(獲取報告請登陸未來智庫www.vzkoo.com)
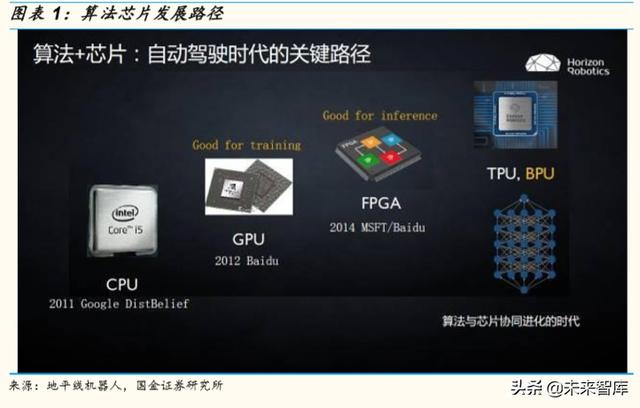
一、車載芯片的發展趨勢(CPU-GPU-FPGA-ASIC)
過去汽車電子芯片以與傳感器一一對應的電子控制單元(ECU)爲主,主 要分布與發動機等核心部件上。隨著汽車智能化的發展,汽車傳感器越來 越多,傳統的分布式架構逐漸落後,由中心化架構 DCU、MDC 逐步替代。
隨著人工智能發展,汽車智能化形成趨勢,目前輔助駕駛功能滲透率越來 越高,這些功能的實現需借助于攝像頭、雷達等新增的傳感器數據,其中 視頻(多幀圖像)的處理需要大量並行計算,傳統 CPU算力不足,這方面 性能強大的 GPU 替代了 CPU。再加上輔助駕駛算法需要的訓練過程, GPU+FPGA成爲目前主流的解決方案。
著眼未來,自動駕駛也將逐步完善,屆時又會加入激光雷達的點雲(三維 位置數據)數據以及更多的攝像頭和雷達傳感器,GPU 也難以勝任, ASIC 性能、能耗和大規模量産成本均顯著優于 GPU 和 FPGA,定制化的 ASIC 芯片可在相對低水平的能耗下,將車載信息的數據處理速度提升更快, 隨著自動駕駛的定制化需求提升,ASIC 專用芯片將成爲主流。本文以如上 順序梳理車載芯片發展曆程,探討未來發展方向。
二、車載芯片的過去—以 CPU 爲核心的 ECU
2.1 ECU的核心 CPU
ECU(Electronic Control Unit)是電子控制單元,也稱“行車電腦”,是 汽車專用微機控制器。一般 ECU 由 CPU、存儲器(ROM、RAM)、輸入/ 輸出接口(I/O)、模數轉換器(A/D)以及整形、驅動等大規模集成電路組 成。

ECU 的工作過程就是 CPU 接收到各個傳感器的信號後轉化爲數據,並由 Program區域的程序對 Data 區域的數據圖表調用來進行數據處理,從而得 出具體驅動數據,並通過 CPU針腳傳送到相關驅動芯片,驅動芯片再通過 相應的周邊電路産生驅動信號,用來驅動驅動器。即傳感器信號——傳感 器數據——驅動數據——驅動信號這樣一個完整工作流程。
2.2 分布式架構向多域控制器發展
汽車電子發展的初期階段,ECU 主要是用于控制發動機工作,只有汽車發 動機的排氣管(氧傳感器)、氣缸(爆震傳感器)、水溫傳感器等核心部件 才會放置傳感器,由于傳感器數量較少,爲保證傳感器-ECU-控制器回路 的穩定性, ECU 與傳感器一一對應的分布式架構是汽車電子的典型模式。
後來隨著車輛的電子化程度逐漸提高,ECU 占領了整個汽車,從防抱死制 動系統、4 輪驅動系統、電控自動變速器、主動懸架系統、安全氣囊系統, 到現在逐漸延伸到了車身各類安全、網絡、娛樂、傳感控制系統等。
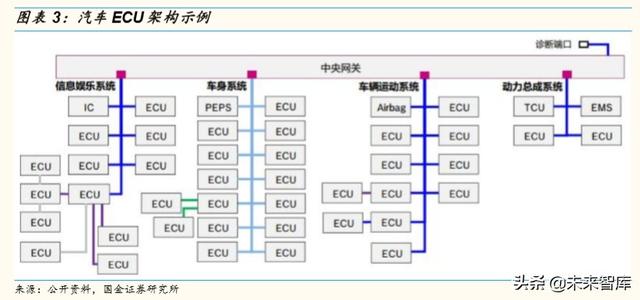
隨著汽車電子化的發展,車載傳感器數量越來越多,傳感器與 ECU一一對 應使得車輛整體性下降,線路複雜性也急劇增加,此時 DCU(域控制器) 和 MDC(多域控制器)等更強大的中心化架構逐步替代了分布式架構。
