科大訊飛
11月10日,國際低資源多語種語音識別競賽OpenASR落下帷幕,科大訊飛-中科大語音及語言信息處理國家工程實驗室(USTC-NELSLIP)聯合團隊(以下簡稱聯合團隊)參加了所有15個語種受限賽道和7個語種非受限賽道,並全部取得第一名的成績!

繼前不久榮獲多語言理解評測XTREME冠軍之後再次奪冠,意味著我們在實現人機交互更自然、人人溝通無障礙的探索征程中又邁出了堅實的一步,也爲中國多語種語音語言技術的國際領先、中國智能制造的全球化奠定了堅實的基礎。
持續進步:我們的領域,不止于大語種
近年來,深度學習技術的進步推動了中英等資源豐富語種的語音識別技術日趨成熟,並獲得廣泛的應用。
相比之下,由于語音數據資源難以標注,語言專家十分稀缺等原因,一些小語種語音識別系統距離實用門檻仍有較大差距。在此背景下,爲探索低資源條件下的語音識別技術,OpenASR比賽應運而生——
OpenASR (Open Automatic Speech Recognition) 是由美國國家標准與技術研究院NIST(National Institute of Standards and Technology)于2020年發起,曆屆參賽團隊衆多,包含加拿大蒙特利爾信息科技研究中心、新加坡科技研究局、騰訊、清華大學等國內外知名研究機構和企業。
今年是第二次舉辦,比賽設置的主要目的是在多語種語音識別任務上探索如何使用少量的數據達到較好的效果,同時考察低資源語音識別基礎算法在多個語種上的推廣性。
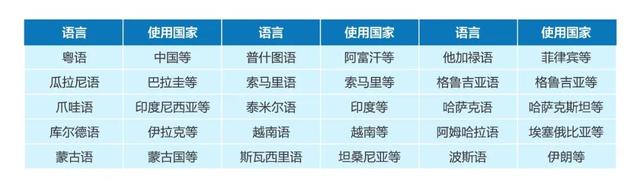
圖1:15個語種信息
本次比賽共包含15個語種,涵蓋受限賽道(Constrained condition)、受限附加賽道(Constrained Plus)和非受限賽道(Unconstrained Condition)。
其中受限賽道爲各參賽單位必選項,每個語種只能使用組委會提供的10小時標注語音識別數據,受限附加賽道在受限賽道的基礎上允許使用開源的預訓練模型,而非受限賽道可以使用組委會提供10小時受限數據之外的數據。
聯合團隊提出了基于語音和文本統一空間表達的半監督語音識別框架(Unified Spatial Representation Semi-supervised ASR,USRS-ASR),得益于該算法良好的推廣性,聯合團隊在受限賽道所有15個語種中全部取得冠軍!同時,爲了評估多語種語音識別實際應用水平,聯合團隊參加了7個語種非受限賽道,也全部取得第一名的成績。
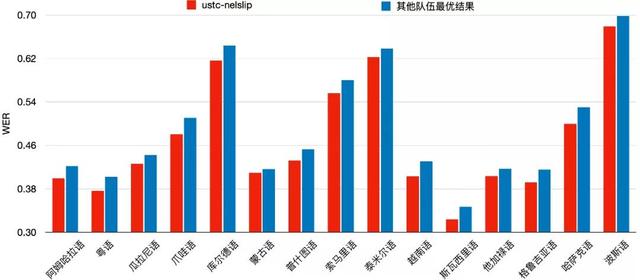
圖2:聯合團隊全部15個語種受限賽道成績

圖3:聯合團隊參加的7個語種非受限賽道成績
一場比賽,22個第一:這是不一般的難頂
比賽中,需要憑借僅有10個小時的低資源語音數據,來開發一套語音識別系統。而參賽團隊面臨的困難還不止于此——
對于低資源語種而言,除了語音數據量較小外,其發音詞典大小、語料豐富性、標注准確度均遠不及常規水平。
更不必說,本次比賽中各個語種數據主要來自電話信道,其對話風格非常自由,且口語化特征十分明顯,都對資源受限條件下的語音識別系統提出了嚴峻的考驗。
在受限賽道上,由于每個語種只有10小時語音數據,如何使用少量文本數據,利用無監督的方法增加語音訓練數據的多樣性至關重要。
聯合團隊創新性地使用了Flow-TTS語音合成進行訓練數據擴增,並使用語音屬性解耦技術保證合成語音的多樣性。
結果顯示,使用上述無監督數據擴增方案,低資源語音識別任務取得穩定、可觀的效果提升。
最後,比賽提交系統在所有15個語種的受限賽道任務上全部拿下冠軍。
而在非受限賽道上,同樣也面臨不小的挑戰。
