一、背景介紹
攜程一直注重用戶的服務效率與服務體驗,在售前、售中、售後全過程中給用戶提供高效的客服支持。
用戶訪問客服頁面後,會首先與智能客服進行對話,當智能客服給出的回答無法解決用戶問題時便會接入人工客服,再由人工客服給出專業的解答。對話完成後,系統根據人工客服會話內容,應用NLP相關技術給出會話類別。這一結果將直接指導客服的管理與決策。本文將主要介紹攜程機票在人工客服會話分類時使用的相關NLP技術和優化方案。
圖1-1 智能客服會話與客服會話
二、問題分析
人工客服會話分類時主要使用的數據是客服與用戶的文本對話內容,本質上是NLP(自然語言處理)領域中文本分類的問題。文本分類的應用領域如文檔主題分類、情感分類、垃圾郵件分類等。現階段經典的文本分類方法包括:基于統計數據特征構建文本分類模型、基于詞向量和深度學習網絡構建文本分類模型、基于預訓練語言模型構建文本分類模型。
傳統的文本分類方法通常是基于統計數據構建文本特征,然後采用線性模型、SVM支持向量機模型等進行文本分類。傳統文本分類方法中的文本表示方式包括布爾模型、向量空間模型、概率模型、潛語義模型等,如圖2-1所示。
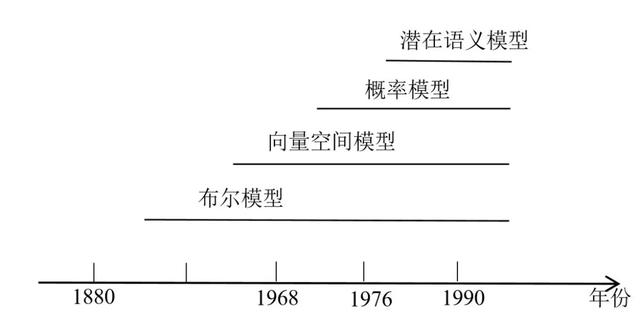
圖2-1 文本表示方式
隨著深度學習的發展與應用,文本表示方式也發生了變化,可以直接將文本中的字或詞作爲輸入,在如CNN (convolutional neuralnetworks,卷積神經網絡) 或LSTM (recurrent neuralnetworks based on long short-term memory,長短期記憶人工神經網絡) 等網絡結構中加入embedding層 (嵌入層) ,而後自動獲取文本的特征表達。embedding層是將高維向量映射到低維空間的過程,經典的embedding方法如word2vec是將詞轉化成可計算的結構化向量。Word2vec包含兩種訓練模式CBOW (ContinuousBag-of-Words Model) 和Skip-gram (Continuous Skip-gram Model) (如圖2-2所示)。CBOW是通過上下文來預測當前詞,Skip-gram是以當前詞作爲特征來預測上下文。由于 Word2vec 會考慮上下文,相較于傳統的文本表示方法效果更好。
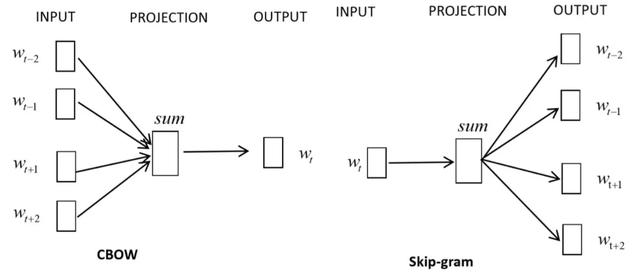
圖2-2 Word2vec的兩種訓練模式
2018年左右,注意力機制 (Attention) 被廣泛地應用到自然語言處理任務中。Attention是模仿人腦中的信號處理機制,即人類視覺在觀察圖像時,會在一些局部區域上投入注意力,重點關注。Attention的本質可以被描述爲一個查詢 (query) 到一系列 (鍵key-值value) 對的映射,如圖2-3所示。在文本分類任務中,可以通過引入self-attention機制的方式識別長文本中不同詞語在不同類別的重要性。self-attention機制即自己注意自己,簡單地說在self-attention中Query=Key=value,每個詞會與同一句話中另外的詞做計算,這樣更能夠把握句子中詞與詞的句法特征、語義特征。