域控制器(Domain Control Unit)的概念最早是由以博世,大陸,德 爾福爲首的 Tier1 提出,是爲了解決信息安全,以及 ECU 瓶頸的問題。 根據汽車電子部件功能將整車劃分爲動力總成,車輛安全,車身電子, 智能座艙和智能駕駛等幾個域,利用處理能力更強的多核 CPU/GPU 芯片相對集中的去控制每個域,以取代目前分布式汽車電子電氣架構。
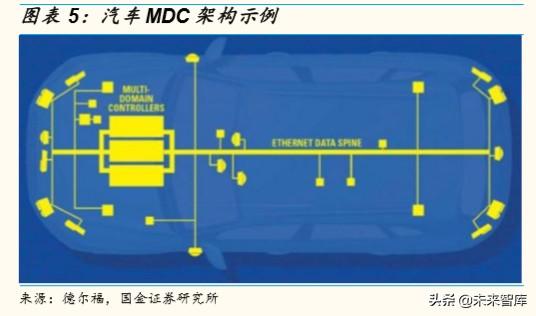
而進入自動駕駛時代,控制器需要接受、分析、處理的信號大量且複 雜,原有的一個功能對應一個 ECU的分布式計算架構或者單一分模塊 的域控制器已經無法適應需求,比如攝像頭、毫米波雷達、激光雷達 乃至 GPS 和輪速傳感器的數據都要在一個計算中心內進行處理以保證 輸出結果的對整車自動駕駛最優。
因此,自動駕駛車輛的各種數據聚集、融合處理,從而爲自動駕駛的 路徑規劃和駕駛決策提供支持的多域控制器將會是發展的趨勢,奧迪 與德爾福共同開發的 zFAS,即是通過一塊 ECU,能夠接入不同傳感 器的信號並進行對信號進行分析和處理,最終發出控制命令。
三、車載芯片的現在—以 GPU 爲核心的智能輔助駕駛芯片
人工智能的發展也帶動了汽車智能化發展,過去的以 CPU 爲核心的處理器越 來越難以滿足處理視頻、圖片等非結構化數據的需求,同時處理器也需要 整合雷達、視頻等多路數據,這些都對車載處理器的並行計算效率提出更 高要求,而 GPU 同時處理大量簡單計算任務的特性在自動駕駛領域取代 CPU成爲了主流方案。
3.1 GPU Vs. CPU
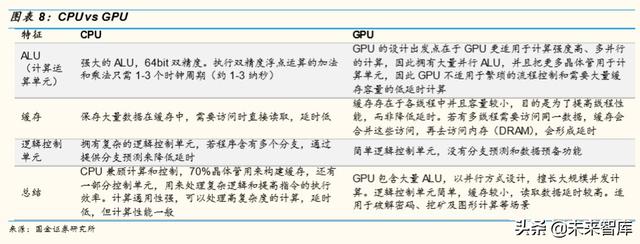
CPU 的核心數量只有幾個(不超過兩位數),每個核都有足夠大的緩存和足夠 多的數字和邏輯運算單元,並輔助很多複雜的計算分支。而 GPU 的運算 核心數量則可以多達上百個(流處理器),每個核擁有的緩存大小相對小, 數字邏輯運算單元也少而簡單。
CPU和 GPU最大的區別是設計結構及不同結構形成的不同功能。CPU的邏輯 控制功能強,可以進行複雜的邏輯運算,並且延時低,可以高效處理複雜 的運算任務。而 GPU邏輯控制和緩存較少,使得每單個運算單元執行的邏 輯運算複雜程度有限,但並列大量的計算單元,可以同時進行大量較簡單 的運算任務。

3.2 GPU占據現階段自動駕駛芯片主導地位
相比于消費電子産品的芯片,車載的智能駕駛芯片對性能和壽命要求都比較高, 主要體現在以下幾方面:
1、耗電每瓦提供的性能;
2、生態系統的構建,如用戶群、易用性等;
3、滿足車規級壽命要求,至少 1 萬小時穩定使用。
目前無論是尚未商業化生産的自動駕駛 AI 芯片還是已經可以量産使用的輔 助駕駛芯片,由于自動駕駛算法還在快速更新叠代,對雲端“訓練”部分 提出很高要求,既需要大規模的並行計算,又需要大數據的多線程計算, 因此以 GPU+FPGA 解決方案爲核心;在終端的“推理”部分,核心需求 是大量並行計算,從而以 GPU爲核心。
