機器之心分析師網絡
作者:Wu Jiying
編輯:H4O
本文作者結合三篇近期的研究論文,簡述了在增材制造(3D打印)領域中強化學習方法的應用。增材制造通過降低模具成本、減少材料、減少裝配、減少研發周期等優勢來降低企業制造成本,提高生産效益。因此,增材制造代表了生産模式和先進制造技術發展的趨勢。
0 引言
我們在這篇文章中討論一個加工制造領域的問題:增材制造(Additive Manufacturing,AM)。增材制造(Additive Manufacturing,AM)俗稱 3D 打印(3D Printing),是一種融合了計算機輔助設計(Computer-aided design,CAD)、材料加工與成型技術,以數字模型文件爲基礎,通過軟件與數控系統將專用的金屬材料、非金屬材料以及醫用生物材料,按照擠壓、燒結、熔融、光固化、噴射等方式逐層堆積,制造出實體物品的制造技術[1]。相對于傳統的減材制造(Subtractive Manufacturing)技術,增材制造是現代工業範式的一種有效的數字方法,已經在全世界範圍內得到了廣泛的關注。增材制造通過離散 – 堆積使材料逐點逐層累積疊加形成三維實體,具有快速成形、任意成型等特點。
通過利用 3D 計算機輔助設計模型逐層累積疊加制造物體,增材制造具有以下優點[2]:(1)它能創造出具有複雜形狀的産品,例如拓撲優化結構,這些産品利用傳統的鑄造或鍛造工藝是很難實現的;(2)它可以用于生成材料的新特性,如位錯網絡(dislocation networks)[2],這對于學術研究人員來說是非常有意義的;(3)它能夠減少材料浪費,能夠爲工業生成節省成本。不過增材制造本身還存在一些問題,與傳統的通過減材制造技術生成的鑄造和鍛造零件中出現的缺陷不同,AM 零件中存在的缺陷包括:由于缺乏融合和氣體夾帶而産生的孔隙,相對于印刷方向的垂直和平行方向的嚴重各向異性的微觀結構,以及由于高冷卻速度和大溫度梯度的巨大殘余應力而導致産生的變形等。因此,更好地理解粉末的冶金參數、印刷工藝以及 AM 零件的微觀結構和機械性能之間的複雜關系至關重要,也是推廣應用增材制造技術的關鍵。
增材制造涵蓋了多種成形方式,有激光增材制造(Laser Additive Manufacturing,LAM )、電子束增材制造(Electron beam additive manufacturing,EBM)以及電弧增材制造(Wire Arc Additive Manufacture,WAAM)等粉末床熔成型(Powder Bed Fusion ,PBF)方法,還有黏合劑噴射(Binder jetting,BJ)、熔融沉積式 (Fused Deposition Modeling,FDM)材料擠出成型方法等。其中,LAM 是目前應用比較多的工藝,已經應用于一些結構複雜、尺寸較小、表面精度高的零部件打印中。但是,一些定制大尺寸、強度高的零部件不適于用 LAM 成形。針對這些更大型、性能要求更高的零部件,WAAM 則是首選。作爲示例,具體的粉末床熔成型 AM 技術路線分類圖如圖 1 所示[4]。

圖 1. AM 技術分類[4]
我們在這篇文章中,並不具體探討 AM 技術中存在的問題與改進方式,而是聚焦于強化學習(Reinforcement Learning)在 AM 中的應用。近年來,強化學習已經成爲解決相對高維空間中複雜控制場景的一種有效方法,並應用于不同的場景中。其中,深度強化學習(Deep RL,DRL)是一種深度學習方法,它通過收集模擬環境中的經驗和反饋,反複改進最初的隨機控制策略。強化學習算法在解決未知工藝參數和動態變化的條件方面顯示出巨大的優勢,因爲它們能夠利用更豐富的信息來告知決策過程。在增材制造領域中,RL 也可用于構建複雜的控制策略以解決缺陷形成問題,以及多材料複合過程的過程質量監控、學習 – 糾偏、多設備調度等問題。
我們根據三篇近期發表的論文一起來了解增材制造中的強化學習。其中,第一篇文章針對原位工藝學習和控制問題,提出了一種基于模型的強化學習與矯正框架。該框架可以應用于機器人電弧增材制造的過程控制,以使得打印零件具有更好的表面光潔度和更多的近淨形狀(near-net-shape)的輸出[5]。第二篇文章提出了一種提高激光粉末熔床産品質量的深度強化學習方法。通過叠代優化策略網絡以最大化熔化過程中的預期獎勵,可通過近端策略優化(Proximal Policy Optimization,PPO)算法生成能夠減少缺陷形成的控制策略[6]。第三篇文章主要是使用光纖布拉格光柵(fiber Bragg grating,FBG)作爲聲學傳感器對 AM 過程進行現場和實時監測,並使用強化學習(RL)進行數據處理,是 RL 在 AM 現場監測中的應用[7]。
1 基于模型的強化學習與校正框架在機器人電弧增材制造過程控制中的應用[5]

1.1 背景介紹
電弧增材制造(Wire Arc Additive Manufacturing,WAAM)是一種定向能量沉積制造技術,利用運動系統在基體上逐層構建金屬零件。通常情況下,它利用電弧作爲能量來源,電線作爲原料,工業機器人手臂作爲運動系統。最近,這種技術由于其高沉積率和低買飛比(buy-to-fly ratio),在生産近淨形(near-net-shape)的大型金屬零件方面得到了學術界和工業界越來越多的關注。WAAM 通過在水平(多道(multi-bead))和垂直(多層(multi-layer))方向沉積重疊的焊珠來構建 3D 零件,每個沉積層都作爲後續層的基底。因此,重要的是要確保打印層質量足夠高,以便爲後續層的沉積提供一個較好的基底。不規則的層表面通常會導致幾何誤差的累積,隨著打印的垂直推進而導致不理想的凹 / 凸表面,如圖 2 所示。

