
【新智元導讀】開發出精確的和可擴展的無約束人臉識別算法,是生物識別和計算機視覺領域長期以來不斷追求的目標。爲了促進非受限條件下的人臉識別,美國國家技術標准局(NIST)主辦了IJB-A競賽。新加坡松下研究院與新加坡國立大學LV組去年兩次奪得冠軍,項目負責人新加坡松下研究院的研究工程師熊霖進行了專訪,分享技術細節以及參賽經驗。

開發出精確的和可擴展的無約束人臉識別算法,是生物識別和計算機視覺領域長期以來不斷追求的目標。然而,實現這一點難度非常大,因爲“無約束”需要人臉識別系統能在各種面部圖像采集條件下(不同的光照、不同的傳感器,以及是否進行了壓縮),或者在被拍攝者各種主觀條件下(面部的不同姿態、不同表情以及是否有遮擋),都能成功進行驗證與識別。
去年3月,新加坡松下研究院與新加坡國立大學LV組參加了美國國家技術標准局(NIST)主辦的非受限條件下人臉識別競賽IJB-A,之後收到通知,獲得了人臉驗證(verification)與人臉辨認(identification)的雙項冠軍。
不過,他們在位居榜首三個月後被一家商業機構超越。但是,團隊繼續努力,找到差距,彌補不足,最終再次拿到目前已發表文章及arXiv技術報告中的最好性能。
在這樣的背景下,新智元對項目負責人新加坡松下研究院的研究工程師熊霖進行了專訪,分享技術細節以及參賽經驗。
不過,你首先可能會問:IJB-A人臉識別競賽是怎樣的一個比賽?
早在2007年,Huang等人在一篇技術報告[1]提出並發布了後來非常著名的LFW人臉數據集,該數據集確實爲後來推動無約束人臉識別算法起到了很大的作用。這個數據集包括在不受控或“自然環境下”采集的被拍攝者的靜態圖像。
自LFW數據集發布以來,許多類似的人臉數據集被相繼發布,比如PubFig[2]和YouTube Faces(YTF)[3]。LFW和PubFig僅包含被拍攝者的靜態圖像,而YTF人臉數據則包含被拍攝者的一段視頻。LFW和YTF等數據發布後,吸引了大量的學術機構和工業界團隊去提升算法在這些數據集上的性能。
如今,尤其在LFW數據集上,已經有許多人臉識別算法的性能接近[4][5]甚至超越了人類的水平[6][7]。然而,無約束人臉識別算法的性能在很多實際的應用場景(比如監控系統),仍需亟待提高。究其原因,部分是因爲所采用的評估協議沒有充分考慮到無約束場景中圖像實際采集的需求[8],但可能更多的原因,來自于數據集,比如LFW和YTF等都不完全是在無約束環境下采集的。
基于上面的這些原因,美國國家標准與技術研究院 (National Institute of Standards and Technology,NIST)于2015年發起了一項旨在推動無約束人臉檢測與識別的挑戰賽,並將相關的數據集IARPA Janus Benchmark A(IJB-A)發布在當年CVPR的論文中[9]。
不同于LFW和YTF,IJB-A具有如下新特點:
-
不僅包括被拍攝者的靜態圖像,也包括被拍攝者的視頻片段。因爲這個特點,論文引入了“模板”的概念,也即在無約束條件下采集的、所有感興趣面部媒體的一個集合,這個媒體集合不僅包括被拍攝者的靜態圖像,也包括視頻片段。
-
所有媒體都是在完全無約束環境下采集的。很多被拍攝者的面部姿態變化巨大,光照變化劇烈以及擁有不同的圖像分辨率。
-
因爲一個模板代表一個集合,所以最終的人臉驗證與識別不是基于單個圖像,而是基于集合對集合。此外,被拍攝者也來自世界不同國家、地區和種族,具有廣泛的地域性。

正是因爲IJB-A數據集擁有以上這三方面的新特點,使得該數據集非常符合實際的應用場景。當然,隨之帶來的也是巨大的挑戰。在論文[9]中, 作者擴展了現有的評估協議到基于模板的場景,並針對人臉識別任務設計了開集(open-set)和閉集的評測協議(所謂開集評測協議,就是測試圖像 [probe] 可能並不在注冊集 中出現)。
這些新特點就成爲新加坡松下研究院和新加坡國立大學LV組參加 NIST IJB-A 人臉挑戰賽的主要動機。團隊成員表示,希望他們提出的算法能夠在完全無約束環境下更加魯棒,性能得到顯著提升。

新加坡松下研究院與新加坡國立大學LV組合作論文,非受限條件人臉識別目前已發表文章及arXiv技術報告中的最好性能。
從三處尋找突破口,提出冠軍模型“深度遷移特征融合聯合學習框架”
新智元:這次獲勝的具體算法/模型是什麽?相較于其他參賽解決方案的優勢在哪裏?