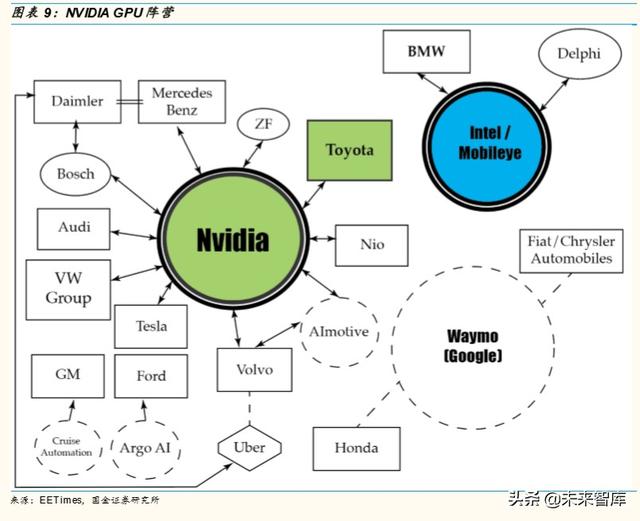
3.3 相關公司
3.3.1 NVIDIA
NVIDIA 在自動駕駛領域的成就正是得益于他們在 GPU 領域內的深耕, NVIDIA GPU 專爲並行計算而設計,適合深度學習任務,並且能夠處理在 深度學習中普遍存在的向量和矩陣操作。相對于 Mobileye 專注于視覺處理, NVIDIA 的方案重點在于融合不同傳感器。

目前,L4 及以上的市場基本上被 NVIDIA 壟斷,CEO 黃仁勳稱全球有 300 余家自動駕駛研發機構使用 Drive PX2。Drive PX 2 單價爲 1.6 萬美金,功 耗達 425 瓦,但目前沒有達到車規,按功耗和成本看,只能小規模測試階 段使用。
3.3.2 四維圖新
國內地圖行業龍頭,向 ADAS 和自動駕駛進軍。公司成立于 2002 年,是 國內首家獲導航地圖制作資質的企業(目前僅 13 家),爲領先的數字地圖 內容、車聯網與動態交通信息服務、基于位置的大數據垂直應用服務的提 供商之一。其拳頭業務——地圖業務,以國內 60%的份額穩居壟斷地位。 2017 年以來,公司收購傑發科技、入股中寰衛星與禾多科技,“高精度地 圖+芯片+算法+軟件”的自動駕駛産業鏈全方位布局雛形已現。
高精度地圖:代表國內最高水平。公司以地圖起家,目前國內高精度地圖 僅兩家玩家(另一家爲高德),公司深度綁定獲得寶馬、大衆、奔馳、通用、 沃爾沃、福特、上汽、豐田、日産、現代、標致等主流車企發展,占絕對 優勢。2017 年公司實現支持 L3 級別(至少 20 個城市)的高精度地圖,計 劃于 2019 年覆蓋所有城市,並爲 L4 的推出做准備。公司地圖編譯能力亮 眼,全球首位提供 NDS 地圖從生産到編譯環節。此外,公司在荷蘭、美國硅谷、新加坡等地設立研發中心和分支機構,合作夥伴涵蓋國際主流車廠、 新一代整車企業以及騰訊、滴滴、搜狗、華爲等國內知名企業。
芯片:收購傑發科技布局汽車芯片。傑發科技(2017 年 3 月完成收購)脫 胎于聯發科,主攻車載信息娛樂系統芯片。現階段在國內後裝市場市占率 超 70%,前裝超 30%(主要爲吉利、豐田等車企),其車規級 IVI 芯片被 多家國際主流零部件廠商采用,並計劃推出 AMP、MCU 及 TPMS(胎壓 監測)芯片等新一代産品。公司通過收購傑發科技,具備了爲車廠提供高 性能汽車電子芯片的能力,打通從軟件到硬件的關鍵性關卡,並與蔚來、 威馬、愛馳億維等造車新勢力公司達成了合作。
該芯片采用 64 位 Quad A53 架構,內置硬件圖像加速引擎,支持雙路高清 視頻輸出,和四路高清視頻輸入,能同時支持高級車載影音娛樂系統全部 功能和豐富的 ADAS 功能。功能包括:360°全景泊車系統、車道偏移警 示系統 LDW、前方碰撞警示系統 FCW、行人碰撞警示系統 PCW、交通標 志識別系統 TSR、車輛盲區偵測系統 BSD、駕駛員疲勞探測系統 DFM 和 後方碰撞預警系統 RCW等。