圖 2. 單道(single-bead)方法通常不夠精確,無法預測 3D 打印的輸出行爲,通常會導致累積誤差(如圖中示出的不規則或凹凸表面光潔度)。另一方面,多層多道(multi-layer multi-bead,MLMB)方法開銷相當大。本文的工作爲多層多道工藝提供了一種經濟有效的方法,即在打印實際零件時通過現場學習不斷改進,從而獲得更好的表面光潔度和更接近近淨形(near-net-shape)的輸出。
爲了解決 MLMB 打印的單道模型不准確性問題,研究人員引入了基于視覺的複雜控制方法,通過實時調節工藝參數和沉積,以提高打印輸出的質量。然而,實施這樣的反饋控制需要開發一個複雜的在線監測系統,由于存在高強度焊接電弧,該系統容易出現噪聲和不准確的情況。此外,還可以通過層間銑削(inter-layer milling)來達到所需的表面平整度。但是這種混合制造方法由于混入了傳統的減材制造工藝,會造成時間和材料的浪費,從而影響了 WAAM 制造工藝本身的成本效益和優勢。
本文提出了一個用于 MLMB 打印的綜合學習校正框架(an integrated learning-correction framework),該框架引入了基于模型的強化學習方法。在該框架中,過程模型被反複學習,隨後被用來補償每一層的平整度誤差,”原位(in situ)” 補償。這樣做的好處是,這個學習框架可以與零件的實際打印結合起來使用(因此是 in situ 的),最大限度地減少了所需的前期訓練時間和材料浪費。作者表示,這項工作是一項初步研究,也是向機器人 WAAM 的原位學習範式邁出的第一步,目的是促進 MLMB 工藝研究,在保證執行和交付制造功能的前提下提高打印質量。
1.2 基于模型的強化學習方法介紹
根據強化學習理論,時間步驟 t 內的 agent 狀態爲 s_t,采取某些動作 a_t 後,會得到獎勵 r_t=r(s_t,a_t),並根據未知的動態函數 f:SxA→S 轉換到下一個狀態 s_t+1。強化學習的目標是在每個時間步驟中學習一個策略,該策略能夠使 agent 采取使未來獎勵總和最大化的動作。上述方法可以在已知和未知環境動態模型的情況下實現,分別稱爲基于模型(model-based)和無模型(model free)的 RL,每一種方法都有自己的優點和缺點。
無模型 RL 的優點是能夠對廣泛的任務進行策略學習,缺點是它需要非常多的樣本數據才能有效。而基于模型的 RL 的樣本效率更高,但需要對環境動態有一定了解。作者分析,由于原位 WAAM 工藝研究的學習框架的目的是要求系統能夠根據最初的幾個樣本學習後就能夠學習到准確的工藝輸入 – 打印輸出關系,因此基于模型的 RL 更適合于本文討論的工作。
在基于模型的 RL 中,使用系統動態模型來進行預測,隨後使用該模型進行動作選擇。令 ^f_θ表征學習到的離散時間動態函數。通過解決優化問題,可以確定未來 H 個時間步驟的動作:
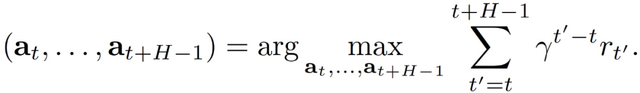
動態函數 ^f_θ可以通過交替收集 N 個新的數據點和使用彙總的數據重新訓練模型來叠代學習,以減弱噪聲,從而提高模型的預測性能。
1.3 綜合學習校正框架介紹
圖 3 給出了本文提出的利用 Kriging 動態函數的 WAAM 過程的綜合學習校正框架。框架中的 agent 表示打印層路徑上的一個離散點(waypoint)。狀態空間 s_t 包括可觀察到的打印輸出行爲(高度、寬度、溫度、聲音等),動作空間 a_t 包括可能的輸入工藝參數(割炬速度、送絲率、噴嘴到基材的距離、割炬角度等)。所有 agents 的共同目標是實現均勻的表面高度。
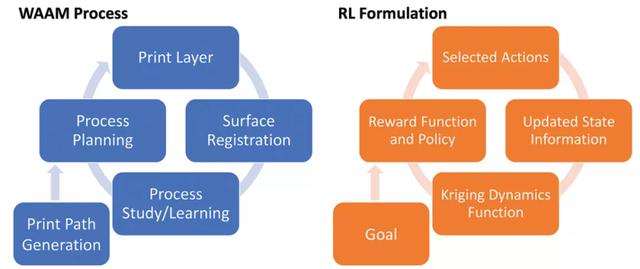
圖 3. 本文所提出的應用于 WAAM 過程的綜合學習矯正框架(左)和相應的 RL 表達式(右)
1.3.1 第一次叠代初始化
對于第一次叠代,通常采取隨機動作並用于初始化第一個訓練數據集。然而,焊接是一種危險的操作,在其可接受的工藝參數之外操作是不安全的。因此,作者將動作空間限制在焊接過程窗口內,即焊接過程參數的下限和上限範圍內,而且這個上限、下限值對于不同的材料是不同的。
1.3.2 學習動態函數
1) 訓練數據集。爲了學習動態函數,需要建立一套訓練數據集。由于打印路徑是一個連續的軌迹,在將該軌迹其離散爲 waypoints 後産生了多個 agents,每個 agent 都有自己的局部狀態,並可以被分配獨立的動作。因此,作者采用了一個針對多 agent 的並行 RL 框架,其中打印路徑上的 waypoints 作爲多個 agents 並行學習相同的任務,並彙集他們的經驗進行訓練更新,從而提高了學習率。訓練數據集後,每個打印層都爲:
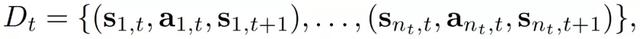
其中,n_t 表示每個時間步驟(層)t 的 agents 的數目。agent 可以在每個時間步驟中進入和離開(即被更新),以適應打印複雜幾何形狀的層間打印路徑的變化。
2)Kriging 動態函數。在過程建模中,神經網絡一直是單道過程研究中常用的方法。作者將學到的動態函數 ^f_θ參數化爲高斯過程回歸(Gaussian Process Regression,GPR)模型,也被稱爲 Kriging 模型,該模型在有噪聲的觀察和小數據集的情況下能夠實現更好的預測。
GPR 模型是根據觀察到的輸入 – 反應對 (X, Y) 構建的。該模型根據輸入空間中的評價點的定位,預測未評價的輸入 X 的反應 Y。假定觀察到的和未觀察到的反應(Y 和 Y),都具有有限維的高斯分布。基于貝葉斯定理,高斯分布 P 表示爲
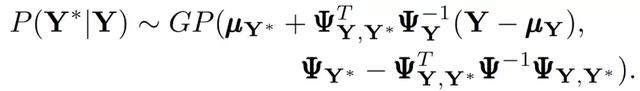
其中,平均值的集合,μ,可以用多項式回歸模型βH 表示,H 是一組設計參數的基礎函數,可以采取任何順序,β是相應的系數向量,其先驗爲高斯β~GP(b,B)。最優預測爲:
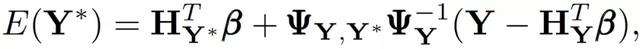
預測方差爲:
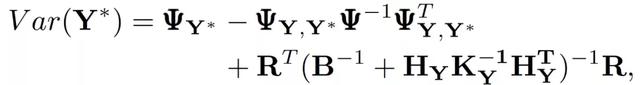
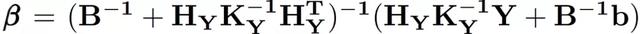
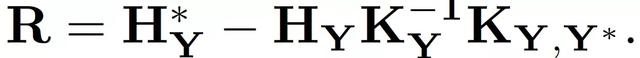
基于 Kriging 模型,我們可以學習一個動態函數,預測在動作 a_t 下 agent 的狀態 s_t 的變化,即:
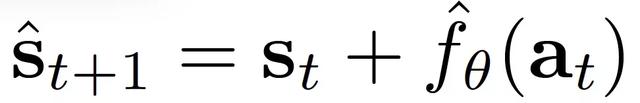
其中,學習過程使用的是累積的訓練數據集 D_T。
1.3.3 目標描述
在強化學習中,目標(goal)定義了 agent 需要達到的狀態。在打印完第 t 層後,通過掃描頂層獲得表面點雲 z_t(x; y)來量化該層的表面質量以及進行必要的修正。爲了更新時間步驟 t+1 的目標,將下一層的打印路徑切片化處理後根據掃描層的最大高度 z_t,max 生成三維 CAD 模型。作者將一個簡單的交替方向策略應用于打印路徑,以減輕電弧撞擊和熄滅的影響[8]。全部 agents 的共同目標是實現統一的表面高度:
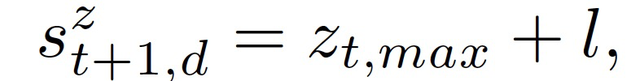
其中,l 表征打印下一層後的預期打印高度增量。
1.3.4 獎勵函數和策略
獎勵函數是這樣制定的:如果 agent 選擇了預計會導致偏離預期目標狀態的動作時,就會受到懲罰。agent 得到的獎勵是來自所學動態函數的預測σ_θ的預測標准偏差的加權 k 值,以鼓勵 agent 進行小範圍內的探索,特別是在最初的學習叠代過程中。每個 agent i 的獎勵函數定義爲:
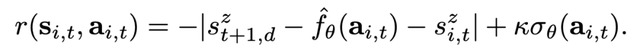
此外,在獎勵函數中也納入 agent 當前的高度狀態(s^z)_i,t,因此鼓勵每個 agent 選擇實現下一個目標狀態的動作,同時糾正自己當前與上一個目標狀態的偏差。根據獎勵函數,每個 agent i 會根據貪婪策略選擇獎勵最大化的行動,即
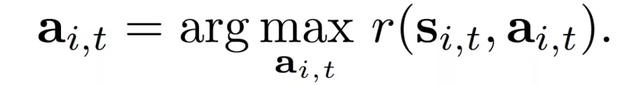
針對本文所述問題中涉及到的非線性動力學函數,作者采用非概率的系統抽樣方法進行求解:從動作窗口的下限開始,以固定的抽樣間隔生成 K 個候選動作集,直到上限結束。學習完成後,使用學到的動力學函數預測相應的狀態、計算獎勵,並選擇具有最高預期獎勵的候選動作集。
Algorithm 1 總結了用于 WAAM 的現場工藝研究和控制的基于模型的並行強化學習方法。在打印一個全新的零件但繼續學習的情況下,第 1 行和第 2 行可以省略。

1.4 實驗環境設置
爲了證明和評估所提出的用于過程研究和控制的綜合學習 – 糾正框架的可行性,作者在新加坡科技大學(SUTD)開發的機器人 WAAM 系統上實施了該框架,如圖 4 所示。該系統包括一個機器人操縱器(ABBIRB 1660ID),一個配備焊槍(Fronius WF 25i RobactaDrive)的焊接電源(Fronius TPS 400i),一個由三個線性軌道(PMI KM4510)組成的笛卡爾坐標機器人,由三個舵機(SmartMotorSM34165DT)驅動,以及一個 2D 激光掃描儀(Micro-Epsilon scan-CONTROL 2910-100)。龍門系統被控制在三維空間中移動線型激光掃描儀,以獲得打印層表面的三維點雲。

