選自towardsdatascience
作者:Robert Lucian Chiriac
機器之心編譯
參與:王子嘉、思、一鳴
閑來無事,我們給愛車裝了樹莓派,配了攝像頭、設計了客戶端,搞定了實時車牌檢測與識別系統。
怎樣在不換車的前提下打造一個智能車系統呢?一段時間以來,本文作者 Robert Lucian Chiriac 一直在思考讓車擁有探測和識別物體的能力。這個想法非常有意思,因爲我們已經見識過特斯拉的能力,雖然沒法馬上買一輛特斯拉(不得不提一下,Model 3 現在看起來越來越有吸引力了),但他有了一個主意,可以努力實現這一夢想。
所以,作者用樹莓派做到了,它放到車上可以實時檢測車牌。

放一張成品圖鎮樓。
第一步:確定項目範圍
開始之前,我腦海裏出現的第一個問題是這樣一個系統應該能夠做到什麽。如果說我活到現在學到了什麽,那就是循序漸進——從小處著手永遠是最好的策略。所以,除了基本的視覺任務,我需要的只是在開車時能清楚地識別車牌。這個識別過程包括兩個步驟:
- 檢測到車牌。
- 識別每個車牌邊界框內的文本。
我覺得如果我能完成這些任務,再做其他類似的任務(如確定碰撞風險、距離等)就會容易得多。我甚至可能可以創建一個向量空間來表示周圍的環境——想想都覺得酷。
在確定這些細節之前,我知道我得先做到:
- 一個機器學習模型,以未標記的圖像作爲輸入,從而檢測到車牌;
- 某種硬件。簡單地說,我需要連接了一個或多個攝像頭的計算機系統來調用我的模型。
那就先從第一件事開始吧——構建對象檢測模型。
第二步:選擇正確的模型
經過仔細研究,我決定用這些機器學習模型:
- YOLOv3- 這是當下最快的模型之一,而且跟其他 SOTA 模型的 mAP 相當。我們用這個模型來檢測物體;
- CRAFT 文本檢測器 – 我們用它來檢測圖像中的文本;
- CRNN – 簡單來說,它就是一個循環卷積神經網絡模型。爲了將檢測到的字符按照正確的順序排成單詞,它必須是時序數據;
這三個模型是怎麽通力合作的呢?下面說的就是操作流程了:
- 首先,YOLOv3 模型從攝像機處接收到一幀幀圖像,然後在每個幀中找到車牌的邊界框。這裏不建議使用非常精確的預測邊界框——邊界框比實際檢測對象大一些會更好。如果太擠,可能會影響到後續進程的性能;
- 文本檢測器接收 YOLOv3 裁剪過的車牌。這時,如果邊界框太小,那麽很有可能車牌文本的一部分也被裁掉了,這樣預測結果會慘不忍睹。但是當邊界框變大時,我們可以讓 CRAFT 模型檢測字母的位置,這樣每個字母的位置就可以非常精確;
- 最後,我們可以將每個單詞的邊界框從 CRAFT 傳遞到 CRNN 模型,以預測處實際單詞。
有了我的基本模型架構草圖,我可以開始轉戰硬件了。
第三步:設計硬件
當我發現我需要的是一種低功耗的硬件時,我想起了我的舊愛:樹莓派。因爲它有專屬相機 Pi Camera,也有足夠的計算能力在不錯的幀率下預處理各個幀。Pi Camera 是樹莓派(Raspberry Pi)的實體攝像機,而且有其成熟完整的庫。
爲了接入互聯網,我可以通過 EC25-E 的 4G 接入,我以前的一個項目裏也用過它的一個 GPS 模塊,詳情可見:
博客地址:https://www.robertlucian.com/2018/08/29/mobile-network-access-rpi/
然後我要開始設計外殼了——把它挂在汽車的後視鏡上應該沒問題,所以我最終設計了一個分爲兩部分的支撐結構:
- 在後視鏡的方向上,樹莓派+ GPS 模塊+ 4G 模塊將保留下來。關于我使用的 GPS 和 4G 天線,你可以去看一下我關于 EC25-E 模塊的文章;
- 在另一側,我用一個利用球關節活動的手臂來支撐 Pi Camera
我會用我可靠的 Prusa i3 MK3S 3D 打印機來打印這些零件,在原文文末也提供了 3D 打印參數。
