金磊 發自 凹非寺
量子位 報道 | 公衆號 QbitAI
一聽到訓練大模型,是不是第一感覺就是貴、燒錢、玩不起?
但我說,一台4000多塊錢的遊戲電腦,誰都能訓練上億參數的大模型呢?
別不信,這是真的。
而這就歸功于微信AI團隊,最近推出的一款利器——派大星。

但不是你印象中的那個派大星昂~
微信AI的派大星(PatricStar),其實是一個超大預訓練模型訓練系統。

要知道,在這個領域中,以往都是微軟DeepSeed獨占鳌頭。
此次微信一出手,可以說是直接秒殺了微軟:
在 8xV100 和 240GB CPU 內存節點上,訓練了一個120 億參數的 GPT 模型,是當前最佳方案DeepSpeed模型規模上限的1.5 倍。
但畢竟針對的是大模型,“燒錢”是出了名的難題。
而微信AI的派大星就顯得相當的親民了。
即使在700美元的個人遊戲電腦上,它也可以訓練一個7億參數的 GPT 模型!
現在,人人都可以在家訓練大模型了!

劃重點:已開源!
爲什麽要搞派大星?
大規模預訓練模型,已然成爲技術發展中的新潮流。
以BERT、GPT爲代表的預訓練模型的出現,可以說是自然語言處理(NLP)領域的裏程碑事件。
NLP,正在進入了預訓練時代。

那麽像派大星這樣的訓練系統,真的有必要嗎?
答案是肯定的。
從技術角度來看,預訓練模型(PTM)通常使用一個堆疊了多個Transformer結構神經網絡,在大量文本上預訓練通用語言特征表示。
然後,通過微調將學到的知識轉移到不同的下遊任務。
預訓練模型使用大量來自互聯網的文本數據,可以捕獲自然語言的細微特征,並在下遊任務上獲得非常驚豔的表現效果。
于是,AI社區的共識是采用預訓練模型,作爲特定NLP任務的主幹,而不是在與任務相關的數據集上從頭開始訓練模型。
預訓練模型的力量源泉,是它擁有的數以億計的參數規模,這對運行它的計算和內存資源都提出了巨大的要求。
因此,預訓練模型訓練仍是一小部分人的遊戲。
所有發表百億級模型訓練成果的團隊,所采用的的設備都是如DGX型號的AI超級計算機。
它的一個節點就配置了8張GPU,1.5TB內存,3.84TB SSDs,還使用NVLink作爲高速通信網絡。
目前最大的預訓練模型Megatron-Turing,包含5300億參數,其預訓練過程就是在560個DGX A100節點的集群上完成的。
這種配置在大多數工業界數據中心都是遙不可及的。
而通過像派大星這樣的訓練系統,便可以讓這種“遙不可及”變得“唾手可得”,讓大模型可以普惠到更多的開發人員,實現PTM的“共同富裕”。
再從綠色AI角度來看,預訓練模型的預訓練的過程是極其燒錢和有害環境的。