圖 4. 新加坡科技設計大學(SUTD)開發的機器人 WAAM 系統
爲了初步評估所提出的學習框架,作者把焊槍速度和送絲速度作爲 agent 的動作,把打印高度作爲觀察到的 agent 狀態,因爲它們是已知的影響打印行爲的關鍵變量和參數,對于調節打印動作至關重要。如圖 5 所示,agent 的局部狀態是從打印表面的激光掃描輸出中獲得的,方法是取距 agent 半徑δ毫米內的打印高度的平均值。
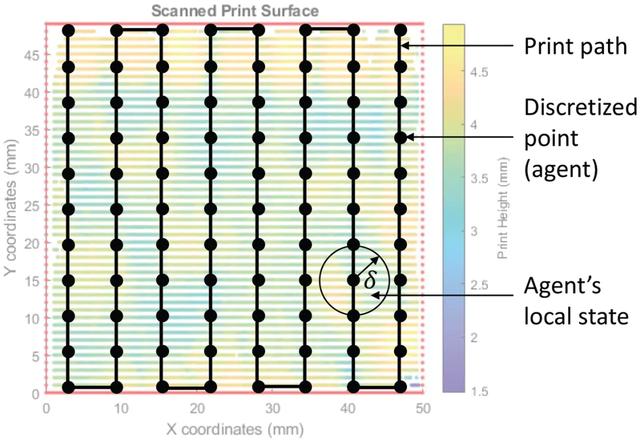
圖 5. 在本文所提出的框架中,該層打印路徑上的每個離散點都作爲一個具有局部狀態和獨立動作的 agent,進行基于模型的並行強化學習並校正。其中,agent 的本地狀態是通過取距離 agent 一個單位內的觀測值的平均值來獲得的。
爲了證明該方法的穩健性和適應性,作者使用兩種不同的金屬,青銅(ERCuNiAl)和不鏽鋼(ER316LSi)進行了實驗。對于青銅材料,打印了兩個尺寸爲 50x50x50mm 的六面體,一個使用所提出的學習校正框架,一個使用經典的單道工藝,以便直接比較所提出的學習框架的效果。對于不鏽鋼材料,作者使用單道工藝打印了一個六面體,以進行結果比較,而使用本文提出的學習校正框架打印了一個更複雜的代表扭鎖銷形狀的零件,其總高度爲 460ms。在整個打印過程中有幾個不同的沉積路徑,最高高度爲 360ms,以證明使用本文提出的學習框架打印具有不同打印路徑的實際零件並獲得更整齊的近淨形(near-net-shape)輸出的可能性。作者在不使用本文所提出框架的情況下,打印了剩余的 100ms 的扭鎖銷,以便在不浪費材料的情況下直接比較輸出。
1.5 實驗結果分析
在打印零件之前,作者先進行了單道研究實驗以獲得工藝參數窗口值,作者使用文獻 [9] 中的方法確定具體的工藝參數以及收集一些數據以初始化所學的動力學函數。圖 6 給出了所進行的單道研究的輸出樣本。對于單道研究,作者使用不同的工藝參數打印了幾個焊珠。然後使用移動的二維激光掃描儀對焊珠進行掃描。首先使用移動平均濾波器對點雲數據進行過濾,並從過濾後的數據的二階導數中提取焊珠的趾部點。在單道研究的基礎上,作者最終爲實驗選擇的工藝窗口是:青銅的割炬速度爲[6, 10]mm/s,送絲速度爲[6, 7]m/min。不鏽鋼的割炬速度爲[7, 13]mm/s,送絲速度爲[3, 5]m/min。

圖 6. 單道研究的照片,與分析的點雲疊加以提取數據
1.5.1 青銅材料
在青銅器實驗中,作者使用單道研究結果推薦的參數打印了一個六面體,而另一個六面體則通過本文所提出的學習框架打印。圖 7 給出了使用基于 agent 的本地狀態的算法選擇的動作樣本。然後,圖 8 顯示了打印零件的最終輸出。從照片中可以看出,利用本文提出的框架生成的打印零件(左邊的六面體)具有更均勻的表面高度,從而生成更接近近淨形的輸出。
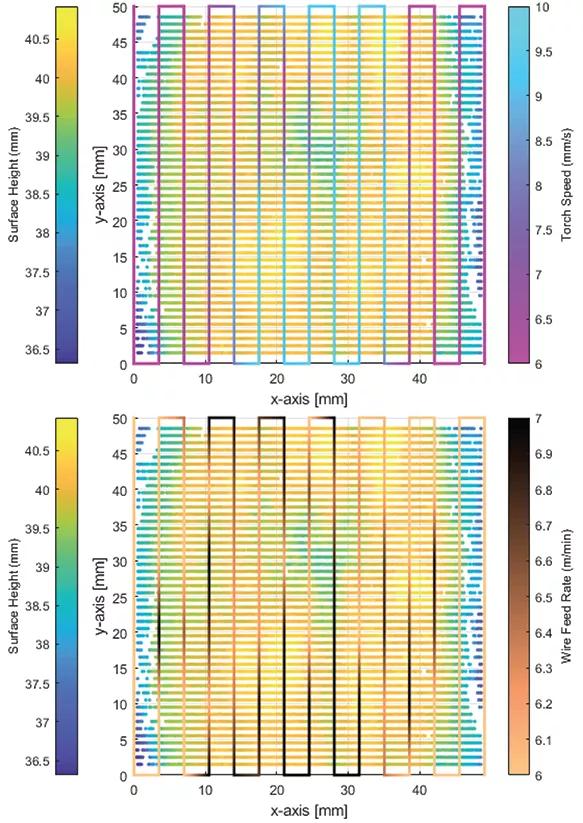
圖 7. 基于 agent 的本地狀態選擇的動作示例

圖 8. 青銅材料的打印輸出:使用本文提出學習框架(左),以及使用單道推薦的參數(右)
1.5.2 不鏽鋼材料
對于不鏽鋼材料,作者使用單道工藝的參數打印了一個六面體,以進行結果比較,同時使用所提出的學習框架打印了一個更複雜的實際零件:一個高度爲 460mm 的扭鎖銷的形狀,最高高度爲 360mm。該材料的剩余 100mm 不使用框架,而是直接比較打印輸出,如圖 9 所示。從照片中可以看出,本文框架打印的結果零件(左)具有平坦的表面,而沒有使用該框架的打印零件(右)則表現出一個深谷,且隨著打印零件高度的增加而不斷累積。

圖 9. 打印輸出不鏽鋼扭鎖銷的零件
1.5.3 定量分析
爲了進一步定量比較打印零件的表面均勻性,利用表面掃描輸出計算每個打印層的表面高度的標准偏差(STD),青銅材料的數值見圖 10,不鏽鋼打印品的數值見圖 11。從圖中可以看出,使用推薦的單道參數打印的層的表面高度的標准偏差隨著兩種材料的打印高度的垂直發展而有增加的趨勢。
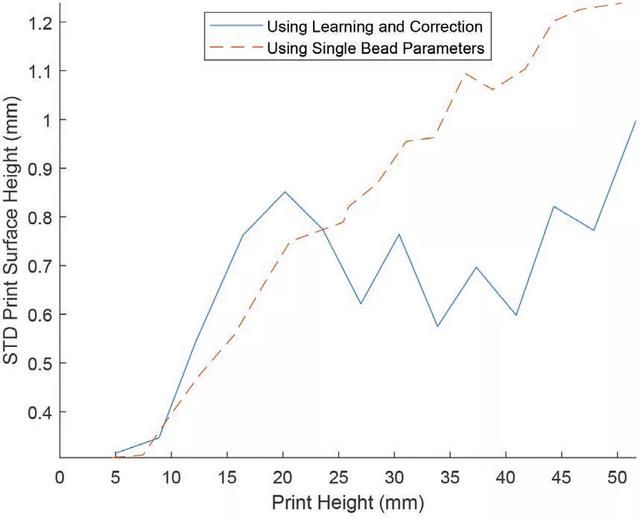
圖 10. 使用學習校正框架打印的青銅材料層表面光潔度的標准偏差(STD)與單道研究的推薦參數之間的比較
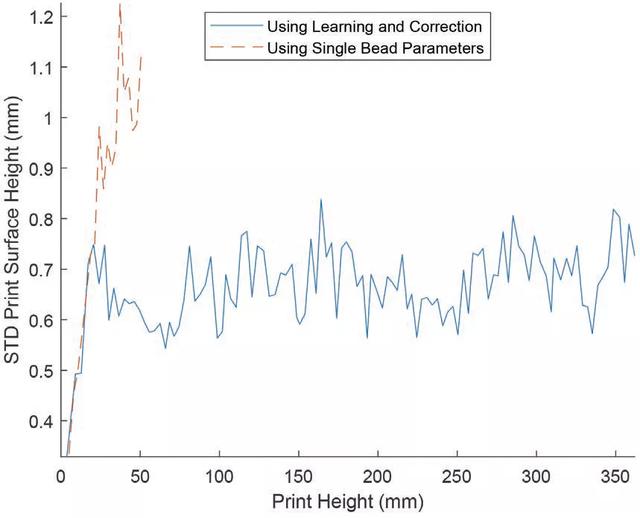
圖 11. 使用學習校正框架打印的不鏽鋼層表面光潔度的標准偏差(STD)與單道工藝推薦參數之間的比較
作者表示,從實驗結果來看,使用本文提出的學習框架獲得的打印輸出表現出更好的表面光潔度和更多的近淨形狀。這證明了本文提出的學習架構在原位工藝學習和控制方面的可行性。這項研究的研究結果爲進行具有成本效益的 MLMB 過程學習提供了可能性。
2 基于深度強化學習的激光粉末床熔的熱控制方法[6]

