來源:專知
【新智元導讀】數據分析是現在必備的技能之一。傳統大多采用靜態算法或者規則進行數據分析,但在現實場景中往往面臨的是複雜的交互環境中,如何學習更好的策略是個很實際的問題。幸運的是強化學習可以作爲解決這種問題的一種有效方法。來自新加坡南洋理工大學的學者在TKDE發表了《深度強化學習數據處理與分析》的綜述論文,對最近的工作進行了全面的回顧,重點是利用DRL改進數據處理和分析。
數據處理和分析是基礎和普遍的。算法在數據處理和分析中發揮著至關重要的作用,許多算法設計都結合了啓發式和人類知識和經驗的一般規則,以提高其有效性。
近年來,強化學習,特別是深度強化學習(DRL)在許多領域得到了越來越多的探索和利用,因爲與靜態設計的算法相比,它可以在複雜的交互環境中學習更好的策略。受這一趨勢的推動,我們對最近的工作進行了全面的回顧,重點是利用DRL改進數據處理和分析。
首先,我們介紹了DRL中的關鍵概念、理論和方法。接下來,我們將討論DRL在數據庫系統上的部署,在各個方面促進數據處理和分析,包括數據組織、調度、調優和索引。
然後,我們調查了DRL在數據處理和分析中的應用,從數據准備、自然語言處理到醫療保健、金融科技等。
最後,我們討論了在數據處理和分析中使用DRL所面臨的重要挑戰和未來的研究方向。

論文鏈接:https://arxiv.org/abs/2108.04526
在大數據時代,數據處理和分析是基礎的、無處不在的,對于許多組織來說是至關重要的,這些組織正在進行數字化之旅,以改善和轉變其業務和運營。在提取洞察力之前,數據分析通常需要其他關鍵操作,如數據采集、數據清理、數據集成、建模等。
大數據可以在醫療保健和零售等許多行業釋放出巨大的價值創造。然而,數據的複雜性(例如,高容量、高速度和高多樣性)給數據分析帶來了許多挑戰,因此很難得出有意義的見解。爲了應對這一挑戰,促進數據處理和分析的高效和有效,研究人員和實踐人員設計了大量的算法和技術,也開發了大量的學習系統,如Spark MLlib和Rafiki。
爲了支持快速的數據處理和准確的數據分析,大量的算法依賴于基于人類知識和經驗開發的規則。例如,「最短作業優先」是一種調度算法,它選擇執行時間最短的作業進行下一次執行。但在沒有充分利用工作負載特性的情況下,與基于學習的調度算法相比,其性能較差。另一個例子是計算機網絡中的包分類,它將一個包與一組規則中的一條規則進行匹配。一種解決方案是使用手工調整的啓發式分類來構造決策樹。具體來說,啓發式算法是爲一組特定的規則設計的,因此可能不能很好地工作于具有不同特征的其他工作負載。
我們觀察到現有算法的三個局限性:
首先,算法是次優的。諸如數據分布之類的有用信息可能會被忽略或未被規則充分利用。其次,算法缺乏自適應能力。爲特定工作負載設計的算法不能在另一個不同的工作負載中很好地執行。第三,算法設計是一個耗時的過程。開發人員必須花很多時間嘗試很多規則,以找到一個經驗有效的規則。
基于學習的算法也被用于數據處理和分析。經常使用的學習方法有兩種:監督學習和強化學習。它們通過直接優化性能目標來實現更好的性能。監督學習通常需要一組豐富的高質量標注訓練數據,這可能是很難和具有挑戰性的獲取。例如,配置調優對于優化數據庫管理系統(DBMS)的整體性能非常重要。在離散和連續的空間中,可能有數百個調諧旋鈕相互關聯。此外,不同的數據庫實例、查詢工作負載和硬件特性使得數據收集變得不可用,尤其是在雲環境中。
與監督學習相比,強化學習具有較好的性能,因爲它采用了試錯搜索,並且需要更少的訓練樣本來找到雲數據庫的良好配置。
另一個具體的例子是查詢處理中的查詢優化。數據庫系統優化器的任務是爲查詢找到最佳的執行計劃,以降低查詢成本。傳統的優化器通常枚舉許多候選計劃,並使用成本模型來找到成本最小的計劃。優化過程可能是緩慢且不准確的。