比如,從頭訓練型一次萬億級別的預訓練模型要燒掉154萬人民幣,耗電所産生的碳排放相當于數十輛小汽車從出廠到報廢的碳排放總和。
出于社會利益最大化考慮,預訓練技術未來的産業形態,應該是中心化的:
少部分財力雄厚的機構,用超大規模集群承擔預訓練階段的計算和環境開銷;大多數從業人員在小規模、相對簡陋的硬件上針對自身業務進行微調。
前者只需要相對少量的計算和碳排放,而後者的訴求卻被當前的預訓練軟件所嚴重忽略。
現如今,派大星的到來,讓大規模預訓練模型的訓練變得“多快好省”了起來。
而且不僅是對于機構,更是有益于個人開發者。
……
那麽派大星的效果,具體又怎樣呢?
不是魔改,是從頭搭建,性能達SOTA
值得一提的是,派大星並不是基于DeepSpeed的魔改,代碼是團隊從頭開始搭建起來的。
派大星框架非常直觀的一個特點,便是簡單易用,而且還是可以兼容其他並行方案的那種。
例如,開發者可以使用幾行代碼端到端的加速PyTorch的訓練過程。
from patrickstar.runtime import initialize_engineconfig = {“optimizer”: {“type”: “Adam”,”params”: {“lr”: 0.001,”betas”: (0.9, 0.999),”eps”: 1e-6,”weight_decay”: 0,”use_hybrid_adam”: True,},},”fp16″: { # loss scaler params”enabled”: True,”loss_scale”: 0,”initial_scale_power”: 2 ** 3,”loss_scale_window”: 1000,”hysteresis”: 2,”min_loss_scale”: 1,},”default_chunk_size”: 64 * 1024 * 1024,”release_after_init”: True,”use_cpu_embedding”: False,}def model_func():# MyModel is a derived class for torch.nn.Modulereturn MyModel(…)model, optimizer = initialize_engine(model_func=model_func, local_rank=0, config=config)…for data in dataloader:optimizer.zero_grad()loss = model(data)model.backward(loss)optimizer.step()
接下來,我們一起看一下派大星的性能效果。
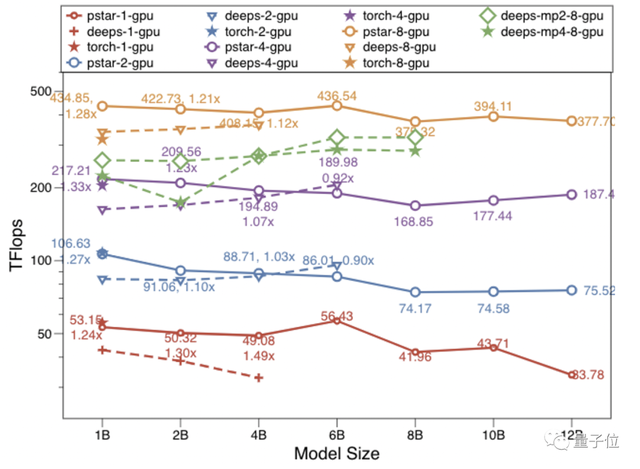
上圖便展示了DeepSpeed stage3,PyTorch系統在 1、2、4、8 個 GPU 上的性能(y軸通過對數方式重新縮放)。
這些點代表在一個 GPU 上使用 4、8、16、32 和 64 批大小測試的最佳結果。
(注:圓點周圍的值表示派大星在吞吐量及其對DeepSpeed的加速;deeps是DeepSpeed僅使用數據並行的效果,我們接下來稱之爲DeepSpeed-DP,deeps-mpX 是 DeepSpeed使用X路的模型並行結果;模型的計量單位是B表示十億Billon。)*
PyTorch 僅適用于 1B 模型大小的情況,派大星在8個GPU上比PyTorch快1.37倍,在 1、2、4 個 GPU 情況下與 PyTorch 相似。
使用相同的零冗余優化器來實現數據並行,派大星在大多數情況下(14 個中有 12 個)優于 DeepSpeed-DP,並且數據並行方式訓練8B和12B之間模型大小的唯一解決方案。
不難看出,尤其是針對小模型,改進是非常明顯了(0.90x-1.49x)。
而在增加模型大小時,派大星不會顯著降低計算效率。
此外,派大星在增加 GPU 數量時顯示出超線性可擴展性。
若是將派大星與模型並行解決方案進行了比較,又會是怎樣的結果?
例如在上圖中,還比較了DeepSpeed在8個GPU卡上使用Zero-DP方案疊加2路模型並行和4路模型並行的性能。
派大星在所有測試用例上實現了最大的模型規模120億參數,以及最佳的性能效率。
在模型並行的幫助下,DeepSpeed將模型規模擴展到了80億參數。
但是,MP引入了更多的通信開銷;性能明顯低于派大星和 DeepSpeed-DP。
……
效果是有夠驚豔的了,但接下來的一個問題便是:
關鍵技術是什麽?
破局者:異構訓練
或許你會說了,讓數據並行不就完事了嗎?
事實卻並非如此。
對于預訓練模型來說,最常用的數據並行技術不適用,這是因爲模型數據無法再容納在單個 GPU 的內存中。
GPU硬件的存儲規模上限,像一堵牆一樣限制住了PTM的可訓練規模,因此從業人員通常稱之爲”GPU內存牆”現象。