NIST 在2015年召開的CVPR上發布了IJB-A人臉驗證與識別數據集,並同時拉開了圍繞該數據集的人臉挑戰賽的帷幕,我們于2016年10月正式決定參加該挑戰賽並于2017年4月的NIST官方報告中,分別在驗證1:1和識別1:N上都取得了第一的成績,這不是僅僅依靠單個算法或模型所能做到的。我們的聯合學習框架稱之爲遷移深度特征融合,具體可參見我們的arXiv預印版論文[1],我們的最新結果將在即將更新的arXiv預印版論文裏展示。
不同于其他挑戰賽所提供的數據集,例如COCO、ImageNet 以及MS-Celeb-1M等都提供了動辄幾十萬,幾百萬甚至上千萬的數據,IJB-A數據則只包含來自500個對象的5396副靜態圖像和20412幀的視頻數據,顯然這樣規模的數據是無法直接用來訓練一個深層網絡模型的。所以絕大部分的參賽方案都會使用外部數據並設計部署深層模型進行訓練,然後在IJB-A數據上進行微調或在低維嵌入空間再訓練另一個簡單的模型以此來獲得一個不錯的成績。簡而言之,我們要想提出針對IJB-A人臉挑戰賽的解決方案,那必然要從以下三處尋找突破口:外部數據、設計並部署深層模型和受遷移學習思想的啓發是微調網絡還是在低維嵌入空間再訓練一個簡單的模型。
具體來說,通過比較衆多論文中IJB-A的結果,大多數方法都是基于深層網絡的單一算法或單一模型,我們將這些算法總結爲兩類:一類是基于深層網絡的單一算法或單一模型並輔以增加判別性信息的損失函數,好處是可以進行端到端的訓練,但還需要在IJB-A原始數據上微調深層網絡來獲得一個不錯的成績;另一類也是基于深層網絡的單一算法或模型但並非端到端的訓練,前段基于深度模型,後段則通過將前段訓練的深層網絡作爲特征提取器來提取IJB-A原始數據的低維特征,並對這些低維特征在低維嵌入空間進行測度學習來提升系統整體的判別性,最終獲得一個不錯的性能。這種分開的訓練,好處是後段測度學習可以靈活選擇,並且訓練的代價要比微調深層網絡小不少,但不能利用端到端訓練的優勢。在NIST的官方報告中,只有結果的比拼也未透露參賽者具體的算法和模型。
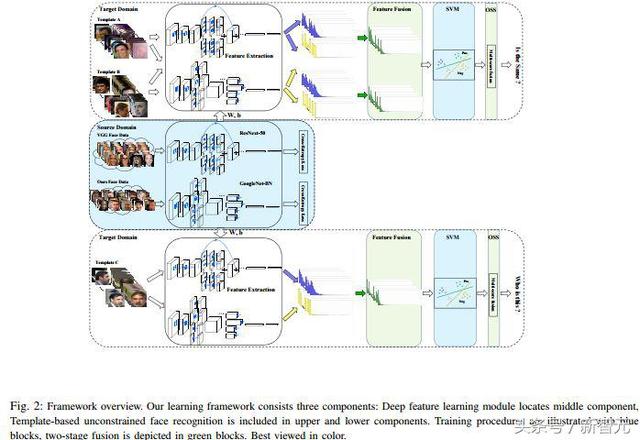
在外部數據方面,我們除了收集公共的人臉識別數據集外,也在網上爬取和采集各種符合項目要求的人臉數據,這其中涵蓋了不同性別、不同年齡段、不同種族和不同地域的被拍攝對象。我們采集不同表情、不同光照條件和不同面部姿態的人臉數據,除了靜態圖像也包含攝像頭捕捉的動態視頻數據。
在設計並部署深層模型方面,縱觀各種挑戰賽,比如ImageNet, MS-Celeb-1M 以及 COCO等 ,要想沖擊更高的性能,參賽的團隊都會考慮多模型融合或集成的策略。我們吸取了這樣的經驗,但與通常采用的同構多模型融合策略(同一深層模型,同一訓練數據)不同,我們的聯合學習框架中則采用了異構多模型的融合策略。具體來說,我們知道,不同的深層模型由于設計思路的不同(卷積核的大小,是否考慮空間尺度信息,網絡的深度和寬度的差異,各通道間的關系等等)其表達能力也大不同,但這些表達能力之間有沒有互補性?我們早期通過初步的實驗發現,確實存在這樣的互補性,尤其網絡結構差別越大,這種互補性也就越強。那麽不同的訓練數據呢?我們通過實驗發現,即便采用相同的深層模型訓練,在同一目標數據上,其低維的特征同樣也有互補性。爲了充分挖掘和利用這樣的互補性,我們在聯合學習框架中部署了兩路具有巨大結構差異的深層網絡並使用不同的大規模數據進行訓練。