2.1 工藝背景介紹
本文爲來自 CMU 的研究人員于 2021 年發表在 Additive Manufacturing 中的一篇文章。激光粉末床熔融(Laser Powder Bed Fusion,LPBF)是 AM 的一個子類別,它通過使用熱源將金屬粉末層熔融在一起而創造出熔融産品。粉末床融合(Powder Bed Fusion,PBF)方法已被用于從金屬合金中構建複雜的晶格産品,並在生物醫學和航空航天工業中應用。然而,由于 PBF 生産的零部件容易出現缺陷和低劣的物理性能問題,進而導致特定應用的失敗,因此這些方法的廣泛推廣使用仍面臨著挑戰。這些缺陷包括不良的表面處理、增加的孔隙、分層和開裂,導致低劣的機械性能和不良的幾何一致性等等。以前的實驗研究表明,與掃描過程有關的熔融區的特性是造成成品缺陷的重要因素。熔池可以産生鑰匙孔和缺乏融合的孔隙,而熔化過程中産生的溫度梯度也可以影響形成的微觀結構並導致裂縫。爲了避免在掃描路徑中由于不利的熔池行爲以及過熱而産生的缺陷,最好能夠根據掃描軌迹中不斷變化的溫度分布調整工藝參數。粉末床融合是一個固有的複雜的多尺度過程,發生在粉末和連續尺度的物理效應決定了最終材料的特性。本文工作聚焦于連續尺度的影響,忽略熱源的對流和輻射傳熱,以考慮熱傳導對溫度場的影響。
在傳統的應用中,通常通過引入經典的優化方法制定控制策略以減少機械缺陷的發生。然而,這些方法要求模型的階數較小,並且考慮到計算費用,它們能夠處理的數據量也受到限制。此外,一些統計方法也被用來優化 AM 工藝,如方差分析(analysis of variance)和響應面方法(response surface methodology)等,這些數據驅動的方法由于缺乏對物理環境的感知而受限。當然,陸續已有一些更高級的分析、優化方法不斷引入 LPBF 問題中。
近年來,深度強化學習(Deep Reinforcement Learning,DRL)已經成爲解決相對高維空間中複雜控制場景的一種有效方法。DRL 是一種深度學習方法,通過收集模擬環境的經驗和反饋,對最初的隨機控制策略進行叠代改進。強化學習能夠利用信息生成決策,非常適用于解決 LPBF 的未知工藝參數和動態變化問題。本文提出了一個 DRL 框架,以創建一個複雜的控制策略來解決 AM 缺陷形成的關鍵機制,即在熔化過程中熔池深度的變化。
2.2 方法介紹
2.2.1 仿真描述
在這項工作中,作者考慮了移動熱源在矩形域中的熱傳導,使用 [10] 中開發的框架來提高性能。爲了使強化學習在計算上可行,需將粉床融合的複雜多尺度效應抽象爲材料的連續溫度分布。爲了做到這一點,首先要做如下幾個假設。(1)只考慮傳導的傳熱模式,(2)熱性能與溫度無關,(3) 粉床被建模爲固體連續體,忽略表面粗糙度效應。將該過程建模爲與移動熱源相關的二維傳導,其更新方程如下:
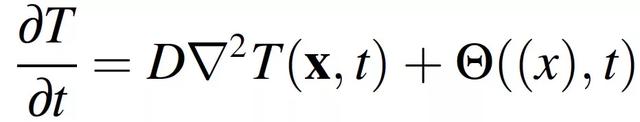
(2.1)
其中,D 表征熱擴散性,Θ根據密度和熱容量對熱源 Q 歸一化。該過程相關參數列于表 1。當公式(2.1)使用無限介質中熱傳導的 Green 函數進行求解時,生成公式(2.2),公式(2.2)具體描述了溫度場 T(x, t)。進一步,公式(2.2)可以被分解爲對溫度解決方案的兩個獨立貢獻,第一項代表熱源的作用,第二項代表熱擴散過程:
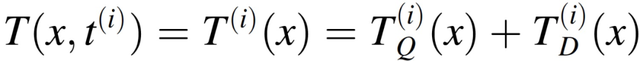
(2.2)
熱源的作用可以用 Eagar-Tsai 的傳導解決方案來模擬,使用圖像法來實現邊界條件:
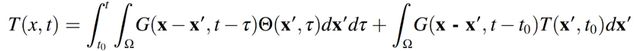
(2.3)
應用如下 Green 函數:
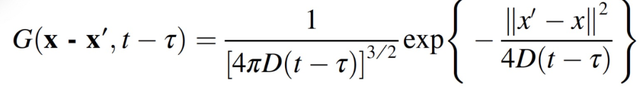
(2.4)
熱源可以被參數化爲一個在板塊表面移動的高斯分布:

(2.5)
其中,A 是材料的吸收率,P 是激光的功率,V 是激光的速度,σ是激光的直徑。由此得到瞬態熱傳導的 Eagar-Tsai 模型(公式(2.4)),表征在 X 方向速度爲 V 的某個Δt 的移動熱源所引起的溫度分布:
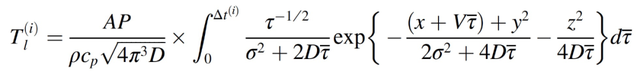
(2.6)
該方法的具體細節由圖 12 所示。在求解過程中,作者引入重複使用存儲線解決方案方法(Repeated Use of Stored Line Solutions Method,RUSLS)解決 Eagar-Tsai (ET)模型存在的較小的線迹問題,並在考慮到問題的幾何形狀而進行修改後,重新利用該解決方案來生成激光器隨後的熱分布。Eagar Tsai 模型的解適用于可適當平移和旋轉的移動點源,以表示從給定位置 (x, y) 開始並以θ角移動的運動(公式(2.5)中從時間 t=0 到時間 t=Δt)。對 T_l(i)進行翻譯和旋轉,以使 (x, y, θ) 與激光在域中的當前位置和方向相匹配。將其添加到現有的溫度分布 T′(x, y)中,形成時間 t 的溫度分布。爲了在現有溫度分布的位置繼續推進激光,首先對時間 t 到時間 t+Δt 的熱擴散進行建模,形成 T′(x, y)_t。然後,再次將 T_l(i)定向到正確的位置,並加入到 T′(x, y)中,形成時間 t+Δt 的 T(x, y)。與標准的有限元分析方法相比,這種處理方式可以在相對較短的時間內叠代許多候選控制策略,從而減少了計算消耗。
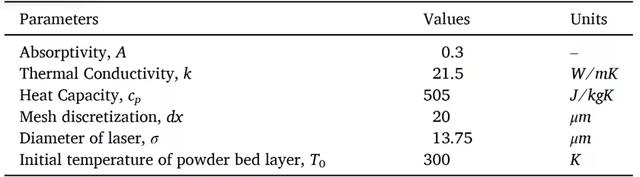
表 1. 熱學和工藝參數
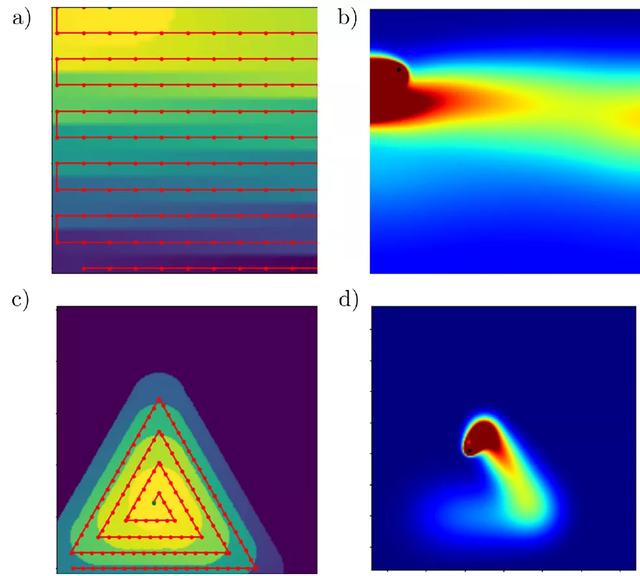
圖 12. 用于評估深度強化學習框架性能的掃描路徑圖示
2.2.2 卷積和邊界條件
在域的邊界附近,需要修改 Eagar-Tsai 模型以生成合適的線解。如果激光距離區域邊界的距離接近 4sqrt(2kΔt/ρc_p),則使用圖像法來說明邊界對熱分布的影響。在計算線解時,在邊界另一側的相同距離處模擬虛擬熱源。因此,可以通過在相關邊界上鏡像法線解來計算邊解和角解,以考慮邊界與規則動力學的交互作用。該虛擬熱源通過修改式(2.6)中的維度積分來實現:
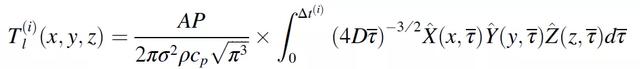
(2.7)
爲了說明板上現有溫度分布的熱擴散曆史,在該方法中將公式(2.2)的第二項作爲卷積運算實現。由于給定向量場的拉普拉斯算子充當局部平均算子,因此可以通過應用卷積濾波器來近似該算子,其權重由高斯分布確定。該操作可被視爲高斯模糊(Gaussian blur),其強度由材料的熱特性、發生擴散的時間尺度和激光強度決定。
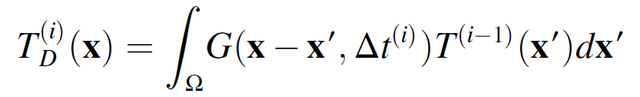
(2.8)
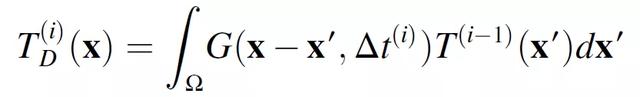
(2.9)
由于卷積濾波器是通過域中每個像素在等距正方形網格中的溫度值的加權平均值來執行的,在卷積濾波器可能延伸到網格邊界的邊界附近必須進行特殊考慮。在邊界條件被限制爲絕熱的情況下,人爲地擴展域卷積濾波器的大小。此擴展中的值作爲邊界附近溫度值的鏡像。在邊界條件被約束爲特定溫度值的情況下,該擴展部分由參考溫度值減去邊界附近溫度分布的鏡像來填充。
熔池深度用作衡量模型成功與否的指標,通過沿 y 軸插值溫度場來計算,並找到表面溫度最高的位置,然後沿 z 軸插值,以找到表面以下溫度處的點,該點首先大于材料的熔化溫度。這是通過使用根查找算法(a root finding algorithm)來實現的,該算法基于當前網格離散化最小化材料溫度和熔點之間的距離。
2.2.3 增強學習框架
在強化學習中,策略根據環境輸入確定要采取的最佳控制動作。這種動作隨後會影響環境,而這種影響通過獎勵來量化。具體來說,狀態空間 S 定義爲環境當前狀態的低維表示,動作空間 A 定義爲 agent 可用的潛在動作,獎勵量化了在前一步驟中爲實現規定目標而采取的動作的效果。一個 episode 定義爲環境的初始狀態和最終狀態之間的時間段。在這種情況下,每個 episode 被視爲激光沿整個掃描路徑的一次穿越,初始狀態爲 t=0,終端狀態出現在路徑的末端。圖 13(a)描述了用于實現 DRL 算法的總體工作流,圖 13(b)和圖 13(c)分別描述了狀態和策略網絡的附加上下文。
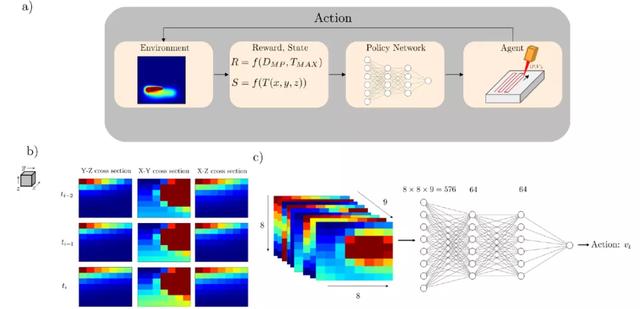
圖 13. 深度強化學習框架
強化學習優化範式的目標是在一個 episode 中獲得最大的獎勵,這是通過生成一個策略π來實現的。策略π根據 agent 的當前狀態選擇一個操作,以便最大化未來預期獎勵。agent 根據策略π完成動作,給定狀態的未來預期收益記爲值函數 V^π(s),而在采取特定動作 a 之後,以及隨後根據策略π完成動作時,給定狀態的未來預期獎勵稱爲動作值函數 Q^π(s,a)。對策略進行叠代優化,以找到使 Q^π(s,a)的值最大化的最優策略π。
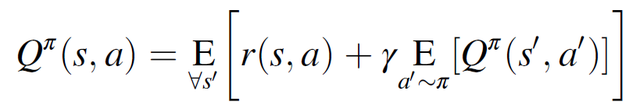
(2.10)