近兩年來,通過利用並行訓練在多個 GPU 內存之間分配模型數據,例ZeRO-DP、模型並行、流水線並行嘗試使 PTM 大小突破內存牆。
但是,使用這些技術又需要不斷擴大GPU規模,也意味著更高設備的投入,那麽此局怎麽破?
異構訓練技術,了解一下。
它不僅可以顯著提升單GPU訓練模型的規模,而且可以和並行訓練技術正交使用。
異構訓練通過在CPU和GPU中,容納模型數據並僅在必要時將數據移動到當前設備來利用 GPU 內存、CPU 內存(由 DRAM 或 NVMe 內存組成)。
其他方案如數據並行、模型並行、流水線並行,都在異構訓練基礎上進一步擴展GPU規模。
預訓練模型在訓練期間,存在必須管理的兩種類型訓練數據:
- 模型數據由參數、梯度和優化器狀態組成,其規模與模型結構定義相關;
- 非模型數據主要由算子生成的中間張量組成,根據訓練任務的配置動態變化,例如批量大小。
模型數據和非模型數據相互競爭GPU內存。

然而,目前最佳的異構訓練方案DeepSpeed的Zero-Offload/Infinity,仍存在很大優化空間。
在不考慮非模型數據的情況下,DeepSpeed在CPU和GPU內存之間靜態劃分模型數據,並且它們的內存布局對于不同的訓練配置是恒定的。
這種靜態分區策略會導致幾個問題。
首先,當GPU內存或CPU內存不足以滿足其相應的模型數據要求時,即使當時其他設備上仍有可用內存,系統也會崩潰。
其次,當數據以張量爲粒度的不同內存空間之間傳輸時通信效率低下,並且當你可以預先將模型數據放置在目標計算設備上時,一些CPU-GPU通信量是不必要的。
因此DeepSpeed在微信的數據中心單GPU只能運行60億參數的模型,而且效率十分低下,遠不如在DGX上的報告結果130億參數。
派大星則通過以細粒度的方式管理模型數據,以更有效地使用異構內存來克服這些缺點。
它將模型數據張量組織成塊,即相同大小的連續內存塊。
塊在異構內存空間中的分布在訓練期間根據它們的張量狀態動態編排。
通過重用不共存的塊,派大星還比DeepSpeed的方案進一步降低了模型數據的內存占用。
派大星使用預熱叠代來收集運行時模型數據可用 GPU 內存的統計數據。
基于收集到的統計數據的有效塊驅逐策略和設備感知算子放置策略,爲的就是減少 CPU-GPU 數據移動量。
最後,使用零冗余優化器(ZeroReduencyOptimizer)的Zero-DP數據並行方法,通過塊的集合GPU 通信來使用擴展到多個GPU。
團隊介紹
這項研究主要由騰訊微信AI團隊和新加坡國立大學團隊共同完成。

論文一作是來自微信AI的高級工程師Jiarui Fang,清華大學博士畢業。
其主要工作是通過創新並行計算技術提升在線和離線NLP任務的運算效率。
他曾經還曾開源過一款Tranformer模型推理加速工具TurboTransformer。
……
那麽最後,你是否也想訓練一個專屬的大模型呢?戳下方鏈接試試吧~
派大星開源地址:
https://github.com/Tencent/PatrickStar
論文地址:
https://arxiv.org/abs/2108.05818
— 完 —
量子位 QbitAI · 頭條號簽約
關注我們,第一時間獲知前沿科技動態