
(圖片由AI科技大本營付費下載自視覺中國)
整理 | Jane
出品 | AI科技大本營(ID:rgznai100)
【導語】10月12日,追一科技主辦的首屆中文NL2SQL挑戰賽在激烈的決賽中落下帷幕,冠軍由國防科技大學學生組成的「不上90不改名字」隊伍獲得。此次比賽是中文NLP領域首次舉辦NL2SQL主題比賽,成爲國內NLP技術比賽領域參賽規模最大的賽道之一。
賽事情況:國內外千支隊伍,角逐Top5
(一)千支隊伍挑戰NL2SQL,角逐五強
任務上的創新、應用上的潛力,NL2SQL比賽一經推出,就受到了學界和工業界的廣泛關注。據了解:
(1)自6月24日比賽啓動以來,海內外共有1457支隊伍、1630名選手報名參賽,參與院校數達170所,其中227支隊伍、318名選手提交成績。廣泛的參與,使得NL2SQL成爲國內NLP技術比賽領域參賽規模最大的賽道之一。
(2)參賽選手構成上,學生及科研人員占比48%,企業技術員工占比52%。學生參賽隊伍來自衆多知名院校,如北京大學、清華大學、複旦大學、上海交通大學、南京大學、浙江大學、中國科學技術大學、哈爾濱工業大學、西安交通大學等。
(3)雖然本次比賽的數據內容是中文形式,但仍然吸引了美國、英國、新加坡、日本、澳大利亞、加拿大等海外頂級院校參與,包括卡內基梅隆、墨爾本大學、新加坡國立大學、南安普頓大學、新南威爾士大學、布裏斯托大學、昆士蘭大學等。
(4)來自中國移動、平安集團、搜狗、達闼科技、中興通訊、網宿科技、國雙科技、捷通華聲等衆多企業的技術人員,也成爲參賽隊伍的重要力量。
從初賽、複賽到決賽,記錄頻頻被刷新。比賽初期,排行榜頭部選手們的分數聚集在0.58左右,已經超過了比賽方所提供的baseline。隨後,選手通過各種討論、交流,加深對數據集理解,不斷探索更優的方案,從而提高成績,頭部選手的分數很快突破了0.80大關。在8月12日初賽結束時,比賽榜上的頭部分數已經達到0.89,已經接近WikiSQL的成績。
複賽階段采用線上運行的方式來進行評測,測試集不可下載,並且內容對選手不可見。同時,測試集在保證數據分布與初賽測試集一致同時,加入更多在初賽中沒有出現過的表格數據,屆時,將對選手方案提出更高挑戰。
(5)通過複賽,角逐出了本屆大賽的五強隊伍。
10 月 12 日,五強隊伍在決賽前緊鑼密鼓的做了專業細致的准備,在決賽現場帶來了精彩的答辯,經過現場專家評委的提問打分後,評選出首屆中文NL2SQL挑戰賽冠、亞、季軍及優勝獎隊伍。
-
冠軍:不上90不改名字
張嘯宇,國防科技大學16級博士生,從事自然語言處理相關研究,Kaggle Master;
賽斌,國防科技大學18級碩士生,從事大數據挖掘與應用相關研究;
王蘇宏,從事NLP教育培訓行業相關研究工作,曾在Kaggle大賽中獲金牌、銀牌。
-
亞軍:BugCreater
戴威,清華大學碩士,現于北京國雙科技數據科學團隊負責NLP方向工作;
戴澤輝,清華大學博士,現于北京國雙科技從事NLP方面的研究和工作;
陳華傑,哈爾濱工業大學碩士,現于北京國雙科技從事NLP相關工作。
-
季軍:Model S
陳曦,現于上海觀安信息從事安全日志分析,業務風控等領域研究工作;
辜乘風,現于上海觀安信息從事人工智能安全相關研究;
黃伊,現于妙盈科技從事金融領域文本分析、建模等相關工作。
-
優勝獎:老哥們不放假嗎
趙猛,浙江大學計算機專業2018級碩士生,現于浙江大學數據智能實驗室從事NLP相關研究。
-
優勝獎:大佬帶我飛
戴志港,華南理工大學2019級碩士生,從事計算機視覺相關研究;
祝其樂,佛羅裏達大學博士生,從事計算機視覺和自然語言處理相關研究和工作。

(決賽後五強隊伍與專家評委合影留念)
比賽成績的快速提升,充分體現出選手們的投入與方案的優秀,同時也側面反映出,目前積累的許多技術方案都可以在NL2SQL這一個新任務上發揮作用,大家也意識到,只要有充分的數據來支撐, 目前人工智能領域的方法論可以有效地爲數據庫乃至結構化數據提供自然語言的交互方式。追一科技聯合創始人兼CTO劉雲峰博士表示,“此次挑戰賽參與規模遠超預期,顯示出NL2SQL在學術和工業應用上的潛力,數據庫的交互創新,正在受到越來越多關注”。