(2.11)
其中 s′是指 agent 在采取動作 a 後的下一個狀態,a′是指在狀態 s′中要采取的動作,r(s,a)是 agent 在采取動作 a 後在狀態 s 中觀察到的獎勵。在公式(2.11)中,狀態空間定義爲特定視圖和方向上的溫度場觀測值。狀態空間作爲 9 個二維熱圖傳遞給策略網絡,該熱圖顯示了激光當前位置周圍的局部溫度分布。具體地說,在激光器周圍定義了一個 160μm×160μm 的區域,在 x-y 橫截面上以激光器爲中心,在 y-z 和 x-z 橫截面上從域表面向下延伸。這組溫度場的三個橫截面快照與之前在事件軌迹期間觀察到的兩組快照相銜接。對溫度值進行白化處理,減去平均值,再除以狀態空間的標准偏差,以逼近數據的標准正態分布。
將行動空間定義爲對激光特性進行的工藝參數更新,這些更新表征改變熔化過程的行爲。對于速度控制方案,提供了激光從軌迹中的一個預定點到下一個點的速度,同時爲基于功率的控制指定了功率。將這些動作調整到 [-1, 1] 範圍內,以避免出現激活函數中常見的梯度消失問題。
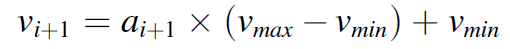
(2.12)
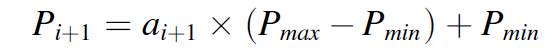
(2.13)
公式(2.12)和(2.13)中,v 和 P 分別表示基于規定動作的速度和功率。獎勵函數量化了控制策略在一個 episode 中的性能,獎勵定義爲目標熔化深度和當前深度之間的絕對誤差。此外,還增加了一個避免 “欺騙(cheating)” 的正則化項,該正則化項的作用是懲罰在 episode 期間觀察到的最小和最大熔融深度之間的距離,從而避免可能導致熔融深度突然峰值的異常策略。
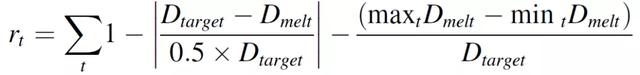
(2.14)
2.2.4 逼近策略優化
爲了優化策略網絡,作者使用了策略梯度法(Policy Gradient methods)的一個子類:近端策略優化(Proximal Policy Optimization,PPO)算法。策略梯度法通過梯度上升概率地搜索最優策略。該策略基于優勢函數 A^π進行優化,A^π表示通過執行特定動作産生的預期獎勵的變化,A^π與從給定狀態開始的一組可能動作的預期未來平均獎勵相關。
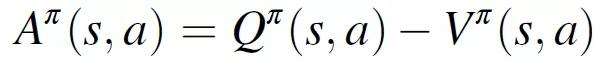
(2.15)
近端策略優化基于新策略利用觀察到的預期獎勵的相對增加來限制梯度上升步驟的最大值。之所以選擇這種方法,是因爲相對于信賴域策略優化(Trust Region Policy Optimization),PPO 在實現上是流線型的,並且與類似的強化學習方法相比,它需要更少的超參數調整和 Actor-Critic 優化。此外,它更適合于連續控制問題。策略梯度方法是 episodic 的,因爲策略網絡在一個 episode 完成後根據累積的獎勵進行更新。在此設置中,每一個 episode 被定義爲激光完成整個掃描路徑的整個過程。本文實現了一個近端策略優化的矢量化版本,其中並行部署多個 agent 以收集經驗流並更新相同的策略網絡。將 PPO 矢量化處理可以減少算法收集必要經驗以學習最佳策略所需的時間。
2.2.5 經驗生成和模型訓練
近端策略優化算法針對 15000 個 episodes 更新進行訓練。策略網絡用于將狀態映射到其對應的行動中,策略網絡由兩個隱藏層組成,其中,每個隱藏層具有 64 個神經元和雙曲正切激活函數。該算法在八個環境中並行訓練,來自這些並行環境的經驗被用于同步更新模型。在預定的軌迹間隔內采取控制措施,水平掃描路徑爲 100μm,三角形掃描路徑爲 50μm,其中,每個間隔定義爲 DRL 框架的單步叠代。表 1 給出了描述介質熱特性的參數以及激光熱源的尺寸。
2.3 實驗分析
2.3.1 速度控制
作者應用上述 PPO 支持的深度強化學習算法來優化單層制造過程中形成的熔池深度。該方法適用于兩種不同的軌迹,一種是激光粉末床聚變工業應用中常用的水平交叉陰影策略(圖 12a),另一種是一系列同心三角形,用于放大次優激光軌迹或粉末床密閉部分發生的過熱現象(圖 12c)。由于 DRL 算法能夠找到隨時間變化的工藝參數的策略,因此作者將每個控制策略的性能與在整個熔煉過程中工藝參數保持不變而産生的熔池深度進行比較。
圖 14 給出了在熔化過程中嚴格控制激光速度時發現的水平交叉陰影軌迹控制策略。在整個軌迹使用相同速度的情況下,軌迹每四分之一間隔處的熔體深度都有明顯的峰值。在這些區域,熔池深度增加多達 20μm。我們觀察到的熔化深度增加是由于在激光改變方向的位置處能量的積累,以及阻止熱能逃逸的絕熱邊界條件。引入 DRL 算法優化控制策略,能夠通過修改軌迹上某些點的速度來限制這些影響。當激光接近域的邊緣時,激光的速度會增加,以減少轉移到域的能量,從而避免由于熱量擴散的能力降低而導致最大熔化深度的峰值。與恒定激光速度的性能相比,學習到的控制策略能夠使熔池深度的變化遠遠小于恒定工藝參數。雖然在熔化過程中熔化深度在某些點上略微低于目標熔化深度,但熔化深度所占據的範圍比在未受控制的情況下觀察到的範圍要窄很多。因此,假設熔池的面積可以與軌迹上任何給定點的熔池深度相關聯,應用速度控制的結果是熔池的面積更加一致,明顯不容易形成鎖眼(keyhole)。圖 15(a)和 16(a)顯示了控制策略所顯示的變化的減少。
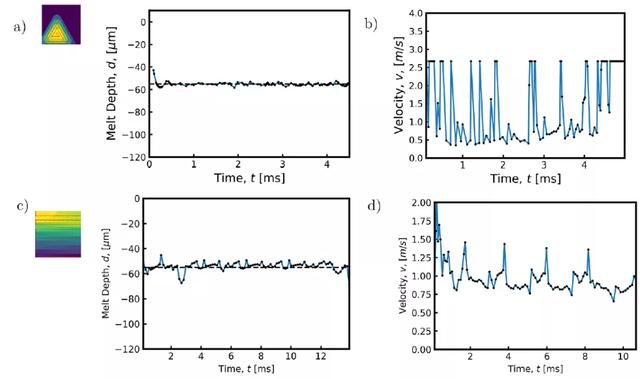
圖 14. (a) 發現的水平交叉陰影掃描路徑的控制策略。當激光在邊界附近反轉方向以減少這些區域的熱能積累時,速度增加。(b) 按照導出的控制策略,同心三角形掃描路徑實現的熔體深度。(c) 根據導出的控制策略,水平交叉陰影掃描路徑達到的熔化深度。(d) 導出了同心三角形路徑的控制策略。當激光改變方向時,速度增加,當激光接近掃描路徑中心時,平均速度逐漸增加
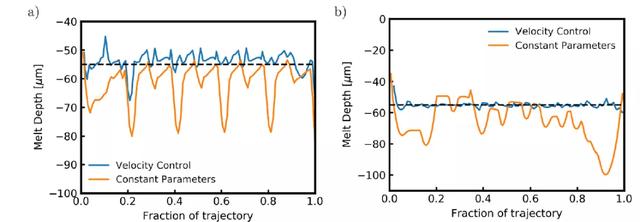
圖 15. (a) 對于水平交叉陰影掃描路徑,由控制策略生成的熔體深度與由恒定速度生成的熔體深度相比較。與在整個熔化過程中采用恒定速度相比,熔池深度更穩定。(b) 控制策略生成的熔體深度與同心三角形掃描路徑恒定速度生成的熔體深度進行比較。與在整個熔化過程中采用恒定速度相比,熔池深度更穩定
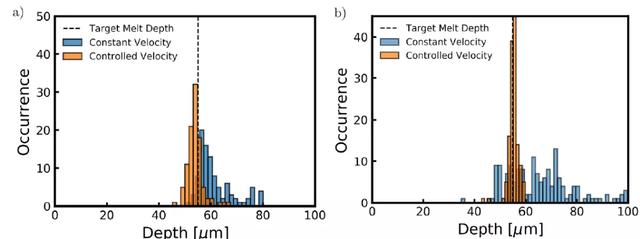
圖 16. (a) 控制策略生成的熔體深度直方圖與水平交叉陰影掃描路徑恒定速度生成的熔體深度直方圖進行比較。熔融過程中産生的熔池深度平均值更接近目標熔池深度,且標准偏差較小。(b) 控制策略生成的熔體深度直方圖,與同心三角形掃描路徑恒定速度生成的熔體深度進行比較。熔融過程中産生的熔池深度平均值更接近目標熔池深度,且標准偏差較小
在同心三角形軌迹上訓練模型時,算法也能通過修改激光接近域中心時的速度來學習合適的策略。在未受控制的情況下,每次激光扭轉方向完成同心三角形軌迹時,熔池深度都會大大增加。此外,在接近軌迹末端時,由于軌迹的重疊段和方向反轉頻率的增加,熱能積聚在軌迹中心。在軌迹的最後 20% 處的熔池深度中也可以看到這種熱能積累,其中,突然增加了 40μm。與恒定工藝參數的情況相比,利用 DRL 學習到的策略能夠避免在軌迹結束時出現的熔體深度的大跳躍。當激光改變行進方向時,速度增加,與水平交叉劃線掃描路徑類似。另外,激光的平均速度在接近掃描路徑的中心時增加,速度保持在可能的最大值以減少過熱現象。圖 15(b)詳細說明了引入控制策略可以保證熔池穩定,圖 16(b)則說明了在穩定的熔池中沒有出現過熱現象。
2.3.2 能量控制
針對能量控制問題,作者通過改變激光的功率來優化熔池的深度。由于激光運動的物理限制,在一個層的運行過程中快速改變速度並不是一定可行的。此外,過高的速度值會在熔池中誘發 Rayleigh 不穩定性,從而導致成球缺陷(balling defects )。因此,作者還研究了用于控制熔池深度的基于功率的控制機制。該方法適用于前面研究的相同軌迹,如圖 12 所示,具有表 1 所示的相同物理參數。如圖 17 和圖 18 所示,當激光通過掃描路徑移動時,agent 能夠成功學習調節激光功率以實現恒定熔池深度的策略。激光功率在拐角處和殘余熱濃度較大的區域降低,使熔池隨時間保持一致。在比較功率控制策略和速度控制策略的性能時,我們可以觀察到水平軌迹的穩定性略有增加(累積誤差減少 68.2% vs 63.8%),三角形軌迹的穩定性略有下降(累積誤差減少 74.6% vs 90.6%)。
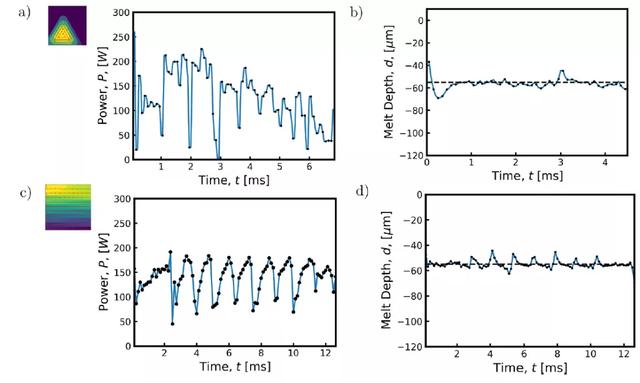
圖 17. (a) 按照導出的控制策略,同心三角形掃描路徑實現的熔體深度。(b) 發現的水平交叉陰影掃描路徑的控制策略。當激光在邊界附近反轉方向以減少這些區域的熱能積累時,功率降低。(c) 導出了同心三角形路徑的控制策略。當激光改變方向時,功率降低,隨著激光接近掃描路徑中心,平均功率也逐漸降低。(d) 根據導出的控制策略,水平交叉陰影掃描路徑達到的熔化深度
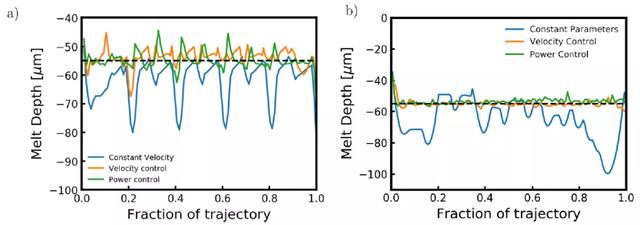
圖 18.(a) 功率控制策略生成的熔深與水平交叉陰影掃描路徑的恒定功率生成的熔深相比。與在整個熔化過程中施加恒定功率和速度相比,熔池深度更穩定。(b) 功率控制策略生成的熔體深度與同心三角形掃描路徑的恒定功率和速度生成的熔體深度相比。與在整個熔化過程中施加恒定功率相比,熔池深度更穩定
本文提出了一種提高激光粉末熔床産品質量的深度強化學習方法。通過叠代優化策略網絡以最大化熔化過程中的預期獎勵,利用 PPO 生成能夠減少缺陷形成的控制策略。通過上述實驗,作者發現有效的控制策略能夠減少模擬中不同掃描路徑下觀察到的熔池變化,進而證明了該方法的有效性。具體來說,基于速度的控制和基于功率的控制方法能夠降低由于激光區域和軌迹的幾何形狀而導致的過熱問題,同時減少了熔池深度的變化。利用觀察熔化過程中特定速度或功率選擇所生成的獎勵,DRL 的策略能夠做到在熱量可能積聚的地方增加速度或減少功率,從而降低了缺陷形成的可能性。
3 基于聲頻發射(Acoustic Emission)的 AM 現場質量監測:一種強化學習方法[7]

