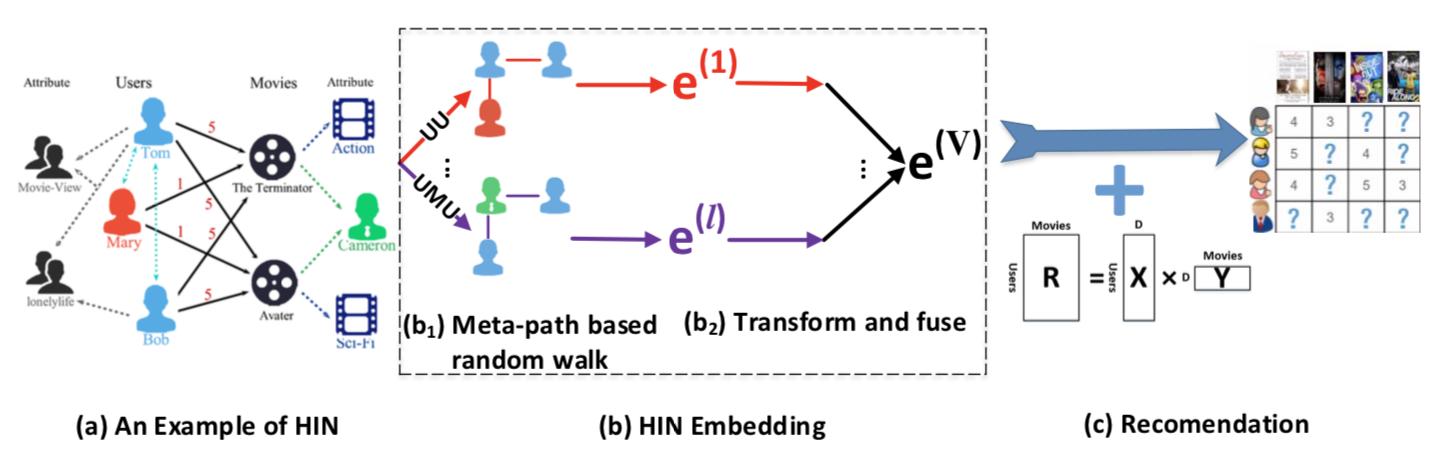
參考文獻6、19分別提供了基于圖嵌入進行個性化推薦的解決方案,其中6我們會在第四節4中詳細介紹。19提供了一個在異構信息網絡(Heterogeneous Information Network,簡寫爲HIN)中通過隨機遊走生成節點序列,再將節點序列嵌入低維空間,通過一組fusion函數變換後整合到矩陣分解模型中進行聯合訓練,通過求解聯合模型最終進行推薦的方法,該方法也可以有效地解決冷啓動問題,具體架構圖如下,感興趣的讀者可以參考原文。隨著互聯網的深入發展,異構信息網絡是一類非常重要的網絡,在當前的互聯網産品中(社交網絡産品、生活服務産品等)大量存在,基于HIN的個性化推薦也是未來一個比較火的方向之一。
其中u、v分別是用戶和視頻的嵌入向量。U是用戶集,C是上下文。該方法也是通過一個(深度學習)模型來一次性學習出用戶和視頻的嵌入向量。感興趣的讀者可以參考閱讀,我在下一篇文章《深度學習推薦算法》中會詳細講解該文章算法原理和核心思想。
四、嵌入方法在推薦系統中的應用案例介紹
上一節講解了4類用于推薦系統的嵌入方法,基于這4類方法,我們在本節介紹幾個有代表性的嵌入方法在推薦系統中的應用案例,讓大家可以更好地了解嵌入方法怎麽做推薦。這幾個案例都是在真實的工業級場景得到驗證的方法,值得大家學習和借鑒。
1.利用矩陣分解嵌入做推薦
通過第三節1的矩陣分解的介紹,當我們獲得了用戶和標的物嵌入後,我們計算出用戶u的嵌入向量與每個標的物嵌入向量的內積
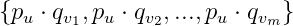
這裏不存在固定的窗口大小了,窗口的大小就是用戶操作過的標的物集合的大小。而其他部分跟Word2Vec的優化目標函數一模一樣。
最終用向量
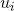
、
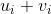
(
拼接在一起的向量)來表示標的物的嵌入。
我們公司也采用了item2vec算法來對視頻進行嵌入,用于視頻的相似推薦中,點擊率效果比原來的基于矩陣分解的嵌入有較大幅度的提升。
3.阿裏盒馬的聯合嵌入推薦模型
阿裏盒馬利用Word2Vec思想對不同類別的ID(item ID、product ID、brand ID、store ID等)進行聯合嵌入學習,獲得每個ID的嵌入表示,下面我們對該方法進行簡單介紹(見參考文獻7)。
給定一個item序列
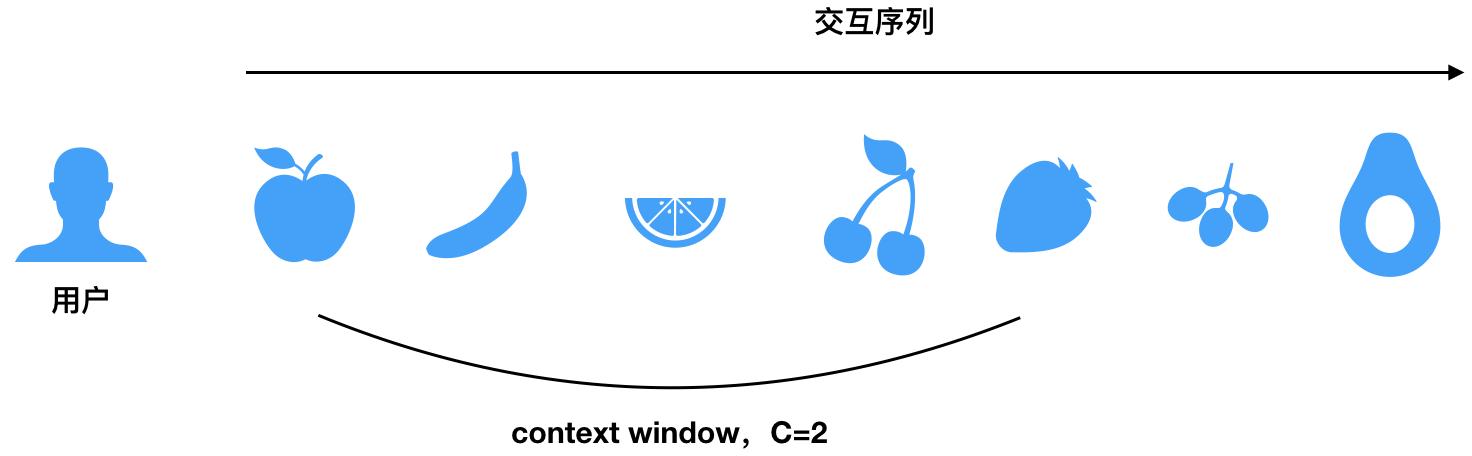
這裏C是上下文窗口的長度。下圖是某個用戶的浏覽序列,其中前5個浏覽記錄是一個session(用戶的一次交互序列,可以按照時間,比如按照一個小時切分,將用戶在APP上的操作分爲多個session)。
定義如下
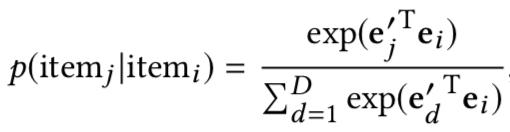
分別是item和context的嵌入表示,m是嵌入空間的維數,D是總的item數,也就是盒馬上的所有商品數量。
上述公式求導計算複雜度正比于D,往往D是非常大的,所以類似Word2Vec,可以采用如下的負采樣技術減少計算量
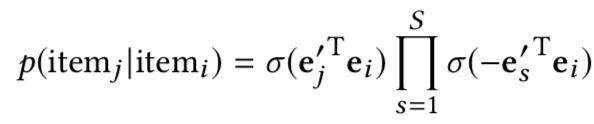
(item及其上下文之外的物品的分布)中抽取的負樣本的數量。