(二)挑戰中文數據集
本次比賽發布了首個大規模的中文NL2SQL數據集。數據主要覆蓋金融領域與通用領域,包括4,870張表格數據、49,752條標注數據。在這樣大規模、多領域的數據集上,可以達到90%以上准確率,說明模型具有不錯的泛化能力,相比于傳統方案需要設計複雜而又繁瑣的邏輯規則,新方案可以極大地降低技術上的工作量及維護系統的難度,實現十倍、百倍甚至更高的效率提升。
對比國外的WikiSQL、Spider、WikiTableQuestions等大規模英文NL2SQL數據集,本次比賽的數據集在兼顧數據規模的同時,引入了不一樣的技術難點,例如口語化表達、結合表格內容、命名實體鏈接、更複雜的SQL語法等挑戰,難度更高的同時,也更貼近于真實應用場景。
NL2SQL:當NLP喚醒數據庫的靈魂六問
(一)什麽是NL2SQL?
NL2SQL是自然語言處理技術的一個研究方向,可以將人類的自然語言自動轉化爲相應的SQL 語句(Structured Query Language結構化查詢語言),進而可以與數據庫直接交互、並返回交互的結果。比如我們問:大衆 10 萬到 20 萬之間的車型有幾種?NL2SQL可以讓機器理解這樣的自然語言,並從表格中檢索出答案。
(二)NL2SQL應用前景,可以用在哪些場景,解決什麽問題?
NL2SQL可以用在基于結構化知識的智能交互(問答),比如用戶問“我上個月在南京的差旅住宿,花了多少錢?”這裏面有時間上個月,地點南京,項目差旅等多個維信息檢索需求,甚至更複雜、更多維的問題,AI也可以解答。
NL2SQl也可以用在搜索引擎的優化上,讓搜索引擎更“聰明”。現在的信息檢索技術,在檢索文本時,對于文本中存在的表格內容是無區別對待的,也當做普通的文本來處理;結合NL2SQL,可以讓檢索模型結合普通文本及表格類文本進行更智能的檢索。
NL2SQL的應用,一方面,在用戶端讓用戶體驗、感受更好,更加便捷、快速地獲取獲取信息服務,另一方面,在企業的IT和運營管理上,也會大大降低人力投入、繁瑣的工作量。而且,能夠有效地激活企業數據庫知識價值,讓數據庫通過AI,可以直接面對面地服務用戶,從而減少了專業人士、中間流程帶來的信息壁壘。
具體場景上,在存在結構化知識的領域裏,有多種NL2SQL的應用機會。
-
保險:保費查詢、客戶信息查詢等內部業務數據查詢
-
證券:覆蓋行情信息、行業研報報表、財務報表等結構化數據
-
出行:支持酒店信息、火車票與飛機票查詢等出行場景問答
-
電商:商品銷量、商品詳情、商品篩選與推薦等電商場景問答
-
零售:産品信息、活動細則等新零售場景問答
-
生活:話費查詢、繳費查詢、業務查詢等日常生活問答
(三)NL2SQL背後都有哪些“黑科技”?
NL2SQL,讓非專業人士,不需要學習和掌握數據庫程序語言,就可以自由地查詢各種豐富的數據庫:
-
說句話就行。
-
沒有條條框框的限制,內容和信息更加豐富。以前是程序員寫一個“模板”,在這個模板裏查詢內容。
-
NL2SQL的實現,運用了大量前沿的人工智能算法模型,比如運用了多個預訓練語言模型,相當于AI大腦,讓AI讀懂用戶語言;運用了圖神經網絡,讓AI“看到”數據庫, 一目十行過目不忘,而且更加清晰地分清每個表格內容。
(四)NL2SQL在學術中的定位是怎麽樣的呢?
NL2SQL這一任務的本質,是將用戶的自然語言語句轉化爲計算機可以理解並執行的規範語義表示(formal meaning representation),是語義分析(Semantic Parsing)領域的一個子任務。NL2SQL是由自然語言生成SQL,那麽自然也有NL2Bash、NL2Python、NL2Java等類似的研究。下面是來自NL2Bash Dataset的一條數據,
NL: Search for the string ’git’ in all the files under current directory tree without traversing into ’.git’ folder and excluding files that have ’git’ in their names.