3.1 方法思路介紹
本文聚焦 AM 領域中的一個技術難題:現場質量監測。盡管 AM 技術擁有很多優勢,但將其應用于大規模生産仍然存在很多問題,其中一個主要的原因是工件之間缺少工藝可再現性和質量保證。因此,人們迫切需要一種可靠的、經濟高效的 AM 現場實時質量監測技術。
AM 質量監測的發展主要集中在三個主要領域:(a)通過高溫計或高速攝像機測量熔池溫度;(b) 工件各層表面圖像分析;(c) 整個工件的 x 射線相襯成像(x-ray phase-contrast imaging,XPCI)和 / 或 x 射線計算機斷層掃描(xray computed tomography,XCT)。上述每種技術都存在限制其大規模生産適用性的缺點。首先,熔體池的溫度測量僅限于熔體表面,沒有關于整個深度內複雜液體運動和熱量分布的信息。其次,圖像處理方法在生成整個層後評估質量,並且只能檢測正在構建的層表面的缺陷,並不能檢測熔池內産生的缺陷,如氣孔。再次,兩種 x 射線方法都是昂貴和耗時的。XPCI 僅能用于實驗室條件下的現場和實時監測,無法應用于實時處理。XCT 只有在工件從造板上移除後才能執行,由于成本高,只能在有限的情況下由行業應用。
本文首次提出了結合聲頻發射(Acoustic Emission,AE)和強化學習(RL)的對粉末床熔融添加劑制造(Powder Bed Fusion Additive Manufacturing,PBFAM)過程進行現場和實時質量監測的方法。AE 能夠捕獲過程的表面下動力學信息(subsurface dynamics of the process),RL 爲一種機器學習方法。AE 的優點是通過實用、經濟高效的硬件能夠實現可靠地監測多種物理現象。
3.2 實驗設置、材料和數據集
作者使用一台工業 ConceptM2 PBFAM 機器來收集 AE 數據集並重現工業環境。Concept M2 配備了一個以連續模式工作的光纖激光器,波長爲 1071nm,光斑直徑爲 90μm,光束質量爲 M^2=1.02。此外,爲了監測在調幅過程中産生的空氣中的 AE 信號,在機器上安裝了一個被稱爲光纖布拉格光柵(fiber Bragg Grating,FBG)的光聲傳感器。使用 CL20ES 不鏽鋼(1.4404/316L)粉末完成 AM 制造,粒度分布範圍爲 10 至 45 μm。實驗制造了一個尺寸爲 10 x 10 x 20 mm^3 的長方體工件。激光功率(P)、孵化距離(h)和加工層厚度(t)在實驗中保持恒定,P = 125 W,h = 0.105 mm,t = 0.03 mm。使用了三種掃描速度 v:800、500 和 300 mm/s,從而産生了三個質量級別(不同的孔隙濃度)。對應的能量密度(E_density)和質量等級爲:(1)800mm/s,50J/mm^3,較差質量 = 1.42±0.85%;(2)500mm/s,79J/mm^3,較高質量 = 0.07±0.02%;(3)300mm/s,132J/mm^3,中等質量 = 0.3±0.18%。利用公式(3.1)計算能量密度,其中,孔隙的濃度是通過光學顯微鏡圖像的視覺檢查從截面上測量的:
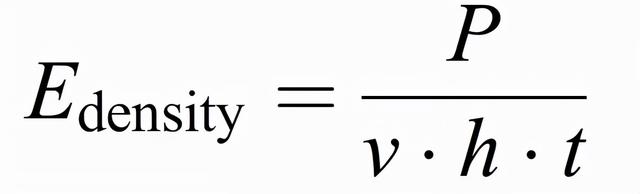
(3.1)
圖 19 給出了制造出來的工件的總體視圖(在取了一小塊來做橫截面之後),以及在材料介質內的孔隙濃度方面的相應質量。在整個制造過程中,使用一個 FBG 來記錄 AE 信號。將光纖光柵安裝在室內,與加工區的距離約爲 20 厘米。爲了提高 FBG 的靈敏度,如圖 20(a)所示,將它放置在纖維的縱軸與聲波垂直的地方。圖 2(b)展示了 FBG read-out 系統的方案。與壓電式傳感器相比,FBG 傳感器有幾個優點。FBG 既可以夾在機器上使用,也可以在空中使用。它較小(總直徑爲 125lm,長度爲 1cm),對聲音信號(0-3MHz)高度敏感,對灰塵和磁場不敏感,並提供亞納秒級的時間分辨率,因此符合在肮髒和嘈雜環境中的實際應用需求。使用 Vallen(Vallen Gmbh,德國)的專用軟件以 10MHz 的原始采樣率記錄 AE 信號。然後,信號被下采樣爲 1MHz 的采樣率,以適應該過程的動態範圍(0 Hz-200 kHz)。然後根據質量水平對 AM 過程中記錄的 AE 信號進行分類。