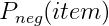
累積分布函數可以記爲
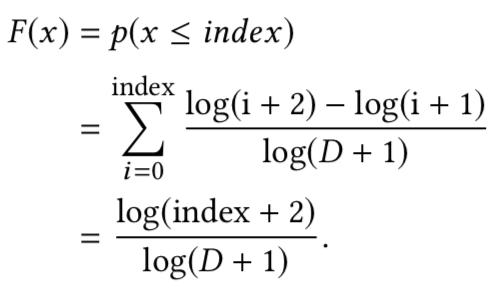
,這裏r是從均勻分布
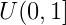
即負采樣可以先從
上圖是item ID和它的屬性ID之間的關聯關系,假設有K個ID,我們按照順序記爲
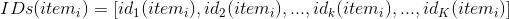
,而
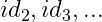
上式中,
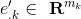
分別是第k個ID的context和target嵌入表示,
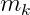
是
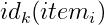
個不同的item(這個品牌包含
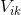
這裏
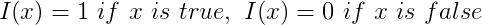
定義爲
舉例來說,我們始終有
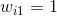
包含10個不同的item,那麽
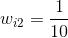
公式4:item的條件概率公式
這裏
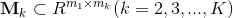
變換到與
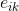
其中
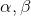
圖3:構建用戶行爲有向圖
(2) 圖嵌入
構建好有向圖後,我們就可以采用隨機遊走(參考文獻23的DeepWalk方法,參考文獻13、17、18提供了其他利用圖嵌入的方法,其中17、18提供了比其他圖嵌入方法更高效的實現方案,可以大大節省嵌入訓練的時間)的方式生成行爲序列(參見圖2中的c)。後面我們再用Skip-Gram算法學習圖的頂點(商品)的嵌入表示(參考圖2中d的Skip-Gram模型)。我們需要最大化通過隨機遊走生成序列中的兩個頂點同時出現的概率,具體來說,我們需要求解如下最優化問題:
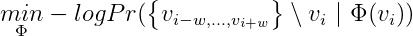
利用Word2Vec中提到的負采樣技術,最終的優化目標函數爲
是爲
是logistic函數,
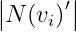
上式中,
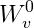
是附加信息的嵌入表示,我們假設商品嵌入和附加信息嵌入到相同維度的空間中,這樣才可以求平均。
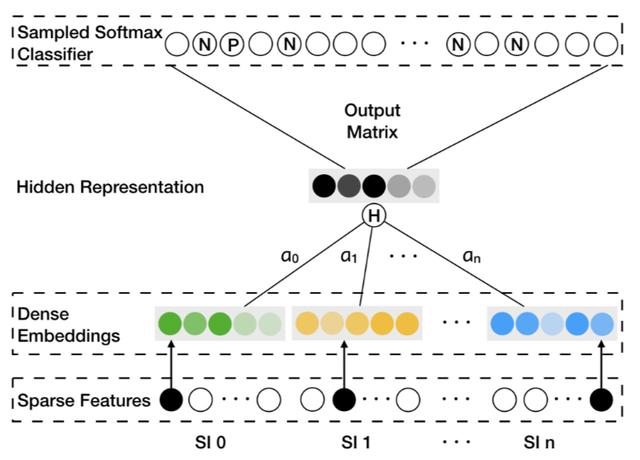
圖5:多源信息嵌入預測兩個商品被一起購買的概率
具體來說,該模型包含三個主要模塊:
(1) 內容嵌入模塊