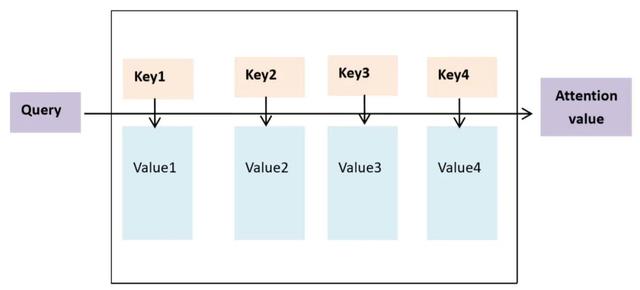
圖2-3 Attention 鍵值對映射
近年來,隨著Transformer架構的提出,一大批預訓練語言模型刷新衆多NLP任務,如Bert、XLNet等。這些模型首先使用大規模文本語料庫進行預訓練,並對特定任務的小數據集微調,降低單個NLP 任務的難度。
其中,經典的預訓練語言模型BERT (Bidirectional Encoder Representations from Transformers) 誕生于2018年10月,不久便占據GLUE各大任務的榜首,其中涉及情感分析、自然語言推斷、文本含義分析與分類等。BERT由谷歌推出並已開源,成爲近幾年NLP領域具有非凡意義的裏程碑,大力推動了NLP項目在工業界的落地。
如圖2-4所示,BERT基于Transformer架構,是一個由Transformer-Encoder部分組成的雙向語言模型,包括輸入嵌入層 (Embedding Layers) 、編碼層 (Encoder Layers) 和輸出預測層 (PredictionLayers) 三大組件。其中嵌入層包含對輸入詞句的TokenEmbedding,PositionEmbedding和SegmentEmbedding三種表征操作。
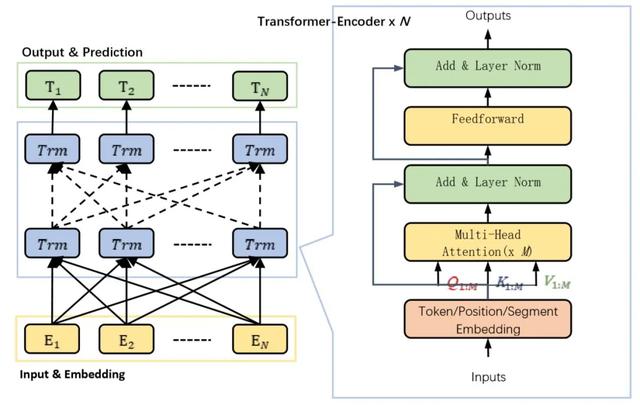
圖2-4 BERT結構簡示圖
三、數據處理
在建模之前,我們首先對人工會話數據進行預處理。如圖3-1所示,現有的人工會話數據中包括了中文、特殊字符如標點符號、數字、表情符號等,我們首先處理中文、特殊字符。其次,由于文本長度不一致,仍需做文本等長處理。
3.1 中文處理
中文處理包括固定話術、繁體簡體轉換、同義詞替換、分詞。
(1)固定話術
用戶與客服對話的過程中,會有一定的固定話術,如“管家_遊遊爲您服務,請問有什麽可以幫助您的?”這些固定話術存在于每個文本中,對分類沒有特別大的幫助,因此在數據處理過程中,我們就會使用正則匹配的方式去除固定話術。
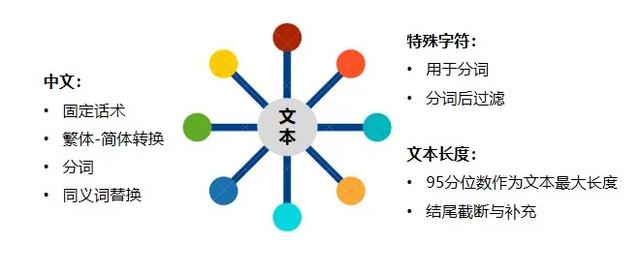
圖3-1 數據處理
(2)繁體簡體轉換
數據處理時,我們將會話中的繁體轉爲簡體。
(3)分詞
中文分詞是指把一句話切割成不同的詞,我們推薦使用jieba或HanLP作爲分詞工具。這些工具在分詞時都會使用自帶的詞典,也提供了自定義詞典的添加功能。我們分析會話數據後,定義了機票行業特有的詞典並加入分詞工具中,以提高分詞的准確率。
(4)同義詞替換
不同用戶在咨詢同一事件時的表述往往不同,如在咨詢“金牌服務包”增值産品時,用戶會表達爲“服務包”、“金牌包”、“金牌服務”。因此,在數據處理過程中,我們定義了機票行業特有的同義詞替換表,並將會話中的詞語進行同義詞替換,便于後續建模。