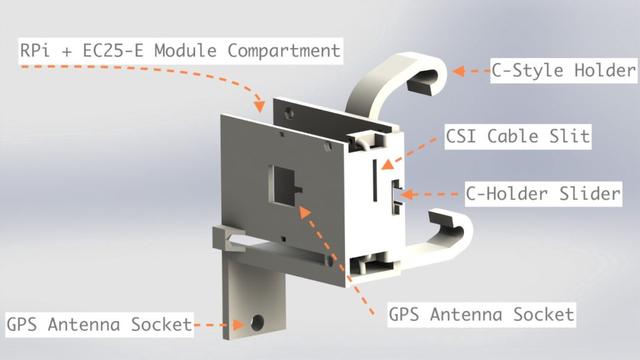
圖 2:利用球關節活動臂支撐 Pi Camera
圖 1 和圖 2 就是它們渲染時候的樣子。注意這裏的 c 型支架是可插拔的,所以樹莓派的附件和 Pi Camera 的支撐物沒有和支架一起打印出來。他們共享一個插座,插座上插著支架。如果某位讀者想要複現這個項目,這是非常有用的。他們只需要調整後視鏡上的支架就可以了。目前,這個底座在我的車(路虎 Freelander)上工作得很好。

圖 4:Pi Camera 支撐結構和 RPi 底座的正視圖
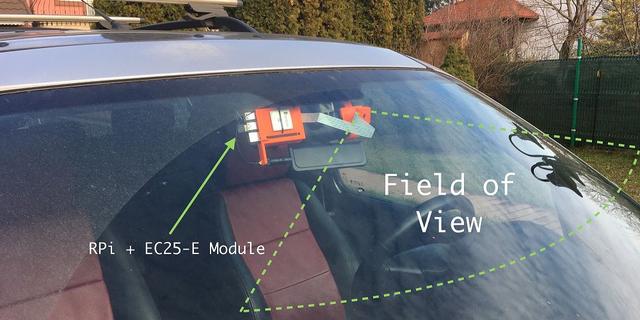
圖 6:內置 4G/GPS 模塊、Pi Camera,樹莓派的嵌入式系統近照
顯然,這些東西需要一些時間來建模,我需要做幾次才能得到堅固的結構。我使用的 PETG 材料每層高度爲 200 微米。PETG 在 80-90 攝氏度下可以很好地工作,並且對紫外線輻射的抵抗力很強——雖然沒有 ASA 好,但是也很強。
這是在 SolidWorks 中設計的,所以我所有的 SLDPRT/SLDASM 文件以及所有的 STLs 和 gcode 都可以在原文末找到。你也可以用這些東西來打印你自己的版本。
第四步:訓練模型
既然硬件解決了,就該開始訓練模型了。大家應該都知道,盡可能站在巨人的肩膀上工作。這就是遷移學習的核心內容了——先用非常大的數據集來學習,然後再利用這裏面學到的知識。
YOLOv3
我在網上找了很多預先訓練過的車牌模型,並沒有我最初預期的那麽多,但我找到了一個在 3600 張車牌圖上訓練過的。這個訓練集並不大,但也比什麽都沒有強。除此之外,它也是在 Darknet 的預訓練模型的基礎上進行訓練的,所以我可以直接用。
模型地址:https://github.com/ThorPham/License-plate-detection
因爲我已經有了一個可以記錄的硬件系統,所以我決定用我的系統在鎮上轉上幾個小時,收集新的視頻幀數據來對前面的模型進行微調。
我使用 VOTT 來對那些含有車牌的幀進行標注,最終創建了一個包含 534 張圖像的小數據集,這些圖像中的車牌都有標記好的邊界框。
數據集地址:https://github.com/RobertLucian/license-plate-dataset
然後我又找到利用 Keras 實現 YOLOv3 網絡的代碼,並用它來訓練我的數據集,然後將我的模型提交到這個 repo,這樣別人也能用它。我最終在測試集上得到的 mAP 是 90%,考慮到我的數據集非常小,這個結果已經很好了。
- Keras 實現:https://github.com/experiencor/keras-yolo3
- 提交合並請求:https://github.com/experiencor/keras-yolo3/pull/244
CRAFT & CRNN
爲了找到一個合適的網絡來識別文本,我經過了無數次的嘗試。最後我偶然發現了 keras-ocr,它打包了 CRAFT 和 CRNN,非常靈活,而且有預訓練過的模型,這太棒了。我決定不對模型進行微調,讓它們保持原樣。
keras-ocr 地址:https://github.com/faustomorales/keras-ocr
最重要的是,用 keras-ocr 預測文本非常簡單。基本上就是幾行代碼。你可以去該項目主頁看看這是如何做到的。
第五步:部署我的車牌檢測模型
模型部署主要有兩種方法:
- 在本地進行所有的推理;
- 在雲中進行推理。
這兩種方法都有其挑戰。第一個意味著有一個中心「大腦」計算機系統,這很複雜,而且很貴。第二個面臨的則是延遲和基礎設施方面的挑戰,特別是使用 gpu 進行推理。