圖 19. (a)用三種孔隙度含量生産的測試工件;(b-d)各區域的典型光鏡橫截面圖像
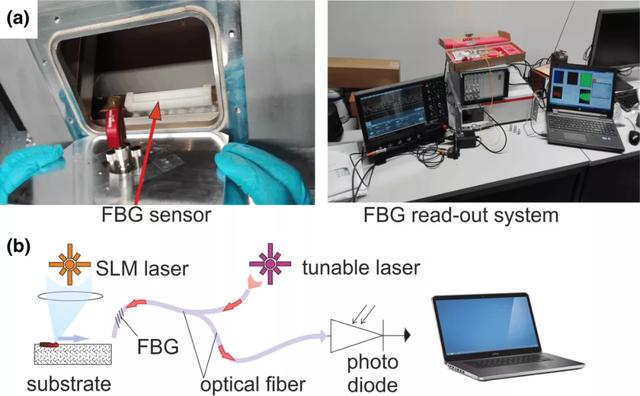
圖 20. (a) AM 室內的 FBG 位置圖,室內面板上有光學真空電極(optical feedthrough)(左)和 FBG read-out 系統(右);(b) FBG read-out 系統方案
3.3 數據處理
本文具體研究強化學習(RL)對 AM 質量監測問題的適用性。本文采用了 Silver 和 Huang 的 RL 實現方法[11],這是因爲作者認爲它很有可能用于未來的 AM 質量監測系統。作者引入 RL 的考慮是,AM 過程的特點是複雜的基本物理現象,涉及大量的瞬間事件(加熱、熔化、固化等),每一個都對過程的狀態變化有至關重要的影響。這使得獲取一個詳細的訓練數據集變得非常複雜,對數據打標簽往往非常昂貴和耗時。在這種情況下,RL 可能會需要在極其有限的有監督數據條件下提供聲頻發射信號和檢測到的瞬間事件之間的關聯信息。
將所有收集到的信號分成獨立的數據集,每個單獨的模式的時間跨度爲 160ms。從小波包變換中提取了每個模式的相對能量。圖 21 給出一個時間跨度爲 160ms 的 AE 信號的典型示例和相應的小波譜圖。小波譜圖是一個信號的時間 – 頻率域,它包含了窄頻帶在時間上的演變信息。使用小波譜圖的原因有三個。首先,小波譜圖是信號的稀疏表示,與 AE 原始信號相比,減少了分析的輸入數據量。其次,它保持了相同的分類精度。最後,它通過選擇非噪聲頻段來降低噪聲。表 2 給出了不同參數的空間分辨率。將提取的小波譜圖直接輸入 RL 算法。初始總數據集(訓練 + 測試數據集)包括總共 180 個譜圖,平均分布在三個質量等級。
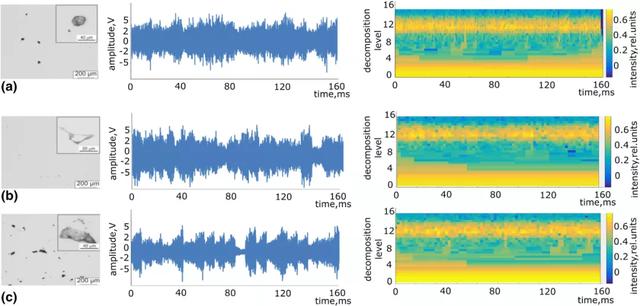
圖 21. (左)典型的光鏡截面圖像,(中)相應的 AE 信號,時間跨度爲 160ms,(右)相應的小波譜圖,生成區域爲(a)300mm/s,132mm^3(中等質量),(b)500mm/s,79mm^3(高質量)和(c)800mm/s,50mm^3(質量差)