3.2 特殊字符處理
特殊字符主要包括標點符號、數字、表情符號等,這類字符都是需要過濾掉的。句子中的標點符號如逗號、句號等有分割句子的作用,因此在分詞前保留,分詞後再去除。
3.3 文本等長處理
在將文本投入模型之前,需要把分詞後的句子轉化爲相同長度的向量,這就意味著我們需要對過長的文本進行截取,對過短的文本進行補充。在文本截取與補充的過程中,主要看文本長度分布,將95分位數的文本長度作爲最大長度。
四、建模與優化
人工客服會話分類的建模過程中,我們主要嘗試了詞向量+深度神經網絡的分類模型、詞向量+深度神經網絡+注意力機制的分類模型、預訓練語言模型。詞向量+深度神經網絡的分類模型選用的是Bi-GRU,詞向量+深度神經網絡+注意力機制的分類模型分別嘗試了Bi-GRU+self-Attention、HAN,預訓練語言模型選用的是經典的Bert。
我們將Bi-GRU模型作爲後續優化的參照(baseline模型),通過對誤差數據的分析,嘗試多種優化方案,最終采用改進的Bi-GRU+self-Attention模型,實現人工客服會話在12個類別上的分類准確率提升6.2%。
4.1 參照模型
數據處理完成後,使用Bi-GRU進行建模,並將模型效果作爲後續優化的參照。Bi-GRU (BidirectionalGate Recurrent Unit) 是雙向循環神經網絡的一種。由于循環神經網絡很難處理長距離的依賴,容易出現梯度消失和梯度爆炸的問題,因此SeppHochreiter 、 JürgenSchmidhuber提出長短時記憶網絡 (Long-ShortTerm Memory,LSTM) ,LSTM是由遺忘門 (forget gate) 、輸入門 (input gate) 、輸出門 (output gate) 組成的循環神經網絡。GRU (GatedRecurrent Unit) 是LSTM的變體,它對LSTM做了很多簡化,同時保持著和LSTM相同的效果。GRU對LSTM做了兩個大改動:
(1)將輸入門、遺忘門、輸出門變爲兩個門:更新門 (UpdateGate) 和重置門 (ResetGate) 。
(2)將單元狀態與輸出合並爲一個狀態。
GRU單元內部計算邏輯如圖4-1所示。
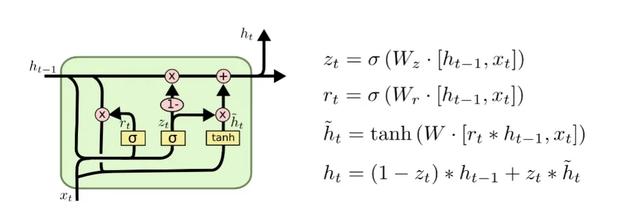
圖4-1GRU單元內部計算邏輯
4.2 Badcase分析
通過Bi-GRU模型我們獲得了12類各類別准確率及整體准確率78.12%。其中分類正確率低于60%的類別爲“預訂”、“支付”、“X産品”,分類正確率低于70%且會話量大的類別爲“訂單查詢修改”。我們著重分析這幾類的錯誤原因。
(1)缺乏對詞語重要性的表示
如圖4-2所示,預訂類別的會話通常會被誤判爲訂單查詢修改(占比63%)、增值服務(占比19%)、X産品(10%)。如下兩個會話:
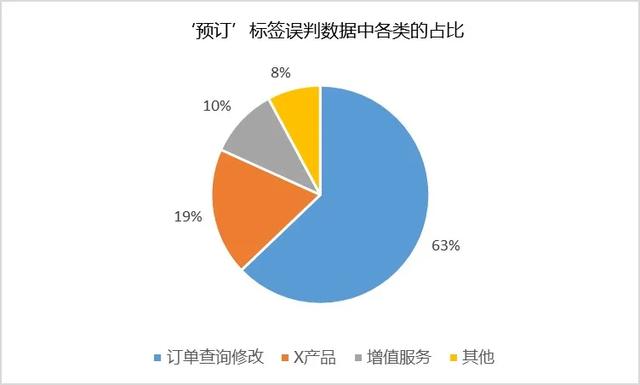