在我的研究中,我偶然發現了一個名爲 cortex 的開源項目。它是 AI 領域的新人,但作爲 AI 開發工具的下一個發展方向,這無疑是有意義的。
cortex 項目地址:https://github.com/cortexlabs/cortex
基本上,cortex 是一個將機器學習模型部署爲生産網絡服務的平台。這意味著我可以專注于我的應用程序,而把其余的事情留給 cortex 去處理。它在 AWS 上完成所有准備工作,而我唯一需要做的就是使用模板模型來編寫預測器。更棒的是,我只需爲每個模型編寫幾十行代碼。
如下是從 GitHub repo 獲取的 cortex 運行時的終端。如果這都稱不上優美簡潔,那我就不知道該用什麽詞來形容它了:

圖 7:基于 cortex 提供的雲 api 與客戶端流程圖
在我們的例子中,客戶端是樹莓派,推理請求發送到的雲 api 由 AWS 上的 cortex 提供。
客戶端的源代碼也可以在其 GitHub 中找到:https://github.com/robertlucian/cortex-licens-plate-reader-client
我必須克服的一個挑戰是 4G 的帶寬。最好減少此應用程序所需的帶寬,以減少可能的 hangups 或對可用數據的過度使用。我決定讓 Pi Camera 使用一個非常低的分辨率:480×270(我們這裏可以用一個小分辨率,因爲 Pi Camera 的視野非常窄,所以我們仍然可以很容易地識別車牌)。
不過,即使是在這個分辨率下,每一幀的 JPEG 大小也是大約 100KB(0.8MBits)。乘以每秒 30 幀就得到 3000KB,也就是 24mb /s,這還是在沒有 HTTP 開銷的情況下,這是很多的。
因此,我用了一些小技巧:
- 將寬度減少到 416 像素,也就是 YOLOv3 模型所需要的大小,而且尺度顯然是完好無損的;
- 將圖像轉換爲灰度圖;
- 移除圖片頂部 45% 的部分。這裏的想法是車牌不會出現在車架的頂部,因爲汽車不會飛,對吧?據我所知,刪除 45% 的圖像並不影響預測器的性能;
- 再次轉換圖像爲 JPEG,但此時的質量變低了很多。
最終得到的幀的大小大約是 7-10KB,這是非常好的。這相當于 2.8Mb/s。但是考慮到響應等所有的開銷,它大約是 3.5Mb/s。對于 crnn API,裁剪過的車牌根本不需要太多空間,即使沒有進行壓縮,它們的大小也就是 2-3KB 左右一個。
總而言之,要以 30FPS 的速度運行,推理 api 所需的帶寬大約是 6Mb/s,這個數字我可以接受。
結果
成功了!
上面這個是通過 cortex 進行實時推理的例子。我需要大約 20 個裝備了 gpu 的實例才能順暢地運行它。根據這一組 gpu 的延遲,你可能需要更多的 gpu 或是更少的實例。從捕獲幀到向浏覽器窗口廣播幀之間的平均延遲約爲 0.9 秒,考慮到推斷發生在很遠的地方,這真是太神奇了——到現在我還是覺得驚訝。
文本識別部分可能不是最好的,但它至少證明了一點——它可以通過增加視頻的分辨率或通過減少攝像機的視場或通過微調來更精確。
至于 GPU 需求數太高的問題,這可以通過優化來解決。例如,在模型中使用混合精度/全半精度 (FP16/BFP16)。一般來說,讓模型使用混合精度對精度的影響很小,所以我們並沒有做太多的權衡。
總而言之,如果所有的優化都到位,那麽將 gpu 的數量從 20 個減少到一個實際上是可行的。如果進行了適當的優化,甚至一個 gpu 的資源都用不完。
原文地址:https://towardsdatascience.com/i-built-a-diy-license-plate-reader-with-a-raspberry-pi-and-machine-learning-7e428d3c7401