在利用遷移學習的思想時,我們同時采用了兩種策略,即在低維嵌入空間再訓練一個簡單的測度學習模型和微調網絡但不在局限于原始的IJB-A數據。對于第一種策略,我們通過模板自適應的思想設計了使用特定模板(IJB-A數據裏引入了模板的概念,所謂模板是指一個集合,這個集合不僅包括被攝對象的靜態圖像也包括視頻片段)來訓練支撐矢量機以得到特定的測度信息,目的就是爲了增強系統的判別性,這其中我們針對支撐矢量機也巧妙的設計了訓練集和測試集,並且采用了兩段融合的思想(特征融合與相似度分數融合),詳細信息可以參見[1]。
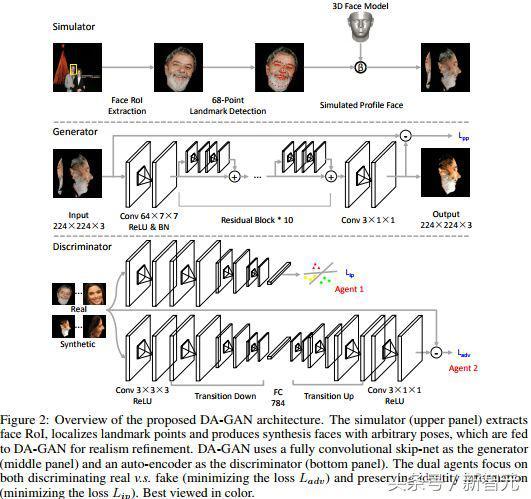
對于第二種策略,我們並不滿足于原始的IJB-A數據,因爲我們通過分析原始IJB-A數據發現,由于數據本身的面部多姿態性,面部姿態(比如偏向角)的分布是極不均衡的,尤其在大角度視角下具有長尾效應,如果直接使用IJB-A數據進行網絡微調,勢必最終的算法性能會是有偏的(受占主要正面或接近正面視角數據的影響),受蘋果在CVPR 2017上獲得最佳論文獎的工作[4]啓發,我們提出了雙代理的對抗生成網絡用來生成逼真的多視角的面部姿態以獲得均衡分布的IJB-A面部姿態數據。我們的方法可以看作是針對特定問題的數據增強方法並且可以推廣到用于俯仰角的分析,詳細信息可以參見[3]。
設計思路與關鍵:數據與基線深層網絡模型的設計與部署
新智元:設計思路是怎樣的?關鍵點在哪裏?
正如我在前面分析的,我們的參賽方案著眼于三點:數據(包括外部數據和經過我們設計的增強方法而得到的增強版的IJB-A數據)、基線深層網絡模型和受遷移學習思想啓發的利用增強版IJB-A數據微調網絡,以及在低維嵌入空間訓練測度學習模型。這裏的每一點都對我們最終能夠在驗證1:1和識別1:N上都取得第一都至關重要。這其中關鍵的還是數據與基線深層網絡模型的設計與部署。
對于外部數據,我們不但使用了公開的人臉識別數據集,比如VGG 人臉數據集[5],其中包括2622 個對象且每個對象擁有約1000副靜態圖像,而且也使用了我們自己采集並整理的人臉數據。對所有人臉數據我們都進行了數據清理,人臉檢測、人臉對齊以及標准化等預處理。其中我們自行設計的數據清理和標准化等預處理方法同樣用到了早先我們參加的微軟的百萬名人識別競賽MS-Celeb-1M,詳細信息可以參見[2]。
對于增強版的IJB-A數據,最令人自豪的是,我們提出的雙代理對抗生成網絡是第一個針對人臉面部姿態(不同偏向角)做數據增強的模型,並且這種模型是可控的並能産生逼真的人臉面部姿態,尤其在完全無約束環境下我們的通過生成識別(recognition via generation)框架能夠極大改善算法的性能。相關成果已經發表在NIPS 2017。

雙代理對抗生成網絡論文,已經在NIPS 2017發表,是第一個針對人臉面部姿態(不同偏向角)做數據增強的模型
對于基線深層網絡模型,我們采用了異構多模型的融合策略。就是爲了充分挖掘和利用不同深層網絡結構和不同數據間的互補性,我們在聯合學習框架中部署了兩路具有巨大結構差異的深層網絡並使用不同的大規模數據進行訓練。當然,在訓練深層網絡模型時有效的數據增強方法也很重要,需要針對IJB-A數據的特點做出相應設計,比如光照的劇烈變化。
此外,我們的聯合學習框架包含兩階段的融合,即特征融合與相似度分數融合。
無約束人臉識別難點與挑戰:同一對象面部姿態變化劇烈
新智元:針對無約束人臉識別,當前主流的方法是什麽(有哪些)?這些方法存在哪些問題或局限?存在這些局限的原因是什麽?