通過不同的算法將商品不同維度的信息嵌入到低維空間中,這些不同源的信息嵌入過程是解耦合的、可插拔的,可以用不同的算法來取代。圖像嵌入可以用圖像分類的算法獲得(如AlexNet等),而文本的嵌入可以用Word2Vec獲得,協同信息的嵌入可以用矩陣分解算法獲得。
(2) 多源聯合嵌入模塊
該模塊將(1)不同源的商品信息嵌入向量,通過一個統一的模型獲得聯合嵌入表示。
(3) 輸出層
輸出層結合兩個商品的聯合嵌入向量,計算出這兩個商品被一起購買的概率。具體來說,兩個商品的聯合嵌入向量通過求內積,再經過sigmod函數變換獲得概率值。
通過上述方法可以獲得每個商品的嵌入向量,我們就可以用第二節1(3)中的第2個方法給用戶做推薦。
五、利用嵌入方法解決冷啓動問題
嵌入方法除了可以用于推薦外,通過整合附加信息(side information)到嵌入模型中,可以很好地解決冷啓動問題。我們知道基于內容的推薦可以緩解冷啓動問題,這些附加信息也一般是內容相關的信息,所以整合進嵌入模型中就可以用于解決冷啓動。下面我們簡單介紹4種通過嵌入解決冷啓動的案例。
1.通過在矩陣分解中整合內容相關信息解決冷啓動
參考文獻9中給出了一種在矩陣分解中整合用戶特征和標的物特征的方案,可以有效地解決用戶和標的物冷啓動問題。這篇文章我們在《矩陣分解推薦算法》第四節6中進行過介紹,這裏不再贅述。
2.通過不同ID間的結構鏈接關系及不同平台用戶的特征遷移來解決冷啓動
參考文獻7中,每個item ID會關聯對應的product ID、brand ID、store ID等,對于一個新的item來說,這個item所屬的産品、品牌或者店鋪可能會存在其他的item被用戶點擊購買過,那麽一種很自然的方式是用這個item關聯的其他ID的嵌入向量來構造該item的近似嵌入表示。
因爲
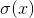
要想讓上式取值最大,當
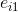
來近似item的嵌入。當然不是跟item ID關聯的所有ID都有嵌入,我們只需要選擇有嵌入的ID代入上式中即可。通過模型線上驗證,這種方式得到的嵌入效果還是很不錯的,可以很好地解決商品冷啓動問題。
同時,這篇文章中通過不同APP用戶特征的遷移可以解決用戶冷啓動,下面也做簡單介紹。
盒馬和淘寶都屬于阿裏的電商平台,淘寶通過這麽多年的發展已經覆蓋了絕大多數的用戶群,大部分盒馬的用戶其實也是淘寶的用戶,那麽對于盒馬上的新用戶,就可以用該用戶在淘寶上的特征,將特征遷移到盒馬上來,爲他做推薦。下面來簡要介紹推薦的流程與方法。
假設淘寶的用戶爲
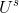
,他們的交集爲
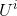
)。那麽按照下面流程就可以爲盒馬的新用戶做推薦了:
(1)采用第四節3的方案計算出淘寶平台上用戶的嵌入向量;
(2) 將
圖6:通過跨平台特征遷移來爲新用戶做推薦
3.通過在圖嵌入中整合附加信息解決冷啓動
我們在第四節4中已經說明了在有向圖嵌入構建Skip-Gram模型過程中整合附加信息可以解決冷啓動問題,這裏不再說明。
4.通過圖片、文本內容嵌入解決冷啓動問題
前面我們在第四節5中講解了Content2Vec模型,該模型通過將圖片、文本、類別等metadata信息嵌入,再將這些不同源的嵌入向量通過一個統一的模型獲得聯合嵌入表示,最終通過