在不依賴于不准確的成本模型的情況下,深度強化學習(DRL)方法通過與數據庫交互來改進執行計劃(例如,更改表連接順序)。
當查詢發送給agent(即DRL優化器)時,代理通過對基本信息(如訪問的關系和表)進行特征化,生成狀態向量。agent以狀態爲輸入,利用神經網絡生成一個動作集的概率分布,動作集可以包含所有可能的作爲潛在動作的join操作。
每個操作表示一對表上的部分連接計劃,一旦執行操作,狀態將被更新。在采取可能的行動之後,生成一個完整的計劃,然後由DBMS執行該計劃以獲得獎勵。
在這個查詢優化問題中,獎勵可以根據實際延遲計算。在有獎勵信號的訓練過程中,agent可以改進策略,産生更高獎勵的更好的連接排序(即延遲更少)。
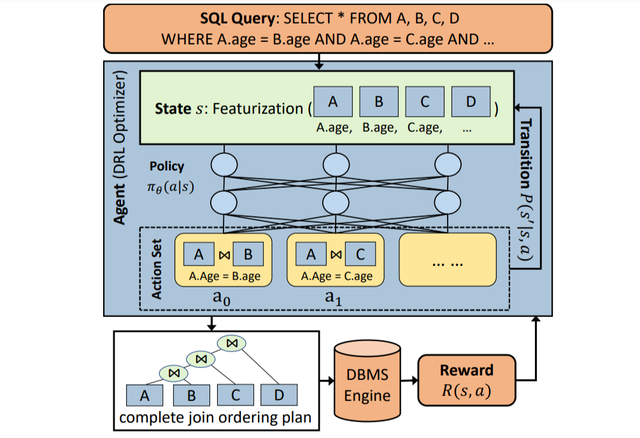
查詢優化的DRL工作流程
強化學習(RL)專注于學習在環境中做出智能的行動。RL算法在探索和開發的基礎上,通過環境反饋來改進自身。在過去的幾十年裏,RL在理論和技術方面都取得了巨大的進步。
值得注意的是,DRL結合了深度學習(DL)技術來處理複雜的非結構化數據,並被設計用于從曆史數據中學習和自我探索,以解決衆所周知的困難和大規模問題(如AlphaGo)。
近年來,來自不同社區的研究人員提出了DRL解決方案,以解決數據處理和分析中的問題。我們將現有的使用DRL的作品從系統和應用兩個角度進行分類。
從系統的角度來看,我們專注于基礎研究課題,從一般的,如調度,到系統特定的,如數據庫的查詢優化。我們還應當強調它是如何制定的馬爾可夫決策過程,並討論如何更有效地解決DRL問題與傳統方法相比。由于實際系統中的工作負載執行和數據采集時間比較長,因此采用了采樣、仿真等技術來提高DRL訓練效率。
從應用的角度來看,我們將涵蓋數據處理和數據分析中的各種關鍵應用,以提供對DRL的可用性和適應性的全面理解。許多領域通過采用DRL進行轉換,這有助于學習有關應用的領域特定知識。
在這次綜述中,我們的目標是提供一個廣泛和系統的回顧,在解決數據系統、數據處理和分析問題中使用DRL的最新進展。
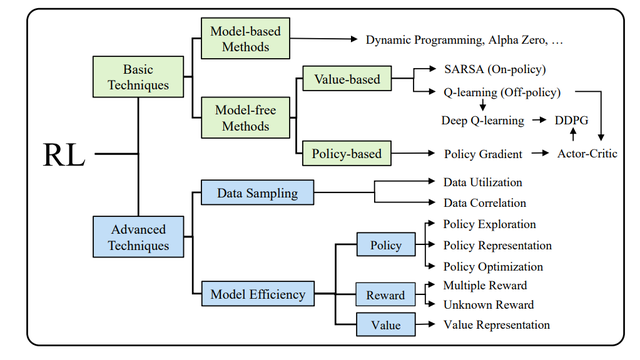
RL技術分類
參考資料:
[1] J. Manyika, M. Chui, B. Brown, J. Bughin, R. Dobbs, C. Roxburgh, A. Hung Byers et al., Big data: The next frontier for innovation, competition, and productivity. McKinsey Global Institute, 2011.
[2] X. Meng, J. Bradley, B. Yavuz, E. Sparks, S. Venkataraman, D. Liu, J. Freeman, D. Tsai, M. Amde, S. Owen et al., “Mllib: Machine learning in apache spark,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 1235–1241, 2016.
[3] W.Wang, J. Gao, M. Zhang, S.Wang, G. Chen, T. K. Ng, B. C. Ooi, J. Shao, and M. Reyad, “Rafiki: machine learning as an analytics service system,” VLDB, vol. 12, no. 2, pp. 128–140, 2018.