3.3.3 全志科技
在今年 5 月的 CES Asia,全志科技發布首款車規級處理器 T7,同時發布 基于 T7 的多種智能座艙産品形態。T7 是數字座艙車規(AEC-Q100)平 台型處理器,支持 Android、Linux、QNX系統,集成多路高清影像輸入和 輸出,完美支持高清多媒體處理,內置的 EVE 視覺處理單元可提升輔助駕 駛運算效率。
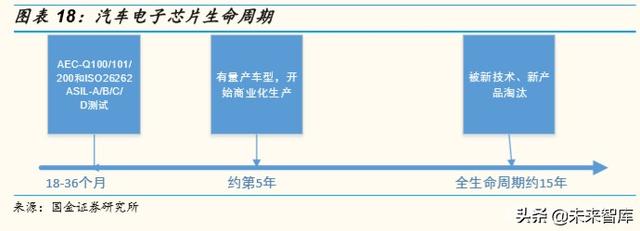
該款芯片雖然是首款通過車規的國産中控主機芯片,但還處于起步階段, 根據正常汽車電子芯片的生命周期,要規模應用至少需要兩年時間,而等 到形成較多的用戶和良好的生態還需很多資源投入以及時間的積累。因此 國産車載芯片不論在自動駕駛領域還是中控或輔助駕駛領域,想要真正形 成量産與國外老牌巨頭競爭,都還需要大量人力、資本和時間。
四、車載芯片的未來—以 ASIC 爲核心的自動駕駛芯片
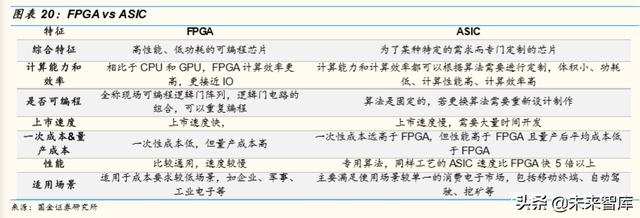
4.1 ASIC vs GPU+FPGA
GPU適用于單一指令的並行計算,而 FPGA與之相反,適用于多指令,單 數據流,常用于雲端的“訓練”階段。此外與 GPU對比,FPGA沒有存取 功能,因此速度更快,功耗低,但同時運算量不大。結合兩者優勢,形成 GPU+FPGA的解決方案。
FPGA 和 ASIC 的區別主要在是否可以編程。FPGA 客戶可根據需求編程, 改變用途,但量産成本較高,適用于應用場景較多的企業、軍事等用戶; 而 ASIC 已經制作完成並且只搭載一種算法和形成一種用途,首次“開模” 成本高,但量産成本低,適用于場景單一的消費電子、“挖礦”等客戶。目 前自動駕駛算法仍在快速更叠和進化,因此大多自動駕駛芯片使用 GPU+FPGA的解決方案。未來算法穩定後,ASIC將成爲主流。

計算能耗比,ASIC > FPGA > GPU > CPU,究其原因,ASIC 和 FPGA更 接近底層 IO,同時 FPGA有冗余晶體管和連線用于編程,而 ASIC是固定 算法最優化設計,因此 ASIC 能耗比最高。相比前兩者,GPU 和 CPU 屏 蔽底層 IO,降低了數據的遷移和運算效率,能耗比較高。同時 GPU 的邏 輯和緩存功能簡單,以並行計算爲主,因此 GPU能耗比又高于 CPU。
4.2 ASIC 是未來自動駕駛芯片的核心和趨勢
結合 ASIC 的優勢,我們認爲長遠看自動駕駛的 AI芯片會以 ASIC 爲解決 方案,主要有以下幾個原因:

綜上 ASIC 專用芯片幾乎是自動駕駛量産芯片唯一的解決方案。由于這種 芯片僅支持單一算法,對芯片設計者在算法、IC 設計上都提出很高要求。
以上並非下定論目前 ASIC 爲核心的芯片一定比 GPU+FPGA 的芯片強, 由于目前自動駕駛算法還在快速叠代和升級過程中,過早以固有算法生産 ASIC 芯片長期來看不一定是最優選擇。