針對完全無約束環境下的人臉識別,特別是在面部姿態變化劇烈的場景下的人臉識別,有研究論文[6]指出,當應用場景從正面-正面轉換到正面-側面或側面-正面後,大多數人臉驗證算法的性能會有超過10%的性能損失。這表明,面部姿態的劇烈變化仍然是今後人臉識別算法需要亟待解決的問題。這主要是因爲同一對象的面部姿態的劇烈變化遠超過不同對象間內在的面部外觀的變化。
爲了克服上面的挑戰,根據最近提出的多種方法,我們可以歸結爲兩大類。第一類是從各種面部姿態數據中直接學習姿態不變的判別性表示,我們提出的遷移深度特征融合的聯合學習框架也屬于這一類。具體方法包括我們前面提到的基于深層網絡的單一算法或單一模型並輔以增加判別性信息的損失函數[5][7],以及基于多模態或多姿態的方法[8][9]。前者的局限在于僅考慮的單一的訓練數據和單一的深層網絡模型,並且網絡的層數與現在主流的深層模型相比還不夠深,比如[5]中使用了VGG16或VGG19 的網絡結構,[7]中使用了類似GoogLeNet的22層結構。作者做出這樣的選擇,一是更高效的反向傳播梯度信息流的網絡結構還未被提出,對于更深的網絡結構還無法有效探求,二是可能也由于當時硬件算力的制約。Triplet Loss 損失函數在這些方法中的得到使用,使得其被大家所熟知,但所帶來的算法性能的提升有限,更多的性能提升還是來自于大規模的訓練數據和有效的深層模型。後者的局限在于需要針對不同模態不同姿態去分別學習各自的深層網絡模型,當模態數量和姿態數量增加,此外如果訓練數據本身非常龐大,那訓練多模態和多姿態所需的訓練數據也將線性增加,這都將使得訓練多個深層神經網絡所帶來的時間和計算成本非常巨大。在對抗生成網絡誕生之前,生成特定姿態的人臉數據仍然有不少問題需要解決,比如使用3D模型,但生成的面部數據尤其是大姿態下會出現面部紋理細節丟失的現象,而我們提出的方法[3]可以有效解決這個問題。
第二類是通過人臉合成的方法將大姿態的人臉(比如大偏向角的側臉)正面化(frontalization)爲正臉,然後再用標准的人臉驗證與識別算法去做最終的判斷。最具代表性的方法是TP-GAN (Two-Pathway Generative Adversarial Network)[10],論文中展示的將側臉生成正臉的可視化結果是讓人震撼的,這足以顯示出對抗生成網絡具有強大的生命力。但經我們仿真複現該方法時發現,TP-GAN對Multi-PIE[12]數據有嚴重的過擬合問題,特別是想推廣該方法到IJB-A數據時。這當然與該模型就是在Multi-PIE數據上訓練有直接關系。更主要的原因是要想訓練TP-GAN,針對數據的要求是比較嚴格的(需要有成對的正臉和側臉數據,側臉相應的標注點信息,如眼睛、鼻子和嘴巴的位置信息),能符合條件的數據很少,如果想將算法推廣到IJB-A數據,那Multi-PIE幾乎是唯一選擇。
最近,L.Tran等人[11]提出的DR-GAN (Disentangled Representation learning-Generative Adversarial Network),爲試圖將前兩類方法結合起來做了初步的嘗試。但DR-GAN在Multi-PIE上的性能與TP-GAN相比還是有差距。雖然DR-GAN在IJB-A上表現出不錯的性能,但與第一類方法相比還有很大的提升空間。
截止發稿前,我們通過改進基線深層網絡模型、增加了新的外部訓練數據以及增加了一些訓練技巧,使得我們的算法在IJB-A數據上的性能又被刷到了曆史新高,同時我們對人臉合成的方法同樣也抱有濃厚的興趣,也希望充分利用前兩類方法的優勢做出新的算法突破,相關的論文我們會陸續放出。
意外:驗證數據出現在了訓練數據裏
新智元:比賽中有遇到意外嗎?如何解決的?