圖4-2 ‘預訂’標簽誤判數據中各類別占比
S1: 你好,我從上海回新加坡這趟行程需要托運古筝,長165cm左右的超長行李,重量不會超過20kg,請問東航可以運送嗎?……。(訂單查詢修改)
S2: 您好,我要買一個票,然後乘客的名字太長了,然後說這邊人工幫我訂,從新加坡到上海,需要行李托運。(預訂)
對于上述兩個會話,都包含了如“上海”、“新加坡”、“托運”、“行李”等詞語,但會話S1“上海回新加坡這趟行程”表明了已經有機票,是在咨詢特定機票的政策等信息,其業務類別標簽是訂單查詢修改。會話S2的業務類別是預訂,在該會話中“買一個票”充分表明了用戶要買票的意圖。
因此,我們認爲相同的詞語在不同的標簽下其重要性是不同的,比如“上海”和“新加坡”都出現兩個會話中,但由于出現的位置、前後關聯的詞語不一致,其對分類的重要性也就不同,在模型的優化過程中可以考慮加入注意力監聽機制。
(2)未能正確識別行業詞彙
對于“支付”和“X産品”這兩個類別,會話在分詞時准確率就有一定的損失。如下會話:
S3:金牌服務包是什麽?金牌服務包是包含40元接送機券,8元免一次同艙改簽手續費。
其在分詞時被分爲:[‘金牌’,’服務’,’包是’,’什麽’,’?’,’金牌’,’服務’,’包是’,’包含’,’40’,’元’,’接送’,’機券’,’,’,’8′,’元免’,’一次’,’同艙’,’改簽’,’手續費’,’。’]
但其實“金牌服務包”是攜程機票推出的一個服務産品,在分詞時不應當被拆分,因此一方面,我們總結出這些行業詞彙,並將其加入到jieba的自定義詞典中。另一方面,分詞的准確率直接影響了後續文本分類模型的准確率,我們嘗試通過Bert等預訓練語言模型降低分詞准確率的影響。
(3)上下文特征未能充分表達
上下文特征通常是指用戶會話時所處的場景特征,在模型中引入上下文場景特征有利于業務經驗的表達,如下會話:
S4:超重行李怎麽購買?##請您稍等哦~ 我查看下訂單哦##好的呦##幫您核實您訂單沒有免費托運行李的,您需要購買多少KG呢?…(增值服務)
S4中的用戶是一個無行李額出行的用戶。因此,可考慮將用戶咨詢時的上下文場景信息如用戶本身的信息提取出作爲特征加入到模型中。
4.3 優化過程
依據上述badcase的分析,我們進行如下優化。
(1)針對錯誤原因1:缺乏對詞語重要性的表示。
在優化過程中首先考慮將Self-Attention與循環神經網絡進行組合。嘗試的模型包括Bi-GRU+Self-Attention、HAN。
- Bi-GRU+Self-Attention
Bi-GRU+Self-Attention模型結構如下圖4-4所示,在Bi-GRU的輸出層後加入Self-Attention,用于監聽每個詞的重要性。
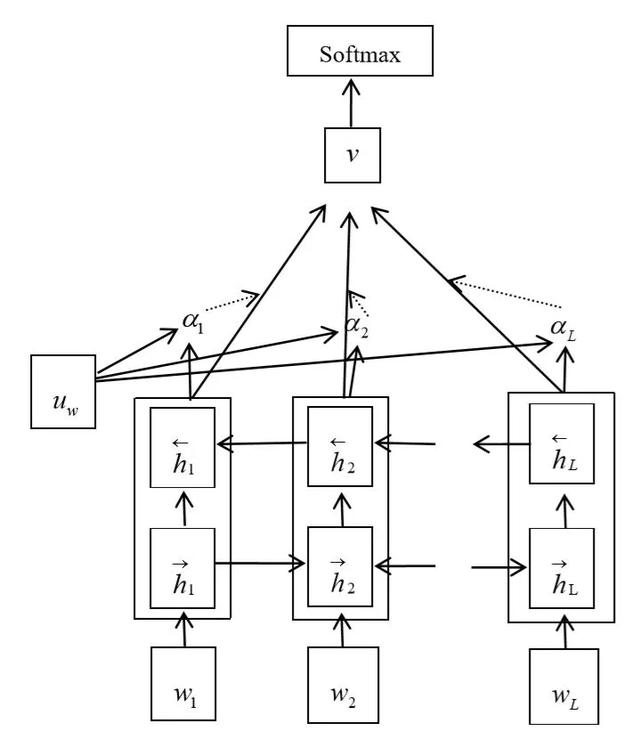
圖4-4 Bi-GRU+Self-Attention模型結構
- HAN