Bash: find . -not -name “.git” -not -path “*.git*” -not –name “*git*” | xargs -I {} grep git {}
雖然生成的程序語言不同,但核心任務與NL2SQL相同,都是需要計算機理解自然語言語句,並生成准確表達語句語義的可執行程序式語言。廣義來說,KBQA也與NL2SQL技術有著千絲萬縷的聯系,其背後的做法也是將用戶的自然語言,轉化爲邏輯形式,只不過不同的是轉化的邏輯形式是SPARQL,而不是SQL。通過生成的查詢語句在知識圖譜中的執行,進而可以直接得到用戶的答案,進而可以提升算法引擎的用戶體驗。
目前,NL2SQL方向已經有WikiSQL、Spider、WikiTableQuestions、ATIS等諸多公開數據集。不同數據集都有各自的特點,在這裏分別來簡單介紹一下這四個數據集,各有特色。
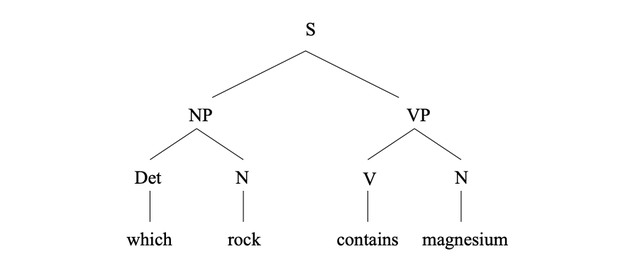
(1)WikiSQL是Salesforce在2017年提出的一個大型標注NL2SQL數據集,也是目前規模最大的NL2SQL數據集。其中包含了26,375張表、87,726條自然語言問句及相應的SQL語句。下圖是其中的一條數據樣例,包括一個table、一條SQL語句及該條SQL語句所對應的自然語言語句。
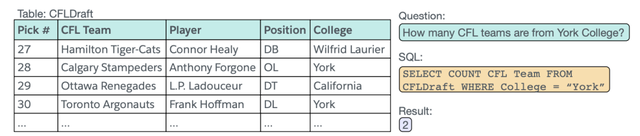
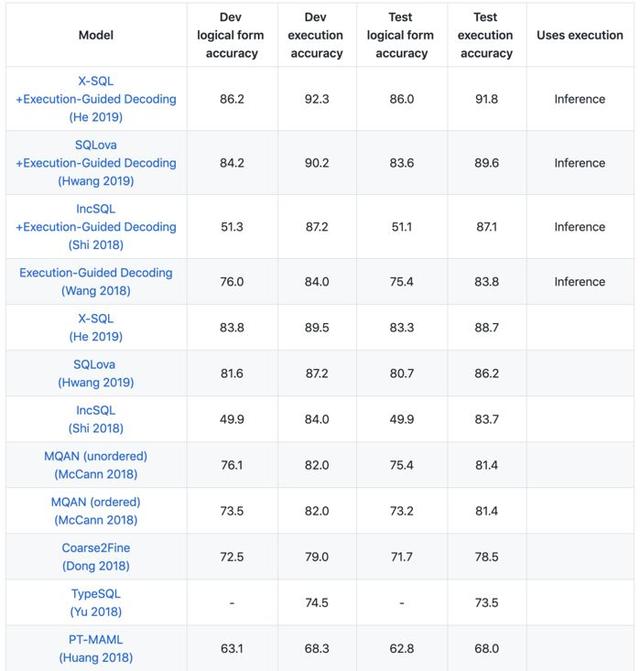
該數據集自提出之後,已經有17次公開提交。因爲SQL的形式較爲簡單,不涉及到高級用法、Question所對應的正確表格已經給定、不需要聯合多張表格等諸多問題的簡化,目前在SQL執行結果准確率這一指標上已經達到了91.8%。
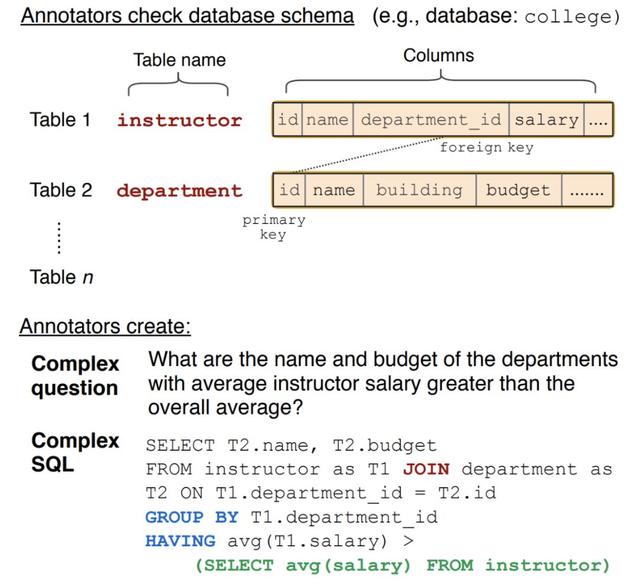
(2)Spider是耶魯大學在2018年新提出的一個較大規模的NL2SQL數據集。該數據集包含了10,181條自然語言問句、分布在200個獨立數據庫中的5,693條SQL,並且內容覆蓋了138個不同的領域。雖然在數據數量上不如WikiSQL,但Spider引入了更多的SQL用法,例如Group By、Order By、Having,甚至需要Join不同表,這更貼近于真實場景,也帶來了更大的難度。因此目前在榜單上,只有5次提交,在不考慮條件判斷中value的情況下,准確率最高只有24.3,可見這個數據集的難度非常大。