4.3 相關公司
4.3.1 Mobileye
Intel 在 ADAS 處理器上的布局已經完善,包括 Mobileye 的 ADAS 視覺處 理,利用 Altera 的 FPGA 處理,以及英特爾自身的至強等型號的處理器, 可以形成自動駕駛整個硬件超級中央控制的解決方案。
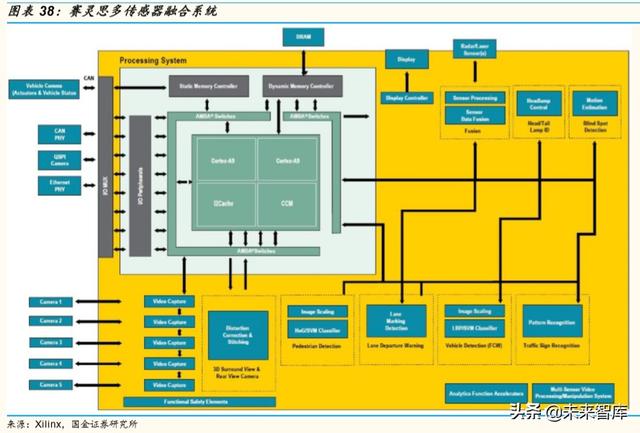
Mobileye 具有自主研發設計的芯片 EyeQ 系列,由意法半導體公司生産供 應。現在已經量産的芯片型號有 EyeQ1 至 EyeQ4,EyeQ5 正在開發進行 中,計劃 2020 年面世,對標英偉達 Drive PX Xavier,並透露 EyeQ5 的計 算性能達到了 24 TOPS,功耗爲 10 瓦,芯片節能效率是 Drive Xavier 的 2.4 倍。英特爾自動駕駛系統將采用攝像頭爲先的方法設計,搭載兩塊 EyeQ5 系統芯片、一個英特爾淩動 C3xx4 處理器以及 Mobileye 軟件,大 規模應用于可擴展的 L4/L5 自動駕駛汽車。該系列已被奧迪、寶馬、菲亞 特、福特、通用等多家汽車制造商使用。
從硬件架構來看,該芯片包括了一組工業級四核 MIPS 處理器,以支持多 線程技術能更好的進行數據的控制和管理(下圖左上)。多個專用的向量微碼處理器(VMP),用來應對 ADAS 相關的圖像處理任務(如:縮放和預 處理、翹曲、跟蹤、車道標記檢測、道路幾何檢測、濾波和直方圖等,下 圖右上)。一顆軍工級 MIPS Warrior CPU 位于次級傳輸管理中心,用于處 理片內片外的通用數據(下圖左中)。
此外通過行業訪談調研等途徑了解到,Mobileye 在 L1-L3 智能駕駛領域具 有極大的話語權,對 Tire1 和 OEM 非常強勢,其算法和芯片綁定,不允許 更改。

4.3.2 寒武紀
寒武紀科技在 2018 産品發布會上發布了多個 IP 産品——采用 7nm 工藝的終端芯片 Cambricon 1M、雲端智能芯片 MLU100 等。
其中寒武紀 1M芯片是公司第三代 IP産品,在 TSMC7nm工藝下 8 位運算 的效能比達 5Tops/w(每瓦 5 萬億次運算),同時提供 2Tops、4Tops、 8Tops 三種尺寸的處理器內核,以滿足不同需求。1M 還將支持 CNN、 RNN、SVM、k-NN 等多種深度學習模型與機器學習算法的加速,能夠完 成視覺、語音、自然語言處理等任務。通過靈活配置 1M 處理器,可以實 現多線和複雜自動駕駛任務的資源最大化利用。它還支持終端的訓練,以 此避免敏感數據的傳輸和實現更快的響應。
寒武紀首款雲端智能芯片 Cambricon MLU100 同期發布,同時公布了在 R-CNN算法下 MLU100 與英偉達 Tesla V100(2017)和英偉達 Tesla P4 (2016)的對比,從參數上看,主要對標 Tesla P4。