任何科學實驗都可能伴隨著意外情況,近期我們在做相關實驗時確實遇到了一個意外情況。爲了進一步提高我們算法在IJB-A數據上的性能,使其有更大的突破,我們組織實習生在互聯網上爬取相關的人臉數據,根據[5]的建議,我們主要選擇抓取名人的圖片以及大量公開的照片其中包括著名的運動員,影視歌演員以及政治家和國家領導人等,且希望盡可能覆蓋不同性別、不同年齡段、不同種族、不同地域、不同表情、不同光照條件和不同面部姿態的人臉數據,以求滿足IJB-A數據所具有的完全無約束條件。這樣,我們就得到了一個人名列表和對應的靜態圖片集,爲了保證每個對象至少包含100副變化多樣的面部數據,我們做了適當篩選。
整個過程我們花費了前後1個多月的時間。然後我們也收集了已經公布的最新的人臉識別數據集,光將兩者整合和做數據清洗等預處理也花費了近3個月時間。這包括使用多個人臉檢測算法,多級的檢測靜態圖片集以防止漏檢,針對誤檢和檢測出多張人臉的情況,我們使用在其他數據集上預訓練好的超過百層的深層神經網絡提取特征並計算相似性分數,再經過選擇適當阈值進行篩選,最後我們得到了約1萬個對象,近400萬副圖片的數據庫。
我們使用這個數據集來訓練經改進的基線深層網絡模型,在IJB-A數據集上來驗證我們的算法的性能,最後確實獲得了意想不到的高性能。當看到我們的算法性能有了很大突破,正爲此而歡呼雀躍時,突然我們研究人員發現忘記將新獲得的數據集與IJB-A數據集做去重處理。
這個消息確實給了我們當頭一棒,因爲驗證數據出現在了訓練數據裏,即便占比很少在機器學習方法論裏也是不被允許的。爲了追求嚴謹和公平的科研精神,我們根據人名列表重新設計了工具用于做IJB-A數據的去重處理。最後雖然性能上有輕微的降低,但我們最大程度上保證了嚴謹和公平。
參賽的硬件條件/配置如何?在過去一年,硬件或者說芯片的發展,對你們的工作是否有影響?
我們研究院對深度學習的項目都是大力支持的,這保證了我們可以使用到最新的GPU。我們在設計第一版算法時,訓練兩個都是百萬數據的深層網絡時(網絡深度最多也就50層),使用的是英偉達麥斯威爾(Maxwell)核心的Tesla M40 GPU,每個網絡的訓練都使用4塊卡,一個模型完整的訓練最長需要12天。後面有了英偉達帕斯卡(Pascal)核心的GTX Titan X。我們加深了網絡結構,同樣每個網絡的訓練都使用4塊卡,一個模型完整的訓練最長甚至需要18天。而最近我們使用了更大的數據集,並使用超過一百層的深度網絡結構,通過英偉達的DGX-1的Tesla P100 4塊GPU,一個有效模型的訓練可以縮短到8天。如果使用最新的Tesla V100的GPU,或許還可以繼續降低模型訓練的時間成本。隨著GPU芯片的飛速發展,有了這樣的算力,確實爲我們進行調參提供了很大便利也提升了效率。當然,谷歌專門爲人工智能和機器學習而研發的專用芯片TPU極大的推動了谷歌AI項目的進展,只是我們還無法獲得谷歌的TPU來加速我們的項目開發。
爲了更好的人臉識別,我們還需要更加符合實際場景的數據集
新智元:從LFW到IJB-A,爲了更好的人臉識別,我們還需要怎樣的數據集?
自2007年,Huang 等人在一篇技術報告[13]中就提出並發布了後來非常著名的LFW人臉數據集,該數據集確實爲後來推動無約束人臉識別算法起到了很大的作用。 這個數據集包括在不受控或“自然環境下”采集的被拍攝者的靜態圖像。自LFW數據集發布以來,許多類似的人臉數據集被相繼發布,如PubFig [14]和 YouTube Faces (YTF)[15]。不同于LFW 和 PubFig 僅包含被拍攝者的靜態圖像,YTF人臉數據則包含被拍攝者的一段視頻。LFW和YTF等數據發布後,吸引了大量的學術機構和工業界去提升算法在這些數據集上的性能。然而,無約束人臉識別算法的性能在很多實際的應用場景比如監控系統中仍需亟待提高。
究其原因,可能更多的原因來自于數據集,比如LFW和YTF等都不完全是無約束環境下采集的。2014年,CASIA-WebFace [16]數據集發布,其中包括10575個對象和約50萬的人臉圖像,該數據盡管對象數過萬,但是數據分布極不平衡,平均每個對象僅擁有46.8副圖像。一年後,VGG 人臉數據[5]被發布,其中包括2622個對象和約2.6百萬張人臉圖像,平均每個對象平均擁有1000副人臉圖像。但CASIA-WebFace 和 VGG 人臉數據中大姿態的面部數據占比非常少且光照變化不大。同年,美國國家標准與技術研究院 National Institute of Standards and Technology (NIST)發起了一項旨在推動無約束人臉檢測與識別的挑戰賽,並將相關的數據集IARPA Janus Benchmark A (IJB-A)發布在當年CVPR的論文中[19], IJB-A數據集中不僅包括被攝對象的靜態圖像而且同時也包括被攝者的視頻片段。因爲這個特點,論文種引入了模板的概念,這裏所謂的模板是指在無約束條件下采集的所有感興趣面部媒體的一個集合,這個媒體集合不僅包括被拍攝者的靜態圖像也包括視頻片段,而且數據集中的所有媒體都是在完全無約束環境下采集的。很多被拍攝者的面部姿態變化巨大,光照變化劇烈以及擁有不同的圖像分辨率,唯一的不足是該數據集的規模小。