下圖是該數據集中的一條樣例。在這個以College主題的數據庫中,用戶詢問“講師的工資高于平均工資水平的部門以及相應的預算是什麽?”,模型需要根據用戶的問題和已知的數據庫中的各種表格、字段以及之間錯綜複雜的關系來生成正確的SQL。
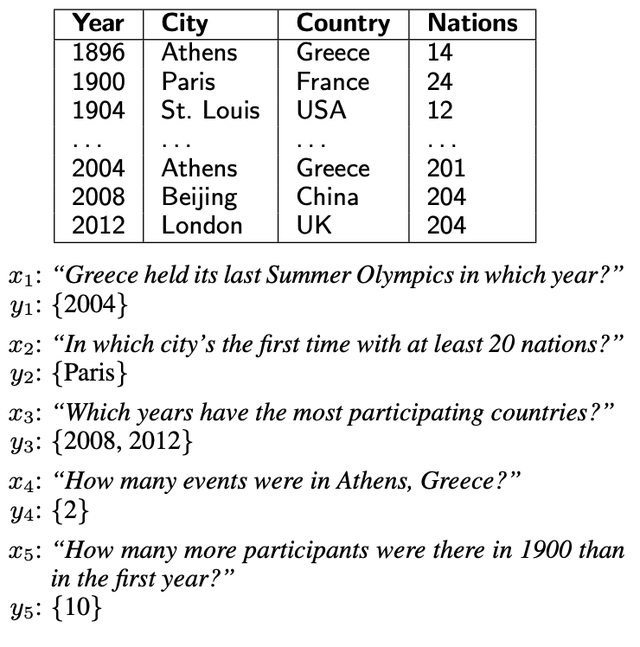
(3)WikiTableQuestions是斯坦佛大學于2015年提出的一個針對維基百科中那些半結構化表格問答的一個數據集,包含了22,033條真實問句以及2,108張表格。由于數據的來源是維基百科,因此表格中的數據是真實且沒有經過歸一化的,一個cell內可能包含多個實體或含義,比如“Beijing, China” or “200 km”;同時,爲了可以很好地泛化到其它領域的數據,該數據集在測試集中的表格主題和實體之間的關系都是在訓練集中沒有見到過的。下圖是該數據集中的一條示例,數據闡述的方式,展現出作者想要體現出的問答元素。
(4)而The Air Travel Information System(ATIS)是一個年代較爲久遠的經典數據集,由德克薩斯儀器公司在1990年提出。該數據集獲取自關系型數據庫Official Airline Guide (OAG, 1990),包含27張表以及不到2000次的問詢,每次問詢平均7輪,93%的情況下需要聯合3張以上的表來得到答案,問詢的內容涵蓋了航班、費用、城市、地面服務等信息。下圖是取自該數據集中的一條樣例,可以看得出來比之前介紹的數據集都更有難度得多。

在深度學習端到端解決方案流行之前,這一領域的解決方案主要是通過高質量的語法樹和詞典來構建語義解析器,再將自然語言語句轉化爲相應的SQL。
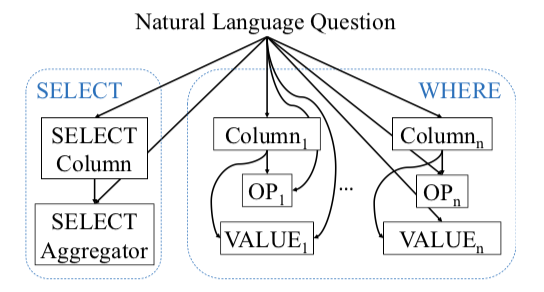
現在的解決方案則主要是端到端與SQL特征規則相結合。以在WikiSQL數據集上的SOTA模型SQLova爲例:首先使用BERT對Question和SQL表格進行編碼和特征提取,然後根據數據集中SQL語句的句法特征,將預測生成SQL語句的任務解耦爲6個子任務,分別是Select-Column、Select-Aggregation、Where-Number、Where-Column、Where-Operation以及Where-Value,不同子任務之間存在一定的依賴關系,最終使用提取到的特征,依次進行6個任務的預測。
(五)爲什麽發起此次比賽?