4.3.3 地平線
地平線星雲,基于征程 1.0 芯片,能夠以車規級標准滿足 L1 和 L2 級 別的自動駕駛的需求, 能同時對行人、機動車、非機動車、車道線、 交通標志牌、紅綠燈等多類目標進行精准的實時監測與識別;並可滿 足車載設備嚴苛的環境要求,以及複雜環境下的視覺感知需求,支持 L2 級別 ADAS功能。
地平線 Matrix 1.0,內置地平線征程 2.0 處理器架構,最大化嵌入式 AI 計算性能,是面向 L3/L4 的自動駕駛解決方案,可滿足自動駕駛場景 下高性能和低功耗的需求。依托地平線公司自主研發的工具鏈,開發 者和研究人員可以基于 Matrix 平台部署神經網絡模型,實現開發、驗 證、優化和部署。
4.3.4 百度“昆侖”
“昆侖”采用 14nm 三星工藝,是業內設計算力最高的 AI 芯片(100+瓦功耗 下提供 260Tops 性能);512GB/s 內存帶寬,由幾萬個小核心構成。
“昆侖”可高效地同時滿足訓練和推斷的需求,除了常用深度學習算法等雲端 需求,還能適配諸如自然語言處理,大規模語音識別,自動駕駛,大規模 推薦等具體終端場景的計算需求。此外可以支持 paddle 等多個深度學習框 架,編程靈活度高。
4.3.5 Google TPU
Google TPU 是專用的,並不面向市場,谷歌僅表示“將允許其他公司通過其 雲計算服務購買這些芯片。”今年 2 月,谷歌在其雲平台博客上宣布的 TPU 服務開放價格大約爲每 cloud TPU (180TFLOPS和 64 GB內存)每 小時 6.50 美元。Google 使用 TPU開發圍棋系統 AlphaGo 和 Alpha Zero 以及進行 Google 街景視頻文字處理等,能夠在不到五天的時間內找到街 景數據庫中的所有文字,此外 TPU也用于提供 Google 搜索結果的排序。
TPU與同期的 CPU和 GPU相比,可以提供 15-30 倍的性能提升,以及 30-80 倍的效率(性能/瓦特)提升。
4.3.6 Xilinx & 深鑒科技
Xilinx 賽靈思是 FPGA 的先行者和領導者,1984 年,賽靈思發明了現場可 編程門陣列 FPGA,作爲半定制化的 ASIC,順應了計算機需求更專業的趨 勢。FPGA 的好處是可編程以及帶來的靈活配置,同時還可以提高整體系 統性能,比單獨開發芯片整個開發周期大爲縮短,但缺點是價格、尺寸等 因素。

Zynq 采用單一芯片即可完成 ADAS 解決方案的開發,SOC平台大幅提升 了性能,便于各種捆綁式應用,能實現不同産品系列間的可擴展性,可幫 助系統廠商加快在環繞視覺、3D 環繞視覺、後視攝像頭、動態校准、行人 檢測、後視車道偏離警告和盲區檢測等 ADAS 應用的開發時間。並且可以 讓 OEM和 Tier1 在平台上添加自己的 IP 以及賽靈思自己的擴展。
(報告來源:國金證券)
獲取報告請登陸未來智庫www.vzkoo.com。
立即登錄請點擊:「鏈接」