2016年,更大的百萬級人臉數據MegaFace[17]在當年的CVPR被發布,其中包括690572個對象和約4.7百萬張人臉圖像,將人臉數據的規模推向了一個高度。而美國華盛頓大學發布的這個數據集方針設定不同,其內容是幾十位互聯網名人的圖片再加上普通人的1百萬張圖片作爲幹擾數據,相比人臉識別,更傾向于在大噪聲情況下的人臉驗證,並且數據的分布同樣不平衡,平均每個對象只有7副圖像,同一對象內人臉數據的變化小。同年,微軟發布了MS-Celeb-1M[18]數據集,該數據集包含10萬個對象和約1千萬張人臉圖像。這是迄今最大規模的人臉識別數據集,盡管規模很大但數據分布不平衡且大姿態的面部數據占比少且存在不少的噪聲數據。
針對IJB-A 數據這種完全無約束環境下采集的數據,我們當然還需要更符合實際場景(比如包括更多的面部姿態變化、更多的光照變化甚至還有分辨率變化)的大規模人臉數據集。如果在沒有合作,僅考慮自己采集數據的情況下,權衡成本,采集的對象數量不必非常大,萬級別的就夠用但應盡量保證所采集數據的分布盡量均衡,即每個對象平均要有至少100副以上的面部圖像,目的是盡可能涵蓋更多的面部變化信息,這其中也要考慮面部姿態分布的均衡性,以及要有更多的光照變化,甚至也盡可能包括不同分辨率的情況。同時也要考慮盡可能覆蓋不同性別、不同年齡段、不同種族和不同地域的對象,數據集盡量幹淨,少量的噪聲數據在深層模型下是可接受的。當然,未來還是需要工業界與學術界甚至和政府部門建立緊密的合作,有助于更高效的人臉數據采集與共享,共同推動完全無約束條件下的人臉驗證與識別算法的性能。
如果要投入實用,作爲入口的人臉檢測將更加重要
新智元:獲勝的技術投入實用還有多大距離?還需要解決哪些問題?
這個問題非常好,也非常具有實際意義。目前,我們研究院參加IJB-A 的人臉驗證與識別挑戰賽的目的,從技術角度上是希望我們提出的學習算法或框架能夠在IJB-A數據上從驗證到識別都能取得最高的精度,有些類似學術研究的性質,追求的是精度的極限。而從研究院的角度是希望通過在IJB-A的挑戰上有更大的突破,來提升松下新加坡研究院人臉識別技術水平,進而爲我們相應産品的更新換代打下堅實的技術基礎,也同時爲整個松下集團帶來商業上的積極影響。並且IJB-A的人臉驗證與識別挑戰賽更關注的還是性能和精度,盡管該挑戰賽目前已經落下帷幕,但是在該數據集上對性能和精度的追逐不會就此停歇。然而,僅僅在性能和精度上的精益求精並不能表示該技術能很快落地並投入實用。這其中還有很多需要優化和改進的空間,根據360公司首席科學家顔水成教授談到的四元分析法,即算法、算力、數據和場景,IJB-A 的人臉驗證與識別挑戰賽的特點是數據和場景都是固定的,剩下的就是用盡量多的計算資源,設計和部署不同的算法,甚至使用更多網絡和更多外部數據的異構多模型融合策略,其目的就是爲了追求精度的極限,但這裏面很多的成果是無法短時間投入實用的。不僅僅我們提出的模型,很多存在于論文上的算法同樣也會面臨這樣的實際問題。要想投入實用,那就面臨的是場景和算力的固定,在這樣的情況下怎樣去提升算法和收集新數據,這與場景和數據固定是完全不一樣的。比如,我們會遇到很多實際的問題,模型太大那就需要進行壓縮,算力有限有時甚至只有CPU的資源,你的算法還能否滿足性能要求,滿足不了那如何去平衡,這些都是需要逐個優化的。並且很多時候,在滿足這個條件後又會有一些新的問題出來。
此外,IJB-A的人臉驗證與識別挑戰賽,核心目標是驗證與識別,但要知道,人臉識別系統除了驗證與識別,還有一個重要的模塊那就是人臉檢測。人臉檢測從某種意義上將更重要,這解決的是驗證與識別的入口問題,人臉檢測同樣會遇到不同面部姿態、不同光照、不同分辨率、不同大小甚至人臉部分被遮擋的挑戰,這都是需要特定的技術比如多尺度感受野、注意力機制和通用目標檢測的方法來協同來解決。甚至是否可以借助身體的信息幫助我們做面部檢測,這都是很有意思的研究方向。我們松下研究院在人臉檢測方向也有長期的技術積累,這次參賽所用的人臉檢測算法部分就來自于自己的研究成果。
活體檢測是下一個目標
新智元:團隊接下來的工作和計劃?哪些問題/特定任務/挑戰賽讓你們感興趣?