雖然參賽者可以利用公開數據,但業界公開的語音數據總量仍只有數百小時的量級。另外,語音數據和文本數據的量級差距十分明顯,這對于端到端識別框架來說,弊端更爲明顯。
但聯合團隊相信,難頂也要上。
爲了在端到端統一框架下,充分使用少量語音數據和海量文本數據,聯合團隊提出了基于語音和文本統一空間表達的半監督語音識別框架USRS-ASR。
首先,對于海量文本數據的使用,創新性的設計了文本掩碼語言模型任務、合成數據語音識別兩個目標,兩個任務聯合訓練以充分利用海量無監督文本。
其次,設計了共享語言解碼模塊,實現了語音和文本隱層表達空間的統一。通過該框架,聯合團隊實現了對無監督文本的充分利用,大大緩解了低資源語種的數據稀疏問題。
最終,聯合團隊在提交的7個語種的非受限任務上,全部取得了第一名的成績。
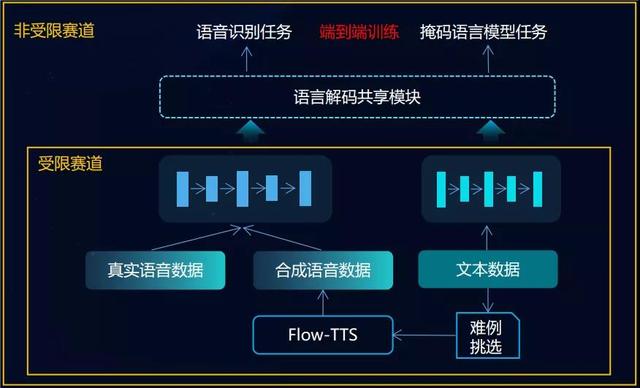
圖4:USRS-ASR框架示意圖
就這樣,咱們的聯合團隊,順利把22項“第一”收入囊中!也充分展現了,在低資源多語種語音識別技術上的地位實力。
技術應用在哪?我們正放眼全球
就在不久前,工信部正式批複同意成立國家智能語音創新中心、國家高端智能化家用電器創新中心,科技創新正不斷引領産業升級。
值得注意的是,在這兩家國家級創新中心依托公司的股東名單中,“科大訊飛”均赫然在列。
持續致力于打造源頭技術創新策源地,科大訊飛正不斷追尋“頂天立地”的産業夢想。
多語種語音語言技術是萬物互聯時代實現人機交互的關鍵技術,也是實現一帶一路語言大互通的基礎技術。
從2014年開始,我們就一直在該方向的源頭技術創新及産業化應用上持續投入,並不斷挑戰實際應用中的技術難題。
經過多年的技術積累,除了中英以外,當前科大訊飛已經具備其他 69種語言的語音識別能力,其中已經有35個語種准確率已經超過90%,並已在新加坡、俄羅斯、印度、日本等國家部署了海外站點,將持續爲海內外開發者提供語音識別、語音合成、機器翻譯、圖文識別等語音語言服務,所有服務均在科大訊飛開放平台開放。
多語種技術也有力支撐了科大訊飛智能硬件産品創新:
在翻譯終端方面,2016年11月我們發布了翻譯智能翻譯硬件,開創了AI翻譯機新品類;
在會議同傳方面,2016年11月推出訊飛聽見多語種字幕同傳系統,目前支持日韓法西等多國語言的同聲傳譯功能;
而在錄音筆方面,2019年5月我們發布了智能錄音筆,並在2020年5月升級支持8種語言轉寫能力,2021年日本版智能錄音筆VOITER系列在日本一經上線,就取得單月超過千台的亮眼成績。
除自身産品以外,科大訊飛也積極爲手機、家電等中國智造國際化提供自主可控解決方案:
在手機、家電方面,爲國內衆多手機廠商提供包括中英在內的多語種語音識別、語音合成能力解決方案,並聯合海爾研發多語種識別系統,助力其拓展東南亞市場;
在車載交互方面,與上汽、長安、奇瑞等國內主要出海汽車提供商,以及俄羅斯汽車工程研究院(NAMI)等海外車廠開展多語種項目合作,覆蓋英語、俄語、日語、泰語、西班牙語、意大利語等數十個語種;
此外,我們的多語種相關技術能力也已經應用于北京2022年冬奧會官方APP(冬奧通),助力冬奧信息溝通無障礙。
圖片
當前,人類已進入“人、機、物”智能互聯時代,智能語音是這個時代最爲關鍵的入口之一,有助于實現語言大互通,建設人類命運共同體。
在國際技術競賽中的獲獎,是我們22年如一日堅持創業初心、持續進行源頭核心技術創新的努力注腳。
我們相信,這些歲月中對于創新的持之以恒,將不斷助力中國語音識別技術參與全球競爭,讓人工智能真正欣欣向榮、蓬勃向上、生生不息。
期待著,在未來中國大地上,人工智能鮮花怒放,而人類語言巴別塔也終將建成。
免責聲明:凡注明爲其它來源的信息均轉自其它平台,目的在于傳遞更多信息,並不代表本站觀點及立場。若有侵權或異議請聯系我們處理。