HAN (HierarchicalAttention Network for Document Classification) 是由ZichaoYang,DiyiYang等針對文檔級別的分類任務提出的分級注意力模型。如圖4-5所示,該模型有兩個層次的attention機制,分別應用于單次級別和句子級別。attention機制讓模型基于不同的單詞和句子給予不同的注意力權重,讓最後的文檔表示更精確、有效。
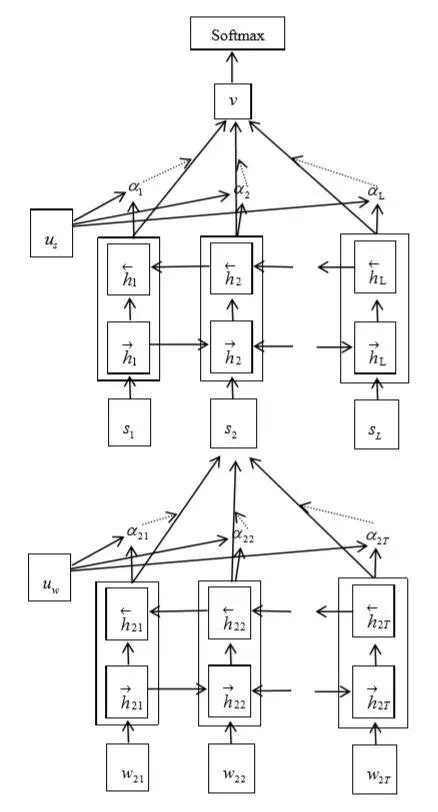
圖4-5 HAN模型結構
(2)針對錯誤原因2:未能正確識別行業詞彙。
除了在數據處理過程中添加行業詞彙,我們還嘗試了近年來比較火的預訓練語言模型如 Bert進行了建模。其好處在于在處理中文相關任務時,可直接基于單字學習字向量,避免了印歐語系的分詞誤差,而且字向量遠少于詞向量,有效避免場景OOV (Out of Vocabulary) ,並且大幅縮減模型體積和複雜度。Bert建模過程中使用預訓練的詞向量作爲特征,並在已有的數據集中進行微調。
(3)針對錯誤原因3:上下文特征未能充分表達
采用改進的Bi-GRU+Self-Attention。如圖4-6所示,我們在Bi-GRU+Self-Attention的基礎上加入上下文場景特征,將這些特征處理成類別型變量,輸入到模型中,最終該模型實現人工客服會話在12個類別上的分類准確率提升6.2%。
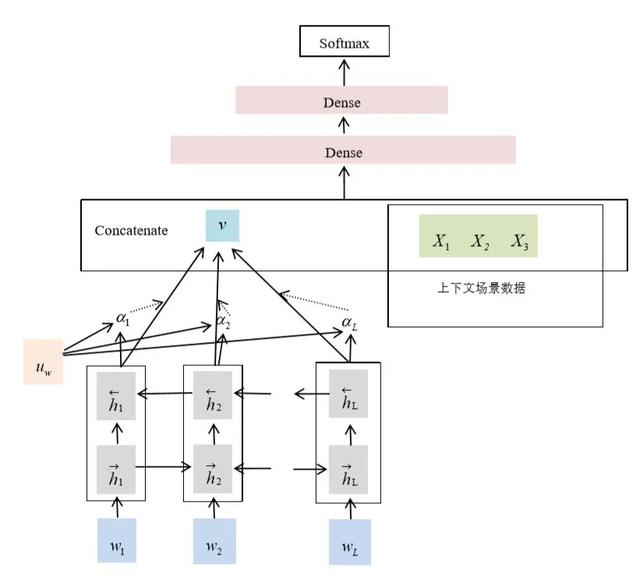
圖4-6 改進的Bi-GRU+Self-Attention
各模型的訓練效果如表4-1所示。從訓練效果來看,相對于Bi-GRU+Self-Attention(80.13%)、HAN(80.97%),Bert取得的准確率爲82.84%,提升非常明顯。引入強規則特征後改進的Bi-GRU+Self-Attention效果達到了84.47%。
|
表4-1 各模型訓練效果 |
|
|
模型 |
准確率 |
|
Bi-GRU |
78.12% |
|
Bi-GRU+Self-Attention |
80.13% |
|
HAN |
80.97% |
|
Bert |
82.84% |
|
改進的Bi-GRU+Self-Attention |
84.47% |
五、總結
文章首先介紹了人工客服會話分類的背景,並從問題分析、數據處理、建模與優化三個部分介紹NLP技術在攜程機票人工客服會話分類中的應用。
在問題分析部分,我們討論了文本分類的幾種經典的方法,包括基于統計學特征構建分類模型、采用詞向量+深度神經網絡構建分類模型、采用預訓練語言模型進行分類。數據處理部分,介紹了人工會話數據的預處理方式。建模與優化部分,對badcase進行分析並總結三類錯誤原因,針對這三類錯誤原因給出可行的優化方案。
我們嘗試了多種文本分類模型,並在分類效果上取得不斷地提升,後續可以將預訓練語言模型和上下文特征進行組合,進一步提升模型分類的准確率。
【作者簡介】毛毛,攜程高級數據挖掘工程師,熱愛自然語言處理和推薦系統。