在IJB-A的人臉驗證與識別挑戰賽落下帷幕之際,我們最終能將算法在IJB-A上的性能做到很大提升,這當然值得整個團隊既振奮又高興,但在喜悅之後我們並沒有停下腳步。首先,我在前面提到,我們對人臉合成的方法同樣也抱有濃厚的興趣,也希望充分利用從各種面部姿態數據中直接學習姿態不變的判別性表示和通過人臉合成的方法將大姿態的人臉正面化這兩類方法的優勢,做出新的算法突破,相關的論文我們已經在准備,在合適的時機會陸續放出。其次,除了IJB-A的挑戰賽,NIST還舉辦了其他的人臉識別挑戰其具有不同的設計目標,有的在注重性能的同時還要兼顧效率,這對算法的設計提出的更高的要求,有的應用場景更特殊,甚至需要重新采集新的數據,而現有的模型和算法能否推廣到新的應用場景,這些都需要慎重思考和周密計劃。此外MegaFace的挑戰賽吸引了很多學術界和工業界的機構參與,我們也會考慮將我們的算法在該數據集上做內部評估。
長遠來看,我們將會考慮整個人臉識別系統的設計,即包括人臉檢測、人臉對齊(有些學者認爲不重要,但我們覺得還是要取決于實際應用場景,有的可能根本不需要68個標定點,但有的場景可能需要的更多)和人臉檢測與識別的整套系統。最終目標是開發出人臉識別領域有突破的産品。此外,人臉識別最大的挑戰就是對雙胞胎的識別,然而這方面的數據並不太容易收集,我們對嘗試解決這個挑戰有非常大的興趣。
最後,一個讓整套人臉檢測與識別系統變得真實可用的技術就是活體檢測,比較成熟和落地的方法是需要被檢測對象配合的交互式動作活體檢測,如點頭,眨眼甚至唇語加語音數據聯合判斷。而靜默活體檢測則包括基于全局和局部特征分析、基于特征點對齊、基于微紋理、基于微表情,還有通過增加紅外攝像頭捕獲材質表面的反射特性。最近,由騰訊提出的光線活體檢測又將靜默活體檢測技術向前推進了一步,采用了和蘋果公司相同的3D結構光原理,不同的是三維重構的方式不同。我們研究院也很關注這方面的進展,但並無相關技術積累,這也正好爲我們尋求外部合作提供了可能。
解決人臉識別,對于性能和精度的追求將永不停歇
新智元:最後問一個比較大的問題:距離解決人臉識別,我們還有多久?人臉識別子任務中,哪些可以算已經解決,接下來最有可能被解救的是什麽?爲此需要做什麽?