(1)NLP(自然語言處理)在經曆多年厚積薄發之後,近些年來開始有所突破和爆發,並孕育出衆多的創新機會,NL2SQL正是NLP一個新興但非常有潛力的研究領域。
(2)從AI技術的發展規律來看,一個技術如果有專門的技術挑戰賽,會非常快地加速這個技術的産業化落地,比如視覺的imagenet、人臉識別,NLP(自然語言處理)早期的分詞、機器翻譯,以及近期的閱讀理解等領域,一些公開測試集或者挑戰賽出現的時間點,恰好都是這個技術從論文走上産業化的臨界點。很好的說明了技術比賽推動技術成熟的作用。
(3)AI落地一直存在一道鴻溝,就是大衆認知,特別在企業服務領域,“AI技術可以解決什麽問題”,“哪些AI技術可以解決我的問題”,在市場供需兩者之間一直存在一道鴻溝,如何解決整個鴻溝,業內在進行各種嘗試。希望這樣的比賽能夠成爲一個平台和橋梁,除了技術開發和研究人員,更多的産業、企業夥伴乃至公衆,也能夠走近NL2SQL,走近NLP,走近AI,大家有更多地碰撞、分享、交流,在促進市場教育的同時,也讓技術能夠汲取更多的商業和應用視角,從而助推AI技術更快商業落地。
(六)NL2SQL的未來
WikiSQL數據集雖然是目前規模最大的有監督數據集,但其數據形式和難度過于簡單:對于SQL語句,條件的表達只支持最基礎的>、<、=,條件之間的關系只有and,不支持聚組、排序、嵌套等其它衆多常用的SQL語法,不需要聯合多表查詢答案,真實答案所在表格已知等諸多問題的簡化,所以在這個數據集上,SQL執行結果的准確率目前已經達到了91.8%。
但同時存在一個問題,這樣的數據集並不符合真實的應用場景。在真實的場景中,用戶問題中的值非常可能不是數據表中所出現的,需要一定的泛化才可以匹配到;真實的表之間存在錯綜複雜的鍵關聯關系,想要得到真實答案,通常需要聯合多張表進行查詢;每一張都有不同的意義,並且每張表中列的意義也都不同,甚至可能相同名字的列,在不同的表格中所代表的含義是不同的;真實場景中,用戶的問題表達會很豐富,會使用各種各樣的條件來篩選數據。諸如此類的實際因素還有很多。因此,WikiSQL數據集起到的作用更多程度上是抛磚引玉,而不具備實際應用場景落地的價值。
相比之下,Spider等數據集更貼近于真實應用場景:涉及到查詢語句嵌套、多表聯合查詢、並且支持幾乎所有SQL語法的用法,用戶問句的表達方式和語義信息也更豐富。但即使作者們考慮到數據集的難度,貼心地將數據集按照難度分爲簡單、中等和困難,數據集的難度也依然讓人望而生畏,目前各項指標也都很低。
如何更好地結合數據庫信息來理解並表達用戶語句的語義、數據庫的信息該如何編碼及表達、複雜卻有必要的SQL語句該如何生成,類似此類的挑戰還有很多需要解決,都是非常值得探索的方向。
(*本文爲 AI科技大本營整理文章,轉載請微信聯系 1092722531)
◆
◆
2019 中國大數據技術大會(BDTC)再度來襲!豪華主席陣容及百位技術專家齊聚,15 場精選專題技術和行業論壇,超強幹貨+技術剖析+行業實踐立體解讀,深入解析熱門技術在行業中的實踐落地。