表 2. 不同工藝參數下的工藝空間分辨率
3.4 強化學習
RL agent 與給定環境的交互是一個馬爾可夫過程,其特征爲元組(S,A,P,R),其中 S 表示 agent 的狀態空間,A 爲動作空間,其中每個動作 a_i 從狀態 s 轉移到 s^l。P 爲馬爾可夫模型,R 爲獎勵空間。初始狀態設定爲 s_0,RL 算法通過獲得最優獎勵的動作達到目標 s_g。最優獎勵的評價方程爲:
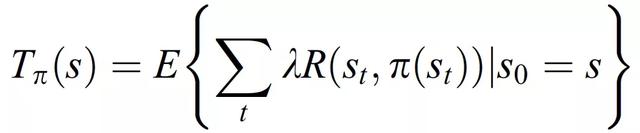
(3.2)
其中,E 爲期望,λ爲折扣系數,π(s_t)爲將狀態映射到動作的策略。最佳策略的搜索是一個叠代過程,因此在第 i 個叠代步驟中,計算 T_(π,i),其中 (π, i) 表征當前策略,根據公式(3.3)計算 Q 值:
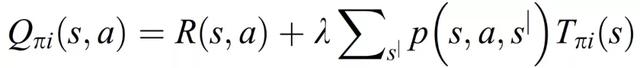
(3.3)
此外,作者利用了 Glover 和 Laguna 的 Tabu 搜索[12]。在這個框架中,通過分析狀態空間的一個限定子集來進行近似最優路徑的搜索,從而在大數據集的情況下減少探索並保留計算時間。針對 multi-class 的問題,作者采用 one-against all 策略。agent 的環境是由小波譜圖創建的,小波譜圖是信號的時頻空間的二維圖。在這種情況下,通過對上述領域的成本構建來尋找最佳策略。
3.5 實驗分析
圖 21 給出三種不同質量的典型光鏡橫截面圖像(左),其對應的 160ms 時間跨度的 AE 信號(中)和其對應的小波譜圖(右)。根據這個圖,可以得出兩個結論。首先,AE 信號是可以區分的。盡管所有 AE 信號的振幅相似,但信噪比似乎隨著掃描速度的增加而增加。其次,在小波譜圖中也可以看到明顯的差異,特別是在 4 到 12 的分解級別中。因此,我們使用小波譜圖,因爲與 AE 原始信號相比,它們具有更高的穩健性。
每個類別都有一個包含 60 個小波譜圖的數據集。這些信號被分成兩個完全獨立的數據集;一個用于訓練,一個用于測試。需要強調的是,在訓練過程中,全部測試數據都是算法未知的。訓練數據集包含 40 個譜圖,而每個類別的其他 20 個譜圖被用來測試 RL 算法。譜圖的選擇是隨機進行的。利用類似蒙特卡洛的方法進行兩百次測試,即對于這兩百次測試中的每一次,用于建立特定訓練和測試數據集的信號都是從最初收集的數據集中隨機選擇的。這種策略允許改變算法的輸入條件,並通過不同的訓練 / 測試組合來研究其性能,以獲得對 AE 信號收集的可靠統計測試。每項測試的准確性被計算爲真陽性的數量除以測試的總數量(如測試數據集中的樣本數量)。總的准確性被計算爲一個平均值,確定爲:
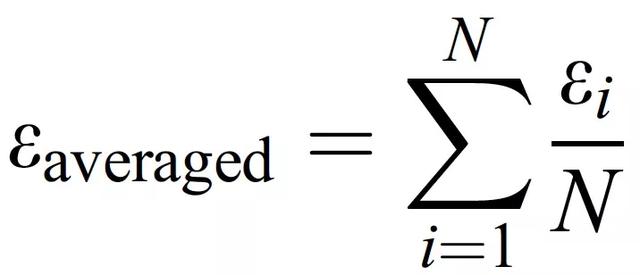
(3.3)
其中,N 等于 200(測試總數)。相比之下,分類誤差的計算方法是用真陰性的數量除以每類測試的總數量。分類測試結果見表 3,分類准確率在 74% 到 82% 之間(見對角線單元格中的黑體數字)。這些結果證明了本文提出的方法對 AM 過程進行質量監測的可行性。由表 3 可以看出,質量差的准確率最高(82%),其次是中等質量(79%)和高質量(74%)。此外,對分類誤差結構的分析可以根據表 3 中的非對角線行進行評估。從統計學上看,表中的誤差結構恢複了來自預定的質量類別的不同特征之間的重疊。表 3 顯示,對于較差質量和中等質量,激光掃描速度差異較小的類之間的錯誤分類誤差較大(反之亦然)。因此,對于具有中等激光掃描速度(500mm/s)的高質量,錯誤分類誤差也大約在中等質量(12%)和差質量(14%)之間平分。同時,中等質量和較差的質量之間顯示出較少的重疊誤差,因爲它們在激光掃描速度上有較大的差異。

表 3. 不同類別的測試結果(百分比)(行)與真實值(列)的對比
4 小結
我們結合三篇近期的研究論文,簡述了在增材制造(3D 打印)領域中強化學習方法的應用。增材制造通過降低模具成本、減少材料、減少裝配、減少研發周期等優勢來降低企業制造成本,提高生産效益。因此,增材制造代表了生産模式和先進制造技術發展的趨勢。
增材制造也有不同的細分方法,本文介紹了電弧增材制造(Wire Arc Additive Manufacturing,WAAM)、激光粉末床熔融(Laser Powder Bed Fusion,LPBF)以及粉末床熔融添加劑制造(Powder Bed Fusion Additive Manufacturing,PBFAM)三個細分領域中強化學習的應用,主要是對制造過程中的溫度、聲頻等的控制,具體分別爲過程控制的應用和實時監測的應用。強化學習具有根據環境學習控制策略的能力,因此對有標注的數據集要求較低,且通過自學能夠提高對 AM 過程控制的准確度。從我們介紹的三篇文章可以看出,在 AM 中引入強化學習能夠提高增材制造打印零件的質量水平。
增材制造本身由于技術工藝的約束還未能大規模的廣泛推廣使用,而在增材制造中引入強化學習還主要是實驗研究。目前看,在增材制造中引入強化學習方法具有節省時間、減少材料浪費等優點,基于這一積極的初步結果,我們相信未來會有越來越多的工作將引入強化學習的框架擴展到全面的增材制造過程學習中。
本文參考引用的文獻:
[1]https://baike.baidu.com/item/%E5%A2%9E%E6%9D%90%E5%88%B6%E9%80%A0/3642267?fr=aladdin
[2] Qi X , Chen G , Li Y , et al. Applying Neural-Network-Based Machine Learning to Additive Manufacturing: Current Applications, Challenges, and Future Perspectives[J]. 工程(英文), 2019, 5(4):9.
[3] Liu L, Ding Q, Zhong Y, Zou J, Wu J, Chiu YL, et al. Dislocation network in additive manufactured steel breaks strength–ductility trade-off. Mater Today 2018;21(4):354–61.
[4] http://www.tsc-xa.com/article/index/id/12/cid/2.
[5] Audelia G. Dharmawan, Yi Xiong, Shaohui Foong, and Gim Song Soh, A Model-Based Reinforcement Learning and Correction Framework for Process Control of Robotic Wire Arc Additive Manufacturing,ICRA 202, 4030-4036.
[6] Ogoke F , Farimani A B . Thermal Control of Laser Powder Bed Fusion Using Deep Reinforcement Learning. Additive Manufacturing, 46(2021).
[7] Wasmer K , Le-Quang T , Meylan B , et al. In Situ Quality Monitoring in AM Using Acoustic Emission: A Reinforcement Learning Approach. Journal of Materials Engineering and Performance, 2019.
[8] J. Xiong, Z. Yin, and W. Zhang, “Forming appearance control of arc striking and extinguishing area in multi-layer single-pass gmawbased additive manufacturing,” The International Journal of Advanced Manufacturing Technology, vol. 87, no. 1-4, pp. 579–586, 2016.
[9] S. Suryakumar, K. Karunakaran, A. Bernard, U. Chandrasekhar, N. Raghavender, and D. Sharma, “Weld bead modeling and process optimization in hybrid layered manufacturing,” Computer-Aided Design, vol. 43, no. 4, pp. 331–344, 2011.
[10] A.J. Wolfer, J. Aires, K. Wheeler, J.-P. Delplanque, A. Rubenchik, A. Anderson, S. Khairallah, Fast solution strategy for transient heat conduction for arbitrary scan paths in additive manufacturing, Addit. Manuf. 30 (2019), 100898.
[11] D. Silver and A. Huang, Mastering the Game of Go with Deep Neural Networks and Tree Search, Nature, 2016, 529, p 484–489. https://doi.org/10.1038/nature16961
[12] F. Glover and M. Laguna, Tabu Search, Kluwer Academic Publishers, 1997
分析師介紹:
本文作者爲Wu Jiying,工學博士,畢業于北京交通大學,曾分別于香港中文大學和香港科技大學擔任助理研究員和研究助理,現從事電子政務領域信息化新技術研究工作。主要研究方向爲模式識別、計算機視覺,愛好科研,希望能保持學習、不斷進步。
關于機器之心全球分析師網絡 Synced Global Analyst Network
機器之心全球分析師網絡是由機器之心發起的全球性人工智能專業知識共享網絡。在過去的四年裏,已有數百名來自全球各地的 AI 領域專業學生學者、工程專家、業務專家,利用自己的學業工作之余的閑暇時間,通過線上分享、專欄解讀、知識庫構建、報告發布、評測及項目咨詢等形式與全球 AI 社區共享自己的研究思路、工程經驗及行業洞察等專業知識,並從中獲得了自身的能力成長、經驗積累及職業發展。