距離解決人臉識別問題,我們還有多久? 這個問題確實不好回答,我們無法給出具體期限,因爲每當解決一個子問題的時候,你會發現又有新的子問題産生,但我們相信這一天不會多遙遠,或許很快就能來臨。事實上,對于可控的約束條件下,在被攝者完全配合的場景中,如正面證件照、正面的大頭照以及正面的網絡攝像頭采集的面部照片,對于1:1的人臉驗證問題,很多基于深度學習的算法都已經可以獲得接近99.9%甚至100%的性能,並且也都已經落地到成熟的産品中,如現今火熱的手機刷臉解鎖、機場或車站的刷臉進站以及刷臉支付,刷臉時代確確實實離我們越來越近。
對于無約束條件下,在被攝者不完全配合的場景中,接近正面的面部照片如LFW人臉數據,對于1:1的人臉驗證問題,同樣很多基于深度學習的算法都超過了人類97.53%的水平達到99.83%的新高度。這也證明在無約束條件下,對于接近正面的人臉驗證問題也基本得到了解決。但是對于像IJB-A這樣的人臉數據,在完全無約束條件下,被攝者完全不配合的場景中,很多被拍攝者的面部姿態變化巨大,光照變化劇烈以及由于采集裝置的多樣性導致具有不同的分辨率,面對這些挑戰,很多基于深度學習的算法都還有進一步提升的空間。
這也是我前面說的,盡管該挑戰賽目前已經落下帷幕,但是在該數據集上對性能和精度的追逐不會就此停歇,希望這將是下一個被拯救的子問題。我們希望對人工智能深度學習的研究,尤其人臉驗證與識別這個子任務,工業界與學術界一起合作,共同推動人臉識別乃至整個人工智能領域到另一個新高度。
-
熊霖 Panasonic R&D Center Singapore 研究工程師,西安電子科技大學模式識別與智能系統專業博士,專注于無約束/大規模人臉識別,深度學習架構工程,遷移學習等方面的研究。https://github.com/bruinxiong,https://www.researchgate.net/profile/Lin_Xiong4/contributions
-
趙健 NUS LV Group 在讀博士,專注于以人爲中心的基于深度神經網絡模型與算法的圖像理解方面的研究,包括人臉識別、圖像生成以及細粒度人物圖像解析等。http://www.lv-nus.org/,https://zhaoj9014.github.io
-
徐炎 Panasonic R&D Center Singapore 研究工程師,西安電子科技大學電子與通信工程專業碩士,專注于人臉檢測、配准及識別模塊的研究與設計。
新加坡松下研究院成立于1990年,致力于多媒體和網絡,機器學習,人工智能,計算機視覺及3D技術算法的軟硬件的研發。在申省梅的帶領下,我們在人工智能特別是人臉識別領域積累了多年的技術和大量的數據。
新加坡國立大學學習與視覺組(NUS LV Group)由顔水成教授創建,馮佳時教授領軍,是目前各大學術機構在深度學習與計算機視覺領域的頂級團隊之一。其人臉識別團隊一直是LV組中不可或缺的頂梁柱並屢創佳績。
[1] L. Xiong, J. Karlekar, J. Zhao et al. A Good Practice Towards Top Performance of Face Recognition: Transferred Deep Feature Fusion. arXiv preprint arXiv: 1704.00438, 2017.
[2] Y. Xu, Y. Cheng, J. Zhao Z. Wang, L. Xiong et al. High Performance Large Scale Face Recognition with Multi-Cognition Softmax and Feature Retrieval. ICCV 2017 Workshop.
[3] J. Zhao, L. Xiong et al. Dual-Agent GANs for Photorealistic and Identity Preserving Profile Face Synthesis. NIPS 2017.
[4] A. Shrivastava, et el. Learning from simulated and unsupervised images through adversarial training. CVPR 2017.
[5] O. M. Parkhi, et al. Deep Face Recognition. BMVC 2015.
[6] S. Sengupta, et al. Frontal to profile face verification in the wild. WACV 2016.
[7] F. Schroff, et al. FaceNet: A Unified Embedding for Face Recognition and Clustering. CVPR 2015.
[8] C. Ding, et al. Robust Face Recognition via Multimodal Deep Face Representation. IEEE TMM 2015
[9] I. Masi, et al. Pose-Aware Face Recognition in the Wild. CVPR 2016.
[10] R. Huang, et al. Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis. ICCV 2017.
[11] L. Tran, et al. Representation Learning by Rotating Your Faces. IEEE TPAMI 2017.
[12] R. Gross, et al. Multi-PIE. IVC 2010.
[13] G. B. Huang, et al. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. Technical Report 07-49, University of Massachusetts, Amherst, October 2007.
[14] N. Kumar, et al. Attribute and simile classifiers for face verification. In Computer Vision, 2009 IEEE 12th International Conference on, pages 365-372. IEEE, 2009.
[15] L. Wolf, et al. Face recognition in unconstrained videos with matched background similarity. In IEEE Computer Vision and Pattern Recognition, pages 529-534. IEEE, 2011.
[16] D. Yi, et al. Learning face representation from scratch. arXiv preprint arXiv:1411.7923, 2014.
[17] I. Kemelmacher-Shlizerman, et al. The megaface benchmark: 1 million faces for recognition at scale. CVPR 2016.
[18] Y. Guo, et al. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. ECCV 2016.
[19] B. F. Klare, et al. Pushing the frontiers of unconstrained face detection and recognition: IARPA Janus Benchmark A. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
加入社群
新智元AI技術+産業社群招募中,歡迎對AI技術+産業落地感興趣的同學,加小助手微信號: aiera2015_1 入群;通過審核後我們將邀請進群,加入社群後務必修改群備注(姓名-公司-職位;專業群審核較嚴,敬請諒解)。
此外,新智元AI技術+産業領域社群(智能汽車、機器學習、深度學習、神經網絡等)正在面向正在從事相關領域的工程師及研